split _var, p(",")
//以,分隔开_var
drop _var1
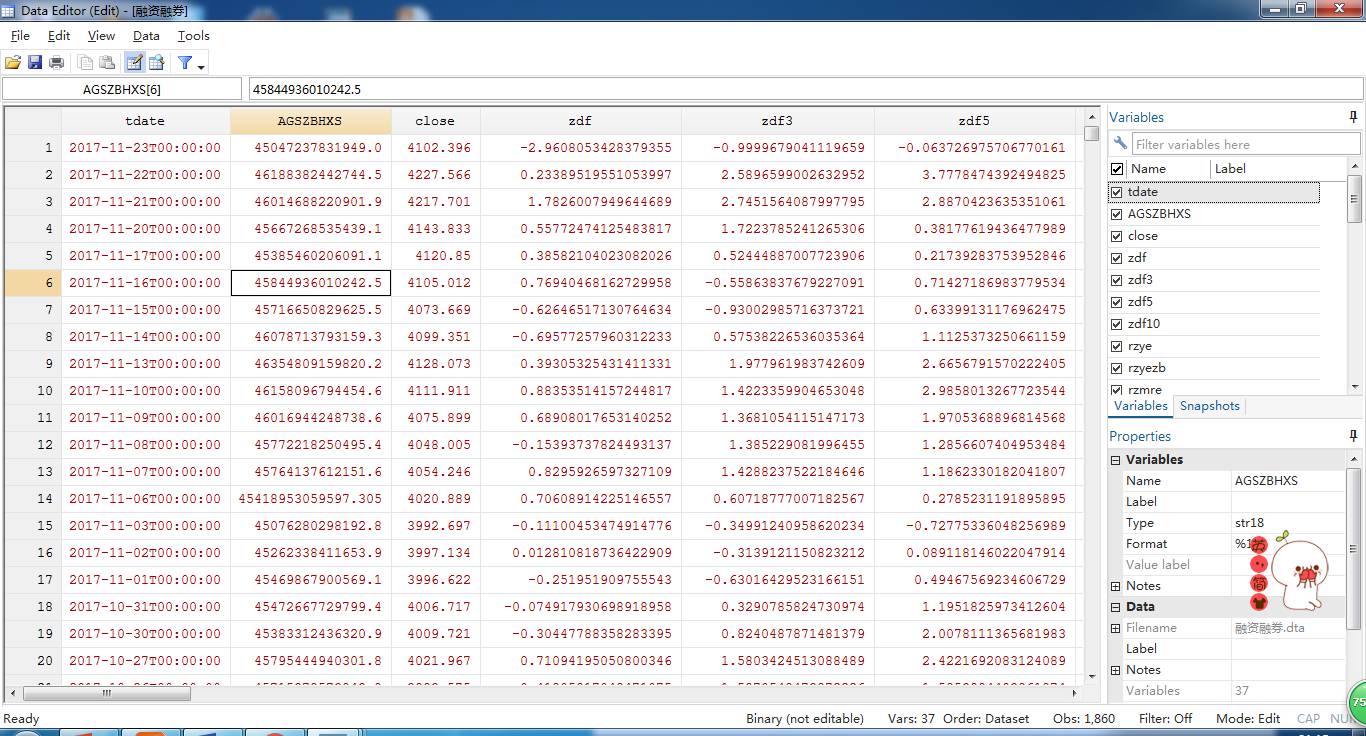
得到数据如下图所示:
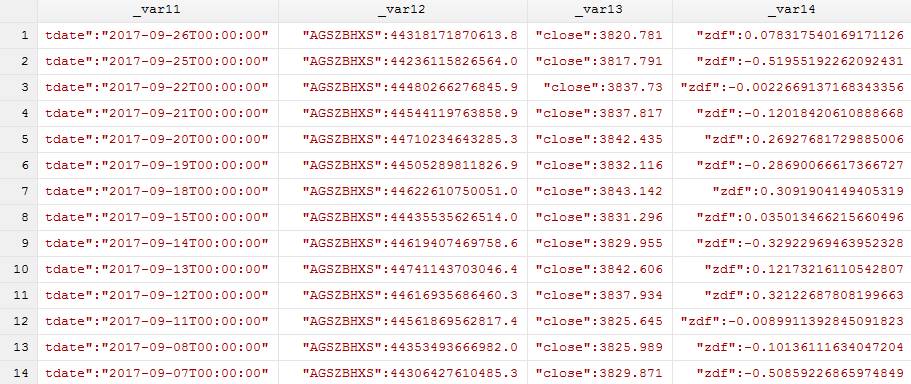
注意分割后的变量有很多个,如果分别对每一个变量进行重命名的话是十分繁琐的,这里我们可以看到,以_var11-_var14为例,对于_var11它的变量名对应的是tdate、_var12的变量名对应为AGSZBHXS…可以发现,每一个变量的名称都是观测值中左边一个双引号(")和右边一个双引号加冒号":之间的内容,但是同时我们发现,_var11这一列的tdate前是没有双引号的,因为我们可以通过正则表达式"*(.+?)":去匹配,其中子表达式(.+?)即为变量的名称,然后我们可以通过
ustrregexs(1)
将其提取出来,并放到一个局部宏中,最后进行重命名,具体程序如下:
foreach c of varlist * {
if ustrregexm(`c',`""*(.+?)":"') local newname = ustrregexs(1)
rename `c' `newname'
replace `newname' = ustrregexra(`newname',`".+?":"*|"|\}"',"")
}
compress
save 1,replace
以上是对单个网页进行处理,下面我们介绍如何获得所有网页上的数据,我们只需对页码循环即可。
命令如下:
clear
cap mkdir "E:\爬虫\东方财富-融资融券"
cd "E:\爬虫\东方财富-融资融券\"
forvalue i = 1(1)38{
copy "http://dcfm.eastmoney.com//EM_MutiSvcExpandInterface/api/js/get?token=70f12f2f4f091e459a279469fe49eca5&st=tdate&sr=-1&p=`i'&ps=50&js=var%20pfcLzjXE={pages:(tp),data:%20(x)}&type=RZRQ_LSTOTAL_NJ&mk_time=1&rt=50437988" temp.txt , replace
clear
set obs 1
gen v = fileread("temp.txt")
split v ,p(`"{""')
drop v v1
sxpose,clear
split _var1,p(,)
drop _var1
foreach c of varlist * {
if ustrregexm(`c',`""*(.+?)":"') local newname = ustrregexs(1)
rename `c' `newname'
replace `newname' = ustrregexra(`newname',`".+?":"*|"|\}"',"")
}
compress
save `i',replace
}
通过对
p=`i’
进行循环,我们能够得到所有页面的数据信息,这样初步的数据处理就结束了,但是我们得到数据是38个dta文件,我们需要将数据整合在一个dta文件中,以便做进一步的数据处理,我们可以输入以下命令:
clear
fs *.dta
foreach c in `r(files)' {
append using `c'
}
duplicates drop
save 融资融券,replace
最后的数据结果如下: