本文转载自
Draveness
的博客
draveness.me
Follow GitHub:
Draveness
在大多数 iOS 的项目中,Model 层只是一个单纯的数据结构,你可以看到的绝大部分模型都是这样的:
struct User {
enum Gender: String {
case male = "male"
case female = "female"
}
let name: String
let email: String
let age: Int
let gender: Gender
}
模型起到了定义一堆『坑』的作用,只是一个简单的模板,并没有参与到实际的业务逻辑,只是在模型层进行了一层
抽象
,将服务端发回的 JSON 或者说 Dictionary 对象中的字段一一取出并装填到预先定义好的模型中。
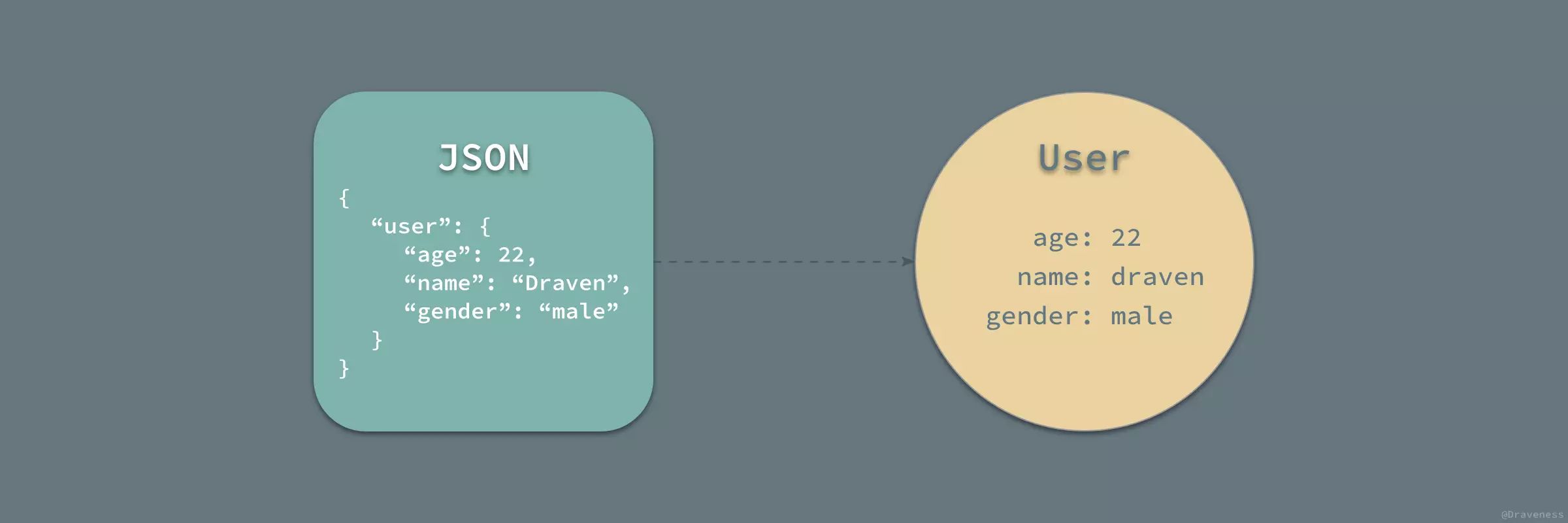
我们可以将这种模型层中提供的对象理解为『即开即用』的 Dictionary 实例;在使用时,可以直接从模型中取出属性,省去了从 Dictionary 中抽出属性以及验证是否合法的过程。
let user = User...
nameLabel.text = user.name
emailLabel.text = user.email
ageLabel.text = "\(user.age)"
genderLabel.text = user.gender.rawValue
使用 Swift 将 Dictionary 转换成模型,在笔者看来其实是一件比较麻烦的事情,主要原因是 Swift 作为一个号称类型安全的语言,有着使用体验非常差的 Optional 特性,从 Dictionary 中取出的值都是不一定存在的,所以如果需要纯手写这个过程其实还是比较麻烦的。
extension User {
init(json: [String: Any]) {
let name = json["name"] as! String
let email = json["email"] as! String
let age = json["age"] as! Int
let gender = Gender(rawValue: json["gender"] as! String)!
self.init(name: name, email: email, age: age, gender: gender)
}
}
这里为 User 模型创建了一个 extension 并写了一个简单的模型转换的初始化方法,当我们从 JSON 对象中取值时,得到的都是 Optional 对象;而在大多数情况下,我们都没有办法直接对 Optional 对象进行操作,这就非常麻烦了。
在 Swift 中遇到无法立即使用的 Optional 对象时,我们可以会使用 ! 默认将字典中取出的值当作非 Optional 处理,但是如果服务端发回的数据为空,这里就会直接崩溃;当然,也可使用更加安全的 if let 对 Optional 对象进行解包(unwrap)。
extension User {
init?(json: [String: Any]) {
if let name = json["name"] as? String,
let email = json["email"] as? String,
let age = json["age"] as? Int,
let genderString = json["gender"] as? String,
let gender = Gender(rawValue: genderString) {
self.init(name: name, email: email, age: age, gender: gender)
}
return nil
}
}
上面的代码看起来非常的丑陋,而正是因为上面的情况在 Swift 中非常常见,所以社区在 Swift 2.0 中引入了 guard 关键字来优化代码的结构。
extension User {
init?(json: [String: Any]) {
guard let name = json["name"] as? String,
let email = json["email"] as? String,
let age = json["age"] as? Int,
let genderString = json["gender"] as? String,
let gender = Gender(rawValue: genderString) else {
return nil
}
self.init(name: name, email: email, age: age, gender: gender)
}
}
不过,上面的代码在笔者看来,并没有什么本质的区别,不过使用 guard 对错误的情况进行提前返回确实是一个非常好的编程习惯。
为什么 Objective-C 中没有这种问题呢?主要原因是在 OC 中所有的对象其实都是 Optional 的,我们也并不在乎对象是否为空,因为在 OC 中
向 nil 对象发送消息并不会造成崩溃,Objective-C 运行时仍然会返回 nil 对象。
这虽然在一些情况下会造成一些问题,比如,当 nil 导致程序发生崩溃时,比较难找到程序中 nil 出现的原始位置,但是却保证了程序的灵活性,笔者更倾向于 Objective-C 中的做法,不过这也就见仁见智了。
OC 作为动态语言,这种设计思路其实还是非常优秀的,它避免了大量由于对象不存在导致无法完成方法调用造成的崩溃;同时,作为开发者,我们往往都不需要考虑 nil 的存在,所以使用 OC 时写出的模型转换的代码都相对好看很多。
// User.h
typedef NS_ENUM(NSUInteger, Gender) {
Male = 0,
Female = 1,
};
@interface User: NSObject
@property (nonatomic, strong) NSString *email;
@property (nonatomic, strong) NSString *name;
@property (nonatomic, assign) NSUInteger age;
@property (nonatomic, assign) Gender gender;
@end
// User.m
@implementation User
- (instancetype)initWithJSON:(NSDictionary *)json {
if (self = [super init]) {
self.email = json[@"email"];
self.name = json[@"name"];
self.age = [json[@"age"] integerValue];
self.gender = [json[@"gender"] integerValue];
}
return self;
}
@end
当然,在 OC 中也有很多优秀的 JSON 转模型的框架,如果我们使用 YYModel 这种开源框架,其实只需要写一个 User 类的定义就可以获得 -yy_modelWithJSON: 等方法来初始化 User 对象:
User *user = [User yy_modelWithJSON:json];
而这也是通过 Objective-C 强大的运行时特性做到的。
除了 YYModel,我们也可以使用 Mantle 等框架在 OC 中解决 JSON 到模型的转换的问题。
从上面的代码,我们可以看出:Objective-C 和 Swift 对于相同功能的处理,却有较大差别的实现。这种情况的出现主要原因是语言的设计思路导致的;Swift 一直鼓吹自己有着较强的安全性,能够写出更加稳定可靠的应用程序,而安全性来自于 Swift 语言的设计哲学;由此看来静态类型、安全和动态类型、元编程能力(?)看起来是比较难以共存的。
其实很多静态编程语言,比如 C、C++ 和 Rust 都通过宏实现了比较强大的元编程能力,虽然 Swift 也通过模板在元编程支持上做了一些微小的努力,不过到目前来看( 3.0 )还是远远不够的。

OC 中对于 nil 的处理能够减少我们在编码时的工作量,不过也对工程师的代码质量提出了考验。我们需要思考 nil 的出现会不会带来崩溃,是否会导致行为的异常、增加应用崩溃的风险以及不确定性,而这也是 Swift 引入 Optional 这一概念来避免上述问题的初衷。
相比而言,笔者还是更喜欢强大的元编程能力,这样可以减少大量的重复工作并且提供更多的可能性,与提升工作效率相比,牺牲一些安全性还是可以接受的。
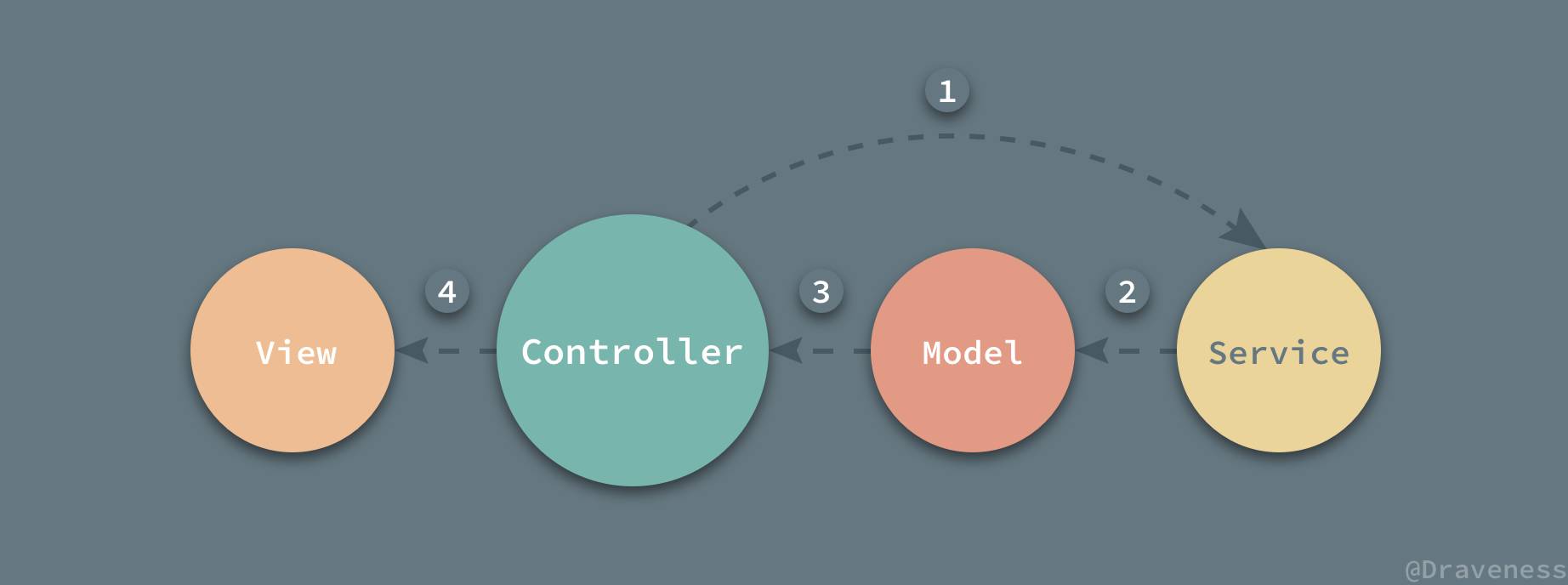
现有的大多数应用都会将网路服务组织成单独的一层,所以有时候你会看到所谓的 MVCS 架构模式,它其实只是在 MVC 的基础上加上了一个服务层(Service),而在 iOS 中常见的 MVC 架构模式也都可以理解为 MVCS 的形式,当引入了 Service 层之后,整个数据的获取以及处理的流程是这样的:
-
大多数情况下服务的发起都是在 Controller 中进行的;
-
然后会在 HTTP 请求的回调中交给模型层处理 JSON 数据;
-
返回开箱即用的对象交还给 Controller 控制器;
-
最后由 View 层展示服务端返回的数据;
不过按理来说服务层并不属于模型层,为什么要在这里进行介绍呢?这是因为
Service 层其实与 Model 层之间的联系非常紧密
;网络请求返回的结果决定了 Model 层该如何设计以及该有哪些功能模块,而 Service 层的设计是与后端的 API 接口的设计强关联的,这也是我们谈模型层的设计无法绕过的坑。
iOS 中的 Service 层大体上有两种常见的组织方式,其中一种是命令式的,另一种是声明式的。
命令式的 Service 层一般都会为每一个或者一组 API 写一个专门用于 HTTP 请求的 Manager 类,在这个类中,我们会在每一个静态方法中使用 AFNetworking 或者 Alamofire 等网络框架发出 HTTP 请求。
import Foundation
import Alamofire
final class UserManager {
static let baseURL = "http://localhost:3000"
static let usersBaseURL = "\(baseURL)/users"
static func allUsers(completion: @escaping ([User]) -> ()) {
let url = "\(usersBaseURL)"
Alamofire.request(url).responseJSON { response in
if let jsons = response.result.value as? [[String: Any]] {
let users = User.users(jsons: jsons)
completion(users)
}
}
}
static func user(id: Int, completion: @escaping (User) -> ()) {
let url = "\(usersBaseURL)/\(id)"
Alamofire.request(url).responseJSON { response in
if let json = response.result.value as? [String: Any],
let user = User(json: json) {
completion(user)
}
}
}
}
在这个方法中,我们完成了网络请求、数据转换 JSON、JSON 转换到模型以及最终使用 completion 回调的过程,调用 Service 服务的 Controller 可以直接从回调中使用构建好的 Model 对象。
UserManager.user(id: 1) { user in
self.nameLabel.text = user.name
self.emailLabel.text = user.email
self.ageLabel.text = "\(user.age)"
self.genderLabel.text = user.gender.rawValue
}
使用声明式的网络服务层与命令式的方法并没有本质的不同,它们最终都调用了底层的一些网络库的 API,这种网络服务层中的请求都是以配置的形式实现的,需要对原有的命令式的请求进行一层封装,也就是说所有的参数 requestURL、method 和 parameters 都应该以配置的形式声明在每一个 Request 类中。
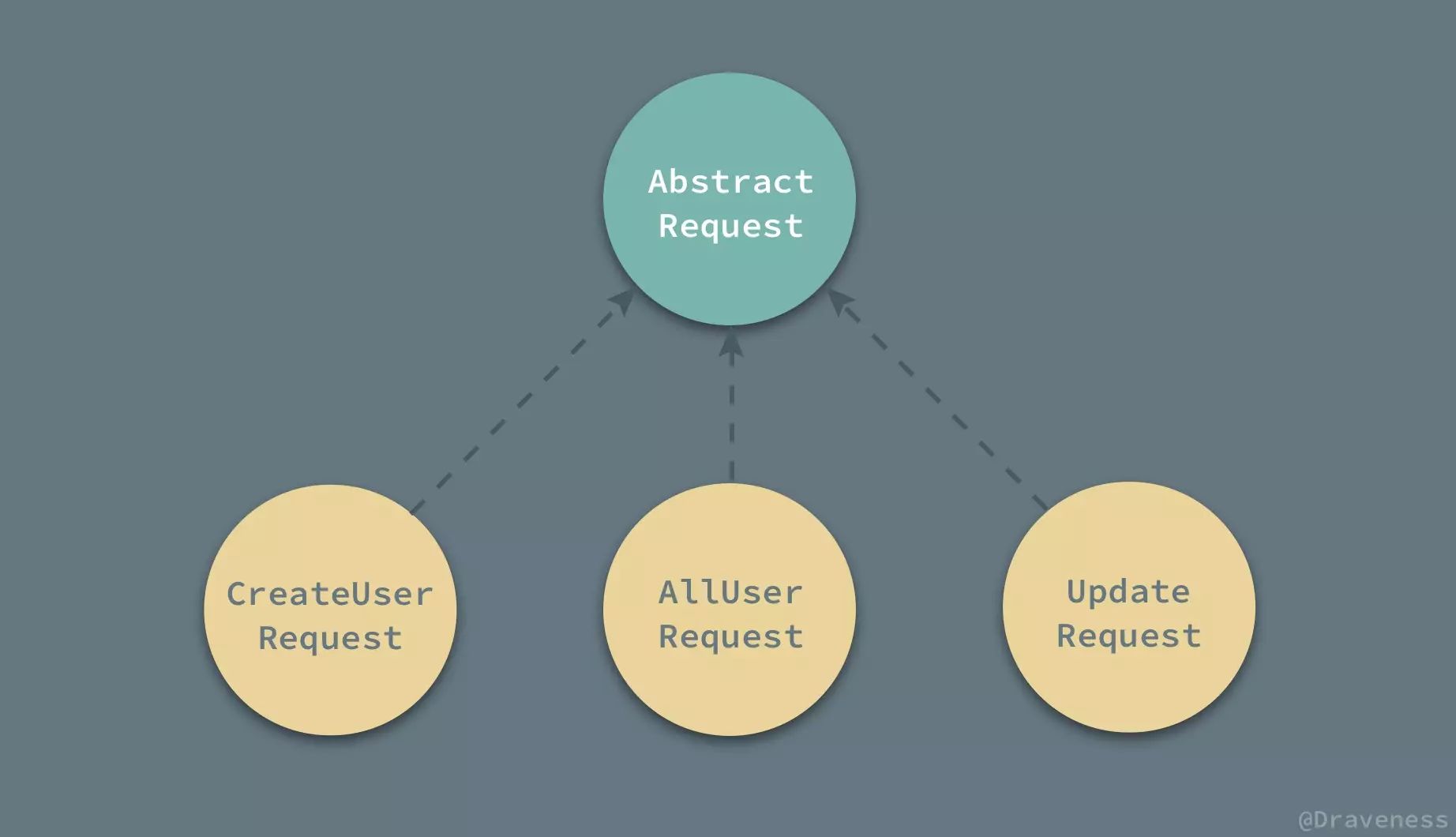
如果是在 Objective-C 中,一般会定义一个抽象的基类,并让所有的 Request 都继承它;但是在 Swift 中,我们可以使用协议以及协议扩展的方式实现这一功能。
protocol AbstractRequest {
var requestURL: String { get }
var method: HTTPMethod { get }
var parameters: Parameters? { get }
}
extension AbstractRequest {
func start(completion: @escaping (Any) -> Void) {
Alamofire.request(requestURL, method: self.method).responseJSON { response in
if let json = response.result.value {
completion(json)
}
}
}
}
在 AbstractRequest 协议中,我们定义了发出一个请求所需要的全部参数,并在协议扩展中实现了 start(completion:) 方法,这样实现该协议的类都可以直接调用 start(completion:) 发出网络请求。
final class AllUsersRequest: AbstractRequest {
let requestURL = "http://localhost:3000/users"
let method = HTTPMethod.get
let parameters: Parameters? = nil
}
final class FindUserRequest: AbstractRequest {
let requestURL: String
let method = HTTPMethod.get
let parameters: Parameters? = nil
init(id: Int) {
self.requestURL = "http://localhost:3000/users/\(id)"
}
}
我们在这里写了两个简单的 Request 类 AllUsersRequest 和 FindUserRequest,它们两个一个负责获取所有的 User 对象,一个负责从服务端获取指定的 User;在使用上面的声明式 Service 层时也与命令式有一些不同:
FindUserRequest(id: 1).start { json in
if let json = json as? [String: Any],
let user = User(json: json) {
print(user)
}
}
因为在 Swift 中,我们没法将 JSON 在 Service 层转换成模型对象,所以我们不得不在 FindUserRequest 的回调中进行类型以及 JSON 转模型等过程;又因为 HTTP 请求可能依赖其他的参数,所以在使用这种形式请求资源时,我们需要在初始化方法传入参数。
现有的 iOS 开发中的网络服务层一般都是使用这两种组织方式,我们一般会按照
资源
或者
功能
来划分命令式中的 Manager 类,而声明式的 Request 类与实际请求是一对一的关系。

这两种网络层的组织方法在笔者看来没有高下之分,无论是 Manager 还是 Request 的方式,尤其是后者由于一个类只对应一个 API 请求,在整个 iOS 项目变得异常复杂时,就会导致
网络层类的数量剧增
。
这个问题并不是不可以接受的,在大多数项目中的网络请求就是这么做的,虽然在查找实际的请求类时有一些麻烦,不过只要遵循一定的
命名规范
还是可以解决的。
现有的 MVC 下的 Model 层,其实只起到了对数据结构定义的作用,它将服务端返回的 JSON 数据,以更方便使用的方式包装了一下,这样呈现给上层的就是一些即拆即用的『字典』。

单
独的 Model 层并不能返回什么关键的作用,它只有与网络服务层 Service 结合在一起的时候才能发挥更重要的能力。

而网络服务 Service 层是对 HTTP 请求的封装,其实现形式有两种,一种是命令式的,另一种是声明式的,这两种实现的方法并没有绝对的优劣,遵循合适的形式设计或者重构现有的架构,随着应用的开发与迭代,为上层提供相同的接口,保持一致性才是设计 Service 层最重要的事情。
虽然文章是对客户端中 Model 层进行分析和介绍,但是在客户端大规模使用 MVC 架构模式之前,服务端对于 MVC 的使用早已有多年的历史,而移动端以及 Web 前端对于架构的设计是近年来才逐渐被重视。
因为客户端的应用变得越来越复杂,动辄上百万行代码的巨型应用不断出现,以前流水线式的开发已经没有办法解决现在的开发、维护工作,所以合理的架构设计成为客户端应用必须要重视的事情。
这一节会以 Ruby on Rails 中 Model 层的设计为例,分析在经典的 MVC 框架中的 Model 层是如何与其他模块进行交互的,同时它又担任了什么样的职责。





