早上起床,睡眼朦胧之时,叫声“小度小度”便能唤醒家里的智能音箱,问问它现在几点,今天天气怎么样;出国在外,也不必精通各国语言,拿着百度共享Wi-Fi 翻译机就能畅行无阻。如今,越来越多搭载AI技术的硬件产品正在“把AI带进生活”,而对于AI在硬件端的落地应用,端侧推理引擎的作用至关重要。
今年8月,百度深度学习平台飞桨(PaddlePaddle)对端侧推理引擎进行全新升级,重磅发布Paddle Lite,旨在推动人工智能应用在端侧更好落地。该推理引擎在多硬件、多平台以及硬件混合调度的支持上更加完备。这是飞桨在Paddle Mobile的基础上进行的一次大规模升级迭代。通过对底层架构设计的改进,拓展性和兼容性等方面实现显著提升。目前,Paddle Lite已经支持了ARM CPU,Mali GPU,Adreno GPU,华为NPU以及FPGA等诸多硬件平台,是目前首个支持华为NPU在线编译的深度学习推理框架。
9月21日,百度AI快车道将在百度科技园举办Paddle Lite专场活动,由百度深度学习技术平台资深架构师、百度深度学习平台系统工程师主讲,详细解读Paddle Lite的技术特点、使用方法和相关应用,同时也会通过实践,实现目标检测模型在手机上的部署,完整体验Paddle Lite在实际业务中的应用。还为学员准备了在FPGA设备上进行蔬菜识别的部署实践,进行实战练习。

注:本活动时候1年及以上相关从业者参与
活动主题:
活动时间:
活动地点:
课程安排:
13:30–14:00 签到,现场交流
14:00–14:15 百度深度学习平台-飞桨全景介绍
14:15–15:00 Paddle Lite深度技术解读及应用
15:00–15:30 Q&A
15:50-16:50 基于Paddle Lite的移动端目标检测部署实战
16:50–18:00 Paddle Lite在Edgeboard(FPGA)上的部署实践
报名链接
https://jinshuju.net/f/XMzyOR?x_field_1=AINLP
关于Paddle Lite
Paddle Lite 的架构有一系列自主研发技术,整合了百度内部多个预测库架构优势能力,并重点增加了多种计算模式(硬件、量化方法、 Data Layout )混合调度的完备性设计,新架构设计如下:
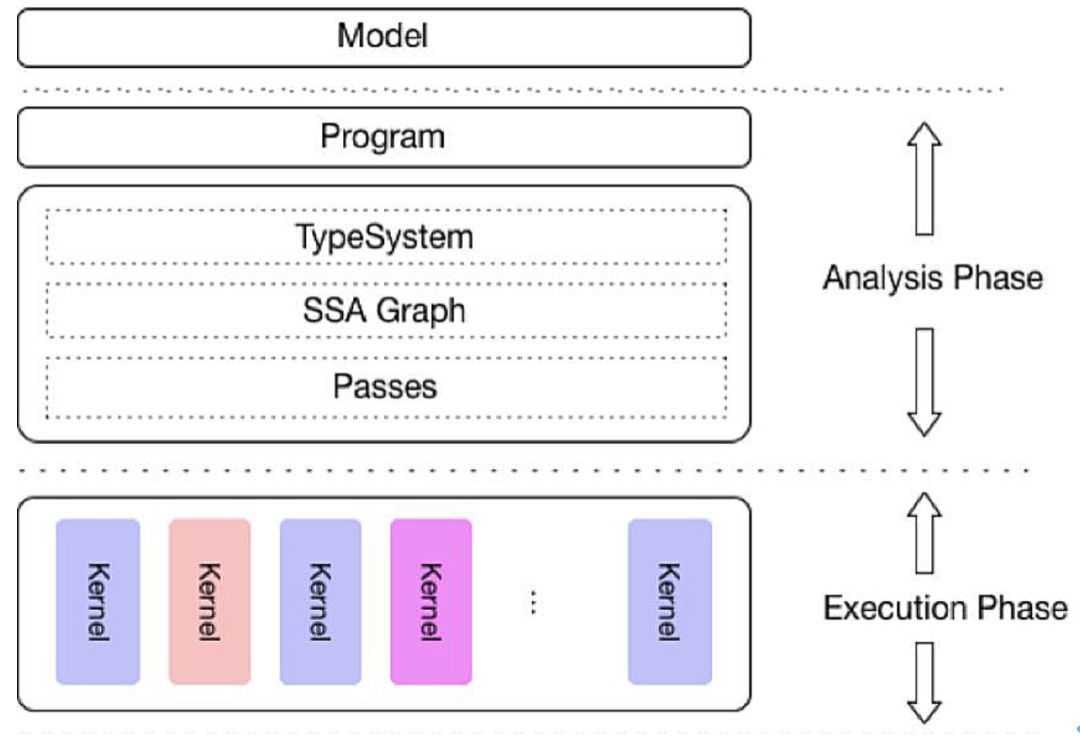
其中最上面一层是模型层,直接接受飞桨训练的模型,通过模型优化工具转化为 NaiveBuffer 特殊格式,以便更好地适应移动端的部署场景。
第二层是程序层,是 operator 序列构成的执行程序。
第三层是一个完整的分析模块,包括了 MIR ( MachineIR ) 相关模块,能够对原有的模型的计算图针对具体的硬件列表进行算子融合、计算裁剪在内的多种优化。
不同于飞桨训练过程中的 IR ( InternalRepresentation ),硬件和执行信息也在这一层加入到分析中。
最底层是执行层,也就是一个 Kernel 序列构成的Runtime Program 。执行层的框架调度框架极低,只涉及到 Kernel 的执行,且可以单独部署,以支持极致的轻量级部署。
整体上来看,不仅着重考虑了对多硬件和平台的支持,而且也强化了多个硬件在一个模型中混合执行的能力、多个层面的性能优化处理,以及对端侧应用的轻量化设计。
关于AI快车道
百度AI快车道——企业深度学习实战营是百度依托自身深厚的深度学习技术实践经验,面向有AI技术需求企业的算法工程师、架构师群体提供的快速应用扶持计划。该计划的学习内容囊括了6套工程实施与深度学习技术落地结合的详细方案,覆盖百度领先的AI技术和业务应用场景的深入剖析,如OCR、精密仪器质检、推荐排序经典场景、遥感图像处理等;源于百度业务实践的深度学习框架飞桨的性能优势、模型优势、生态优势的解读;百度自研和顶级学术会议魁首算法、预训练模型的详细介绍,还有与案例与算法紧密相扣的在线实验,并以“短平快”的课程,进行对业务问题定位、框架及算法的快速应用培训,为更多企业带去深度学习技术和经验分享,并计划在年内于上海、深圳、杭州等多地,支持1000家企业的深度学习技术快速应用。

扫描二维码,或点击阅读原文报名百度AI快车道Paddle Lite专场吧!











