长按扫描二维码关注我
回复“
谷歌
”获取
源代码

Google介绍了Performance,Transformer体系结构,它可以估计具有可证明精度的正则(Softmax)
full-rank-attention Transformers
,但只使用线性(相对于二次)空间和时间复杂度,而不依赖任何先验,如稀疏性或低秩。为了近似Softmax注意内核,Performers使用一种新的快速注意通过 positive Orthogonal 随机特征方法(FAVOR+),这可能是独立的兴趣可伸缩的内核方法。FAVOR+还可用于有效地模拟Softmax以外的核注意力机制。这种代表性的力量是至关重要的,以准确地比较Softmax与其他内核首次在大规模任务,超出常规
Transformer
的范围,并研究最优的注意-内核。
Performers
是完全兼容正则
Transformer
的线性结构,具有很强的理论保证:注意矩阵的无偏或几乎无偏估计、均匀收敛和低估计方差。

研
究者测试了从像素预测到文本模型到蛋白质序列建模的一组丰富的任务。
展示了竞争的结果与其他检查的有效稀疏和密集的注意力方法,展示了新的注意力学习范式的有效性。
下面我们详细描述了FAVOR+机制-Performer主干架构。我们介绍了一种新的估计具有正正交随机特征的Softmax(和高斯)核的方法,FAVOR+利用它对正则(Softmax)注意力进行鲁棒和无偏估计,并说明了FAVOR+如何应用于其他注意内核。


Yannic Kilcher 对该文章进行了解读:
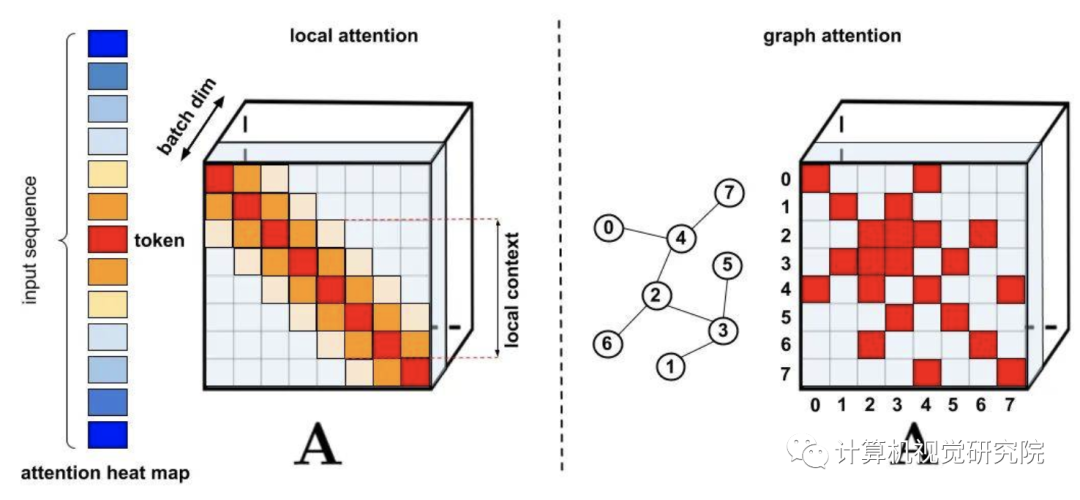
在以往的注意力机制中,分别对应矩阵行与列的query和key输入相乘,通过softmax计算形成一个注意力矩阵,以存储相似度系数。值得注意的是,这种方法不能将query-key生成结果传递给非线性softmax计算之后再将其分解为原始的query和key。然而,将注意力矩阵分解为原始query和key的随机非线性函数的乘积是可以的,即所谓的随机特征(random feature),这样就可以更加高效地对相似度信息进行编码。
标准注意力矩阵包括每一对entry的相似度系数,由query和key上的softmax计算组成,表示为q和k。
常规的softmax注意力可以看作是由指数函数和高斯投影定义的非线性函数的一个特例。在这里我们也可以反向推理,首先实现一些更广义的非线性函数,隐式定义query-key结果中其他类型的相似性度量或核函数。研究者基于早期的核方法(kernel method),将其定义为广义注意力(generalized attention)。尽管对于大多核函数来说,闭式解并不存在,但这一机制仍然可以应用,因为它并不依赖于闭式解。
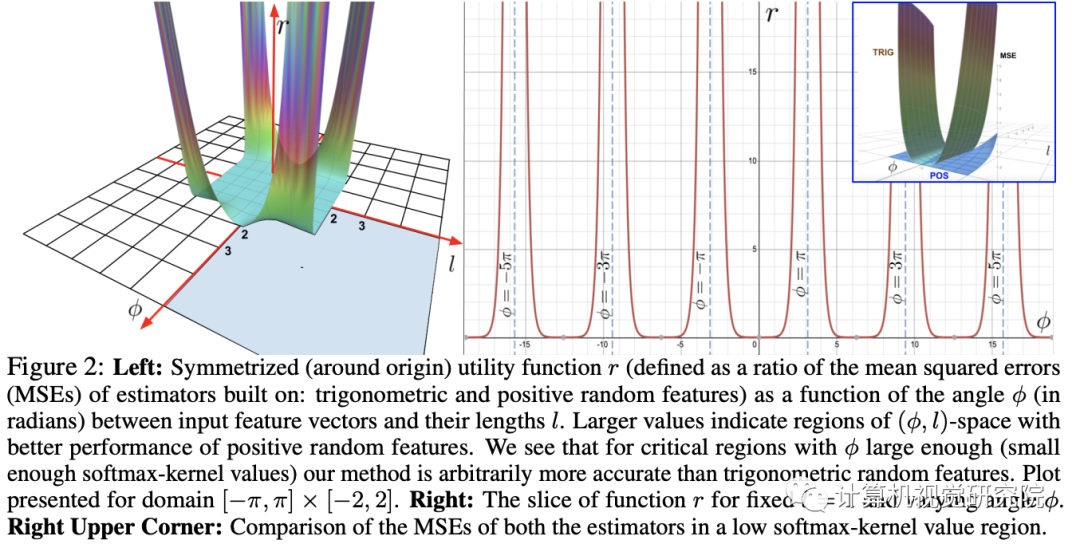
该研究首次证明了,任意注意力矩阵都可以通过随机特征在下游Transformer应用中实现有效地近似。实现这一点的的新机制是使用正随机特征,即原始query和key的正直非线性函数,这对于避免训练过程中的不稳定性至关重要,并实现了对常规softmax注意力的更准确近似。

上文描述的分解允许我们以线性而非二次内存复杂度的方式存储隐式注意力矩阵。我们还可以通过分解获得一个线性时间
注意力机制
。虽然在分解注意力矩阵之后,原始
注意力机制
与具有值输入的存储注意力矩阵相乘以获得最终结果,我们可以重新排列矩阵乘法以近似常
注意力机制
的结果,并且不需要显式地构建二次方大小的注意力矩阵。最终生成了新算法
FAVOR+
。
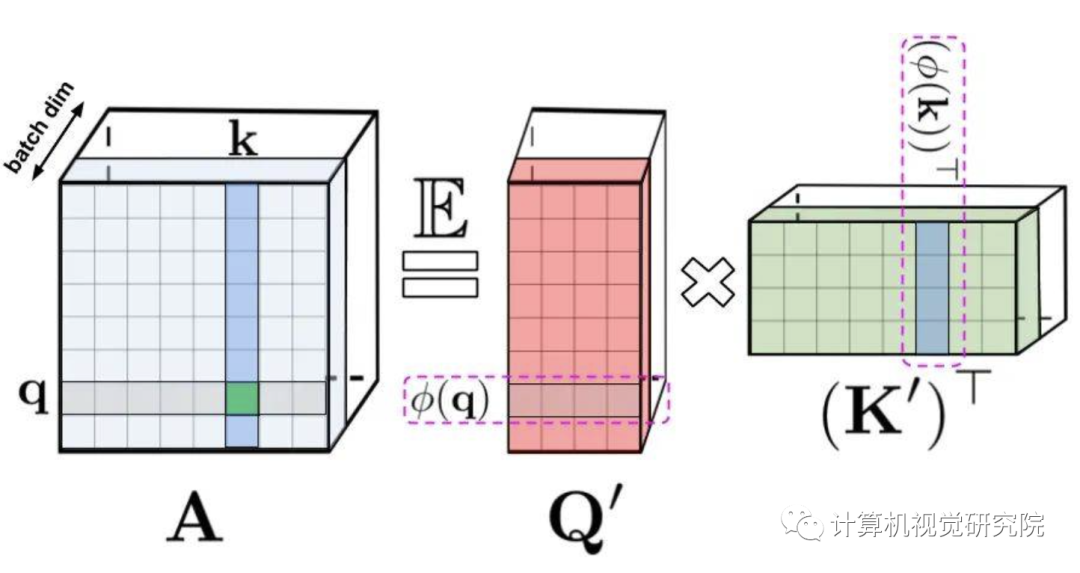
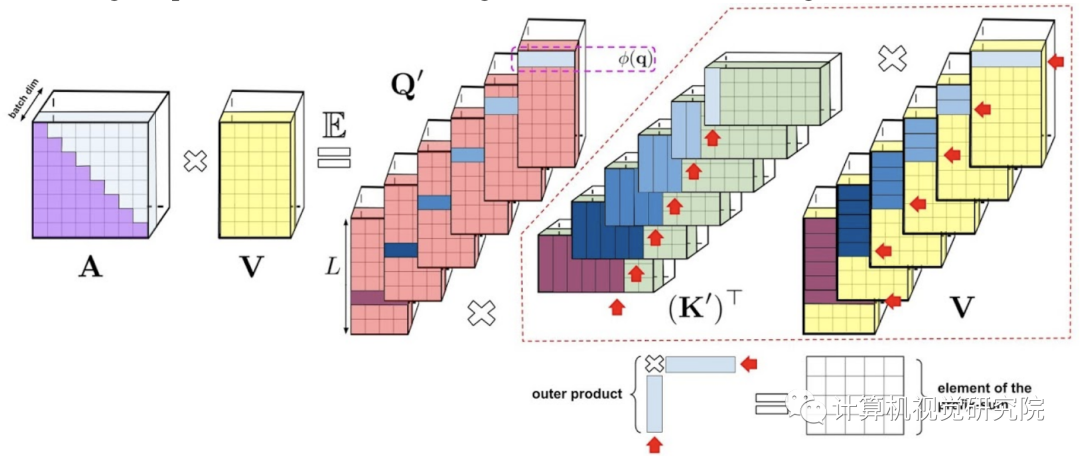
Fig 1
左:标准注意力模块计算,其中通过执行带有矩阵A和值张量V的矩阵乘法来计算最终的预期结果;右:通过解耦低秩分解A中使用的矩阵Q′和K′以及按照虚线框中指示的顺序执行矩阵乘法,研究者获得了一个线性注意力矩阵,同时不用显式地构建A或其近似。
上述分析与双向注意力(即非因果注意力)相关,其中没有past和future的概念。对于输入序列中没有注意前后token的单向(即因果)注意力而言,研究者稍微修改方法以使用前缀和计算(prefix-sum computation),它们只存储矩阵计算的运行总数,而不存储显式的下三角常规注意力矩阵。
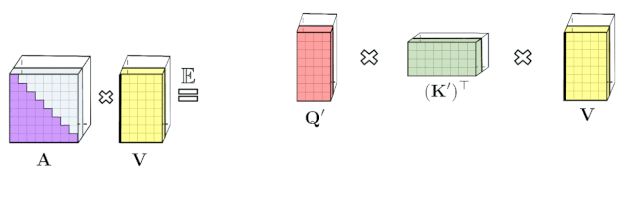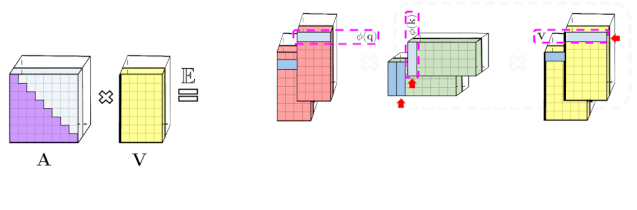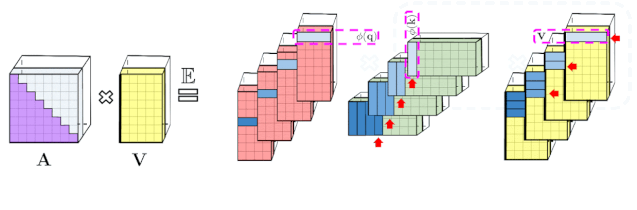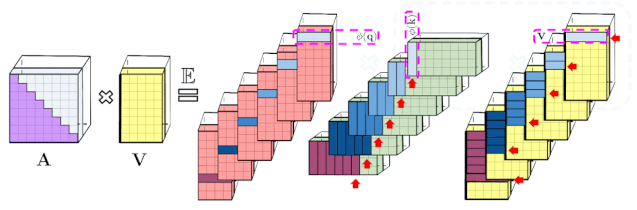
左:标准单向注意力需要mask注意力矩阵以获得其下三角部分;右:LHS 上的无偏近似可以通过前缀和获得,其中用于key和值向量的随机特征图的外积(outer-product)前缀和实现动态构建,并通过query随机特征向量进行左乘计算,以在最终矩阵中获得新行(new row)。

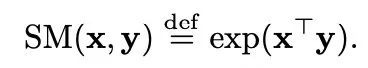


研究者首先对 Performer 的空间和实践复杂度
进行基准测试,结果表明,注意力的加速比和内存减少在实证的角度上近乎最优,也就是说,这非常接近在模型中根本不使用注意力机制
的情况。
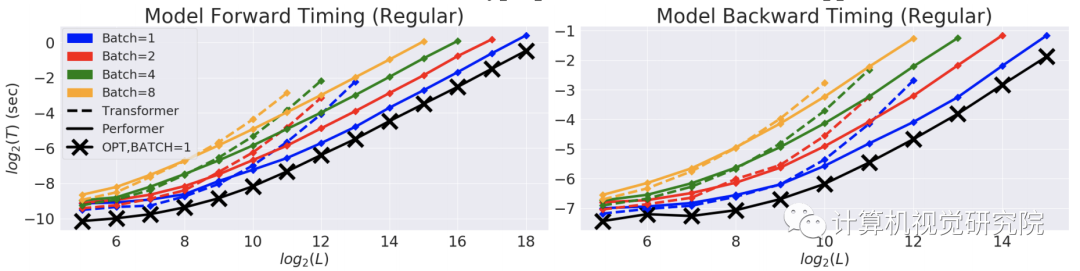
在以时间(T)和长度(L)为度量的双对数坐标轴中,常规Transformer模型的双向timing。
研究者进一步证明,使用无偏softmax近似,该Performer模型在稍微进行微调之后可以向后兼容预训练Transformer模型,从而在提升推理速度的同时降低能耗,并且不需要从头训练预先存在的模型。
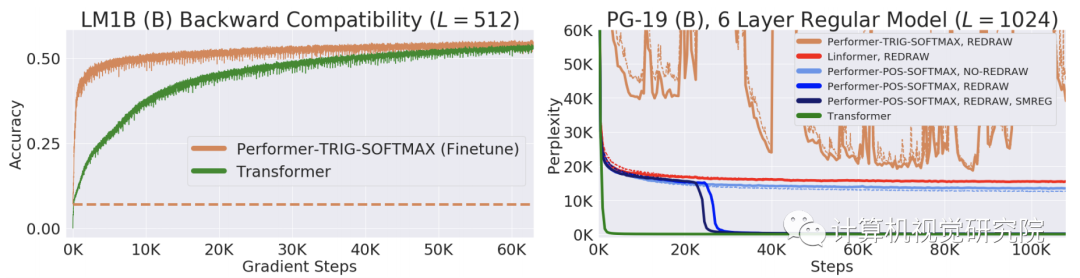
在One Billion Word Benchmark (LM1B) 数据集上,研究者将原始预训练Transformer的权重迁移至Performer模型,使得初始非零准确度为0.07(橙色虚线)。但在微调之后,Performer的准确度在很少的梯度步数之后迅速恢复。
蛋白质具有复杂的3D结构,是生命必不可少的拥有特定功能的大分子。和单词一样,蛋白质可以被看做线性序列,每个字符代表一种氨基酸。将Tranformers应用于大型未标记的蛋白质序列语料库,生成的模型可用于精确预测折叠功能大分子。正如该研究理论结果所预测的那样,Performer-ReLU在蛋白质序列数据建模方面表现良好,而Performer-Softmax与 Transformer性能相媲美。
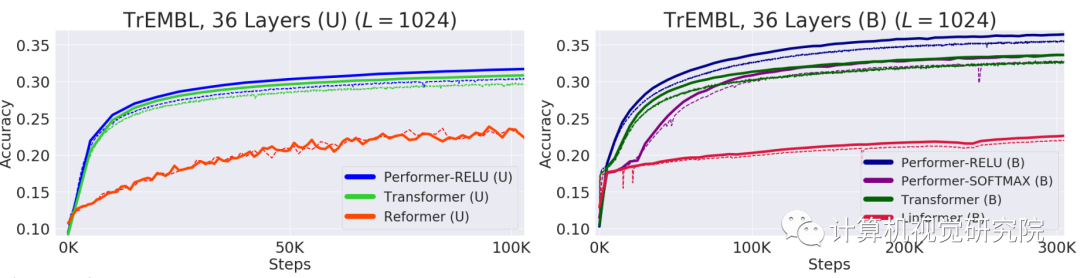
下面可视化一个蛋白质Performer 型,该模型使用基于ReLU的近似注意力机制
进行训练。研究者发现,Performer的密集注意力近似有可能捕捉到跨多个蛋白质序列的全局相互作用。作为概念的证明,研究者在串联蛋白长序列上训练模型,这使得常规的Transformer模型内存过载。但由于具有良好的空间利用效率,Performer不会出现这一问题。
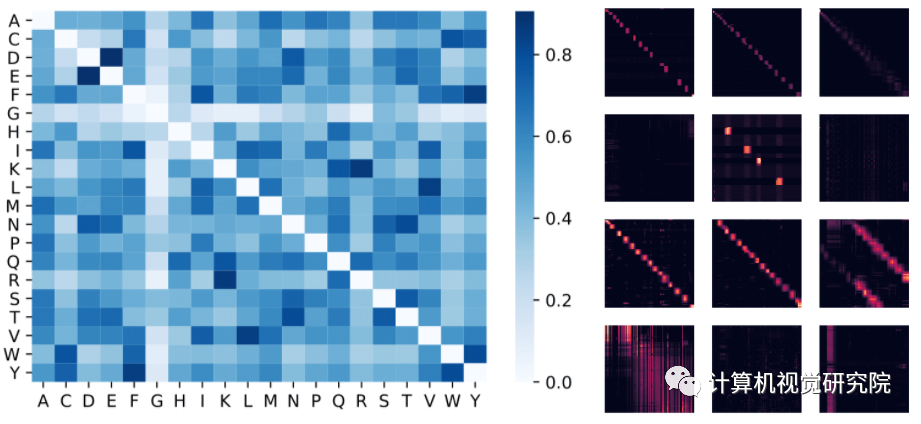
左:从注意力权重估计氨基酸相似性矩阵。该模型可以识别高度相似的氨基酸对,例如 (D,E) 和 (F,Y)。
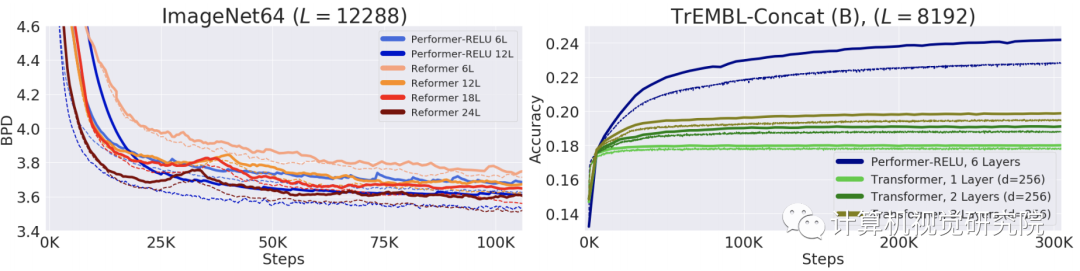
Performer和Transformer在长度为8192的蛋白质序列上的性能
随着Transformer的频繁跨界,越来越多的研究者开始关注其内存占用和计算效率的问题,比
如LambdaResNets。在
那篇文章中,研究者提出了一种名为「lambda」的层,这些层提供了一种捕获输入和一组结构化上下文元素之间长程交互的通用框架。类似的改进还在不断涌现,我们也将持续关注。
MAIN ALGORITHM: FAVOR+

Visual representation of the prefix-sum algorithm for unidirectional attention
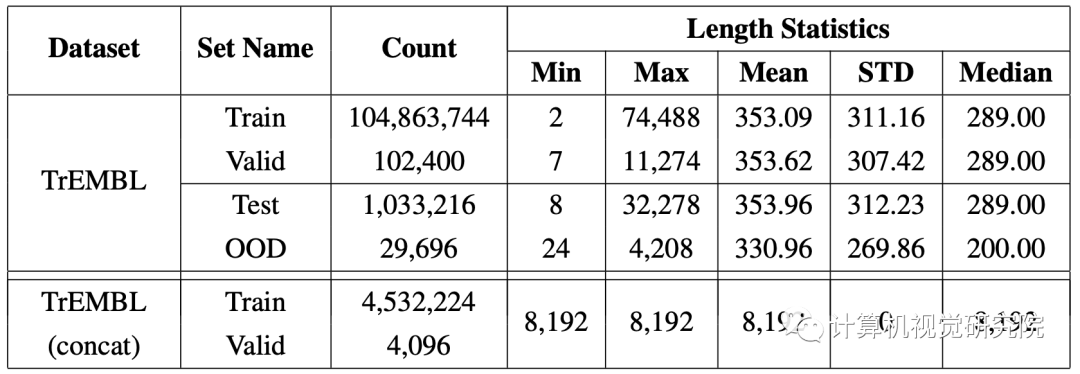
TREMBL DATASET
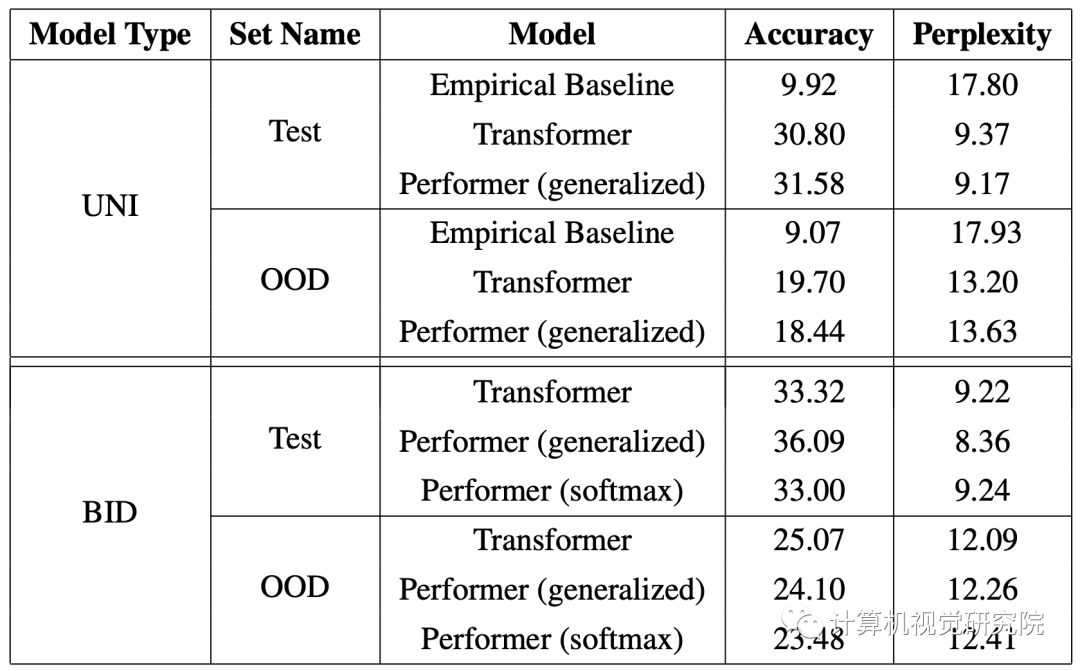
EMPIRICAL BASELINE
TABULAR RESULTS
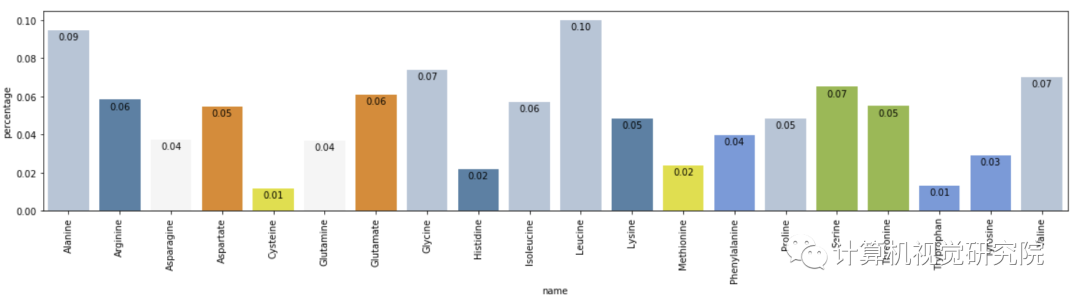
Amino acid similarity
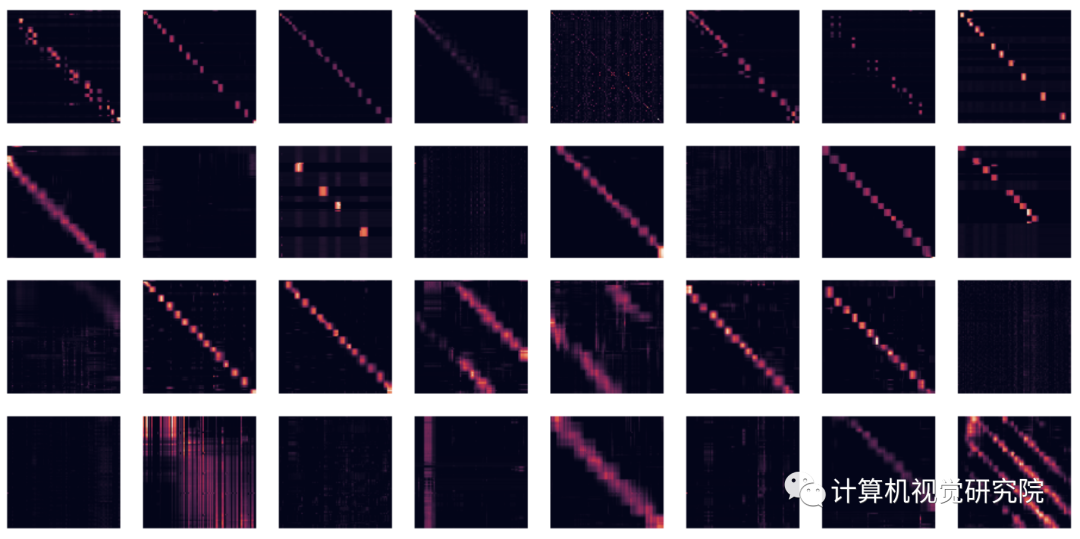
We show the attention matrices for the first 4 layers and all 8 heads (each row is a layer, each column
is head index, each cell contains the attention matrix across the entire BPT1_BOVIN protein sequence). Note
that many heads show a diagonal pattern, where each node attends to its neighbors, and some heads show a
vertical pattern, where each head attends to the same fixed positions.
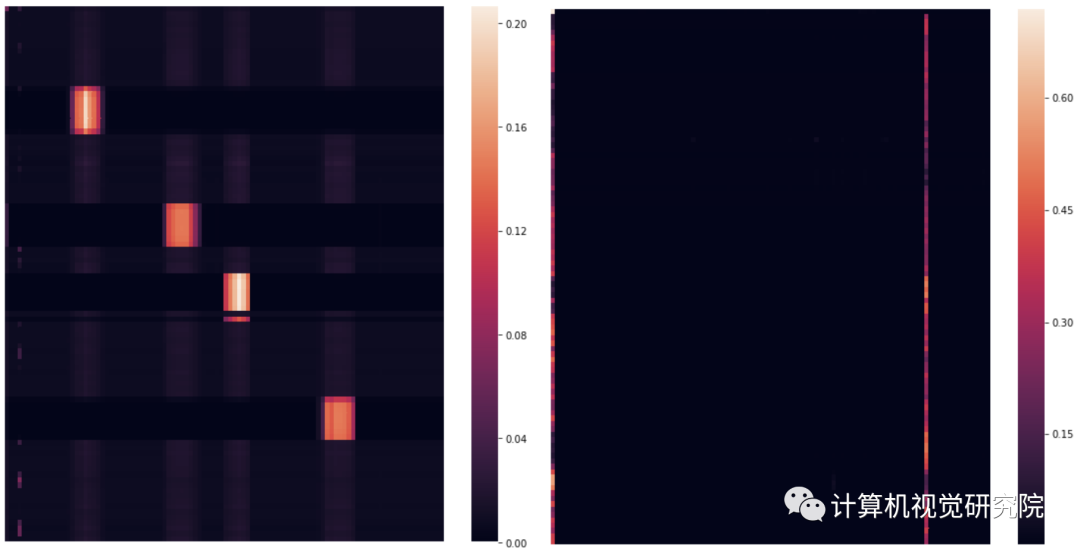
We illustrate in more detail two attention heads. The sub-figures correspond respectively to: (1)
Head 1-2 (second layer, third head), (2) Head 4-1 (fifth layer, second head). Note the block attention in Head 1-2
and the vertical attention (to the start token (‘M’) and the 85th token (‘C’)) in Head 4-1.











