谷歌前不久在 arXiv 上发表论文《
Attention Is All You Need
》,提出一种完全基于 attention 的翻译架构 Transformer,实现了机器翻译的新突破;近日,Github 上的一个项目给出了 Transformer 模型的 TensorFlow 实现,在官方代码公布之前共享了自己的代码。机器之心对该文进行了编译,项目地址见文中。
项目链接:https://github.com/Kyubyong/transformer
需求
项目来由
我试图在论文《Attention Is All You Need》中实现我的想法。该论文的作者声称其模型,即 Transformer,在机器翻译方面的表现优于当前任何的模型;它仅使用 attention,而没有 CNN 和 RNN,这酷极了。论文最后,作者承诺将很快公开代码,但是目前为止并没有。我的这一项目有两个目标,一是我想要全面了解这篇论文,如果不写代码就很难理解论文;二是在官方代码公布之前,与感兴趣的人共享我写的代码。
与原论文的不同
内容,而是要实现论文的核心思想,并作出简单快速的验证。由于这个原因,我的部分代码与原论文有所不同。这些不同之处有:
-
我使用了 IWSLT 2016 de-en 数据集,而不是 wmt 数据集,因为前者更小,且不需要特殊的预处理。
-
为了简化,我用单词而非子单词构建了词表。当然,如果愿意你可以尝试 bpe 或者 word-piece。
-
我将位置编码直接用作了参数,而原文用了一些正弦公式。论文作者之一 Noam 说两种方法都有效,详见:https://www.reddit.com/r/MachineLearning/comments/6gwqiw/r_170603762_attention_is_all_you_need_sota_nmt/
-
论文根据训练步数逐渐调节学习率,我简单地把学习率固定在一个非常小的值 0.0001 上。因为使用小数据集,训练的速度已经足够快(使用单块 GTX 1060 仅需几个小时!!)
文件描述
-
hyperparams.py 包括全部所需的超参数
-
prepro.py 可为源和目标创建词汇文件(vocabulary file)
-
data_load.py 包括装载和批处理数据的相关函数
-
modules.py 拥有全部编码/解码网络的构建模块
-
train.py 包含模型
-
eval.py 是为了进行评估
训练
-
第一步:下载 IWSLT 2016 German–English parallel corpus 并且把它放在 corpora/文件夹
-
第二步:如果必要的话在 hyperparams.py 下调整超参数(hyper parameters)
-
第三步:运行 prepro.py,在 preprocessed 文件下生成词汇文件
-
第四步:运行 train.py 或下载预训练好的文件(pretrained files)
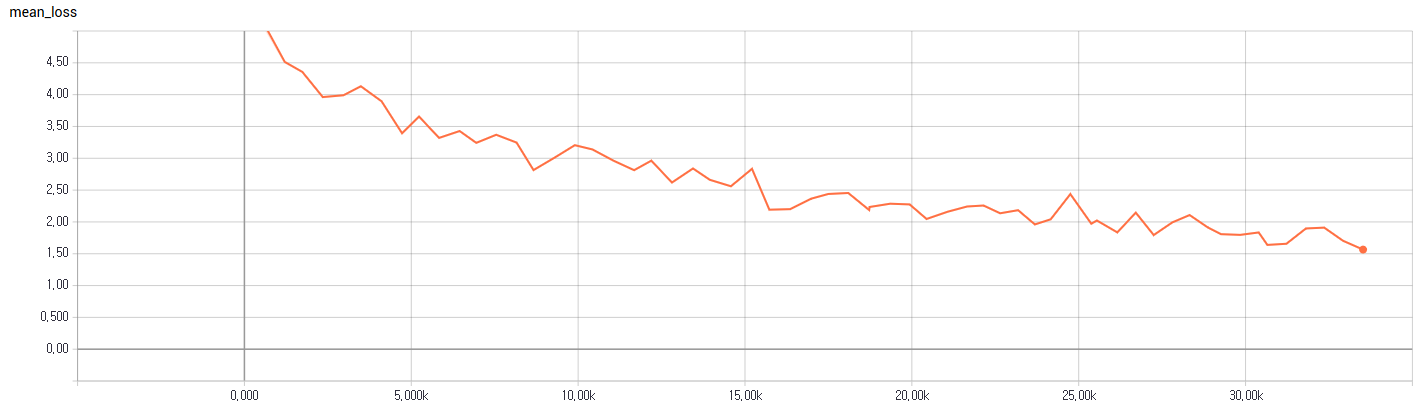
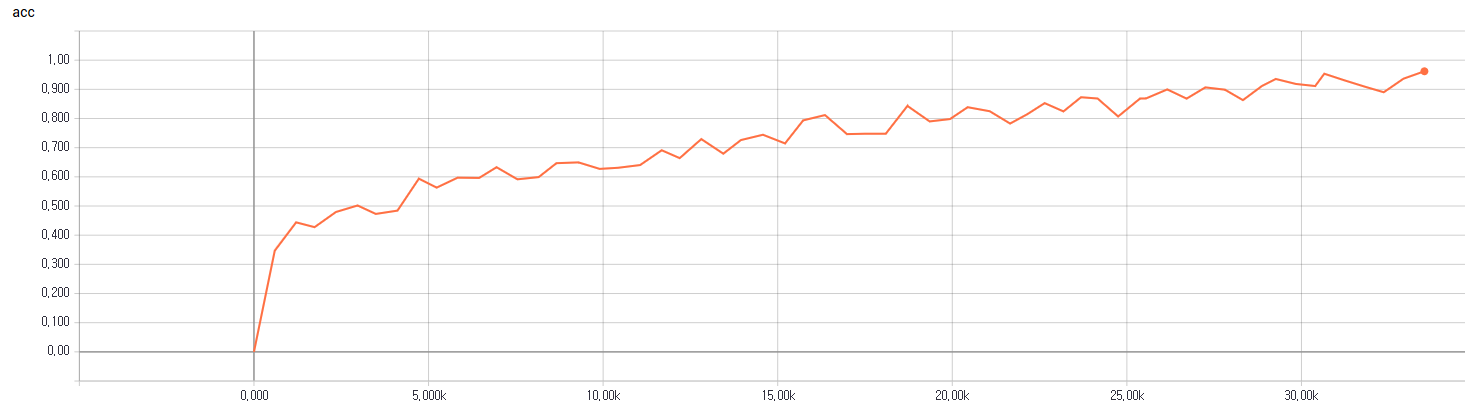
训练损失和精度
训练损失
训练精度
评估
结果
我的 BLEU 得分为 17.14。(我用小数据集、有限的词汇进行训练)一些评估结果如下所示。详见文件夹 results






