作者:Slav [email protected]
问耕 编译整理
量子位 出品 | 公众号 QbitAI
Macbook这种轻薄的笔记本,是搞不了深度学习的。亚马逊P2云服务,会给堆积越来越多的账单,换个便宜的服务,训练时间又太长……
没办法,已经十多年没用过台式机的我,只能重新着手DIY装机,搭建一套自己的深度学习系统。以下是我的系统搭建和测试过程。
硬件清单
之前,我在AWS亚马逊云服务上的花费是每月70美元(约480元人民币)。按照使用两年计算,我给这套系统的总预算是1700美元(约11650元)。

GPU
肯定得买Nvidia,没有其他选择。买两块还是一块?我想了想,还是先买一个性能更好的,以后有钱了再增加。综合显存、带宽等因素,我最终选了GTX 1080 Ti,跟Titan X相比,性能差不了多少,但价格便宜不少。
CPU
虽然比不上GPU,但CPU也很重要。从预算出发,我选了一颗中端产品英特尔i5 7500。相对便宜,但不会拖慢整个系统。
内存
两条16GB容量的内存,总共是32GB。
硬盘
两块。
一块SSD硬盘运行操作系统和当前数据,我选的是MyDigitalSSD NVMe 480GB。一块速度较慢的2TB容量HDD硬盘存储大的数据集(例如ImageNet)。
主板
为了以后的拓展,我得选能支持两块GTX 1080 Ti的主板。最后的选择是:华硕TUF Z270。
电源
得为GPU何GPU们提供足够的电力供应。英特尔i5 7500功耗是65W,一块1080Ti需要250W(以后还想加一块),所以最后选择了Deepcool 750W Gold PSU。
机箱
我听从朋友的建议,选了Thermaltake N23机箱。只是没有LED灯,伤心。
组装
组装过程按下不表,装机也是个手艺,最后效果如下图所示。

安装软件
提示:如果你想装Windows系统,最好先安装Windows,再装Linux。要不然Windows会搞乱启动分区。
安装Ubuntu
大部分深度学习框架都工作在Linux环境中,所以我选择安装Ubuntu。一个2GB容量的U盘就能搞定安装,如何制作?
https://www.ubuntu.com/download/desktop/create-a-usb-stick-on-macos
https://rufus.akeo.ie/
我写这个教程的时候,Ubuntu 17.04版本刚刚发布,但是我选择了之前的16.04版本,因为老版本的相关文档可能更全一点。另外,我选择的是Ubuntu桌面版本,不过关闭了图形界面X,电脑启动会进入终端模式。
如果需要图形界面,只需要输入:
startx
及时更新
更新可以使用下面这个命令

深度学习堆栈
为了展开深度学习,我们需要如下软件来使用GPU:
-
GPU驱动:让操作系统和显卡可以对话
-
CUDA:能让GPU运行通用目的代码
-
CuDNN:CUDA之上的神经网络加速库
-
深度学习框架:TensorFlow等
安装GPU驱动
最新的驱动,可以参考官网
http://nvidia.com/Download/index.aspx
或者直接使用如下代码安装:

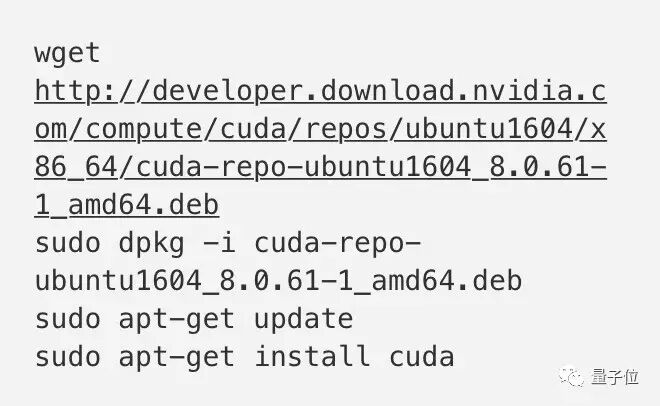
安装CUDA
可以从Nvidia下载CUDA,地址如下:
https://developer.nvidia.com/cuda-downloads
或者直接运行如下的代码:
安装好CUDA之后,下面的代码能把CUDA添加到PATH变量:

现在可以检验一下CUDA装好没有,运行如下代码即可:

删除CUDA或GPU驱动,可以参考如下代码:

安装CuDNN
我用的是CuDNN 5.1,因为最新的TensorFlow不支持CuDNN 6。下载CuDNN,你需要创建一个免费的开发者账号。下载之后,用如下命令安装。

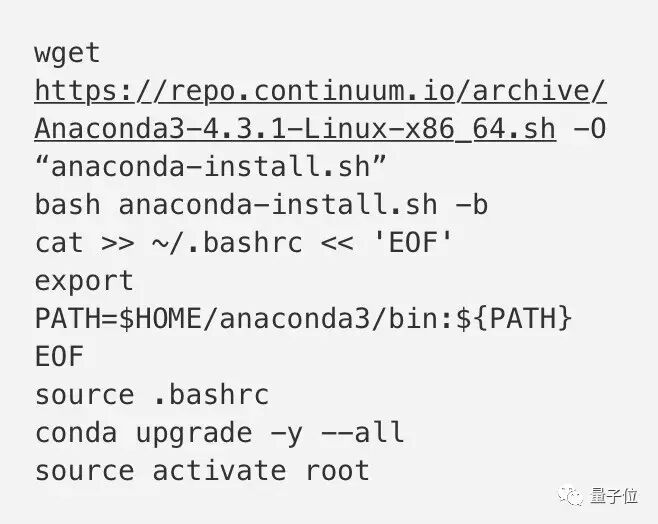
Anaconda
Anaconda是一个很棒的Python软件包管理器,我现在使用了Python 3.6版本,所以对应的使用Anaconda 3版本,安装如下:
TensorFlow
最流行的深度学习框架,安装:

为了检查一下TensorFlow安装好没有,可以运行MNIST看看:
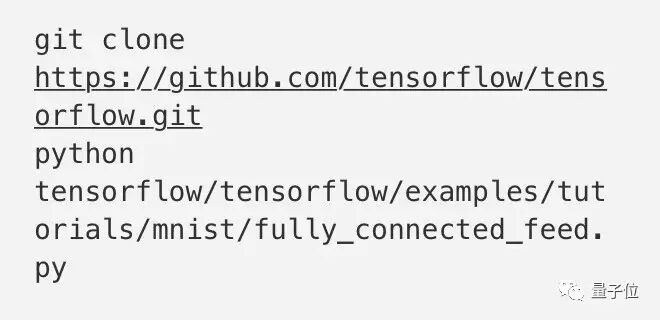
应该能在训练过程中,看到loss的逐渐减少:

Keras
一个高级神经网络框架,安装非常简单:

PyTorch
深度学习框架届的新兵,但也值得推荐,安装命令:

Jupyter notebook
Jupyter是一个交互式的笔记本,随着Anaconda安装,我们要配置和测试一下:

现在打开
http://localhost:8888
,应该就能看到Jupyter的界面。
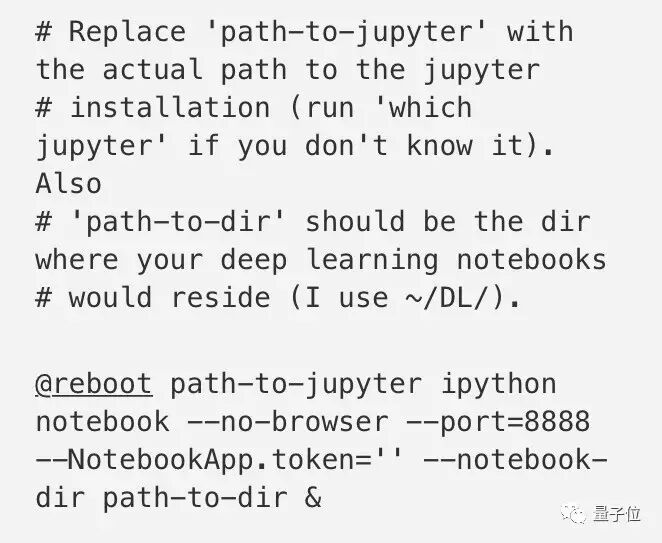
我们可以把Jupyter设置成自动启动,使用crontab来设置。运行
crontab -e
,然后把如下代码添加在最后。
测试
现在基本上准备妥当了,是时候测试一下了。参加此次对比的几个选手是:
-
AWS P2实例GPU(K80)
-
AWS P2虚拟CPU
-
英伟达GTX 1080 Ti
-
英特尔i5 7500
MNIST多层感知器
MNIST数据集由70000手写数字组成。我们在这个数据集上运行了一个使用多层感知器(MLP)的Keras案例,代码地址:
https://github.com/fchollet/keras/blob/master/examples/mnist_mlp.py
MLP的意思是只使用全连接的层,而不用卷积。这个模型在这个数据集上进行了20次训练,实现了超过98%的准确率。
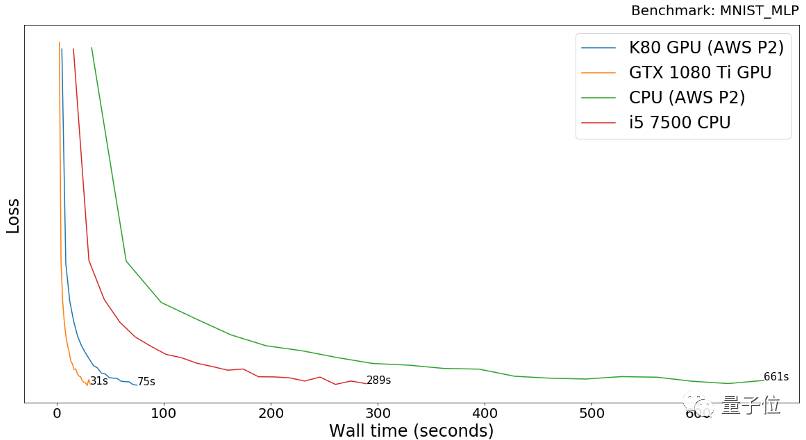
可以看到在训练这个模型时,GTX 1080 Ti比AWS P2 K80快2.4倍,这有点惊人,因为两个显卡的性能应该差不多,我觉得可能是AWS上有降频或者受到虚拟化的影响。










