我们将处理130年的棒球甲级联赛的数据,数据源于
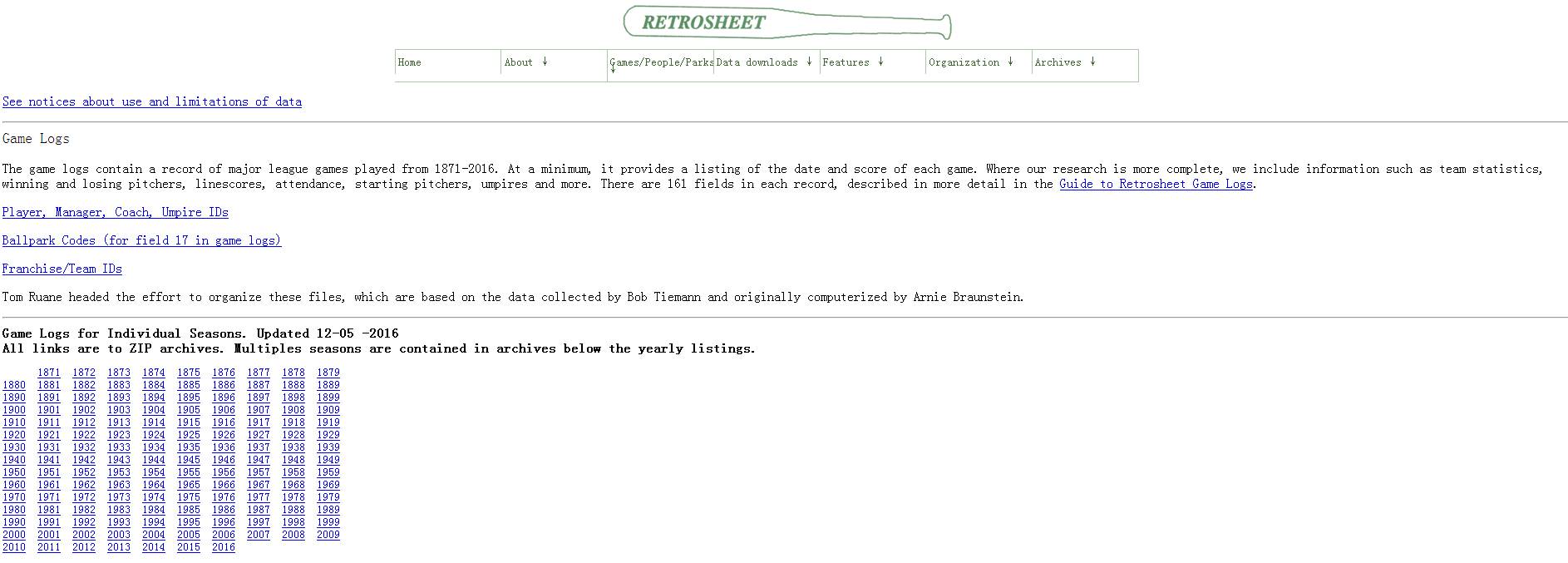
Retrosheet
(http://www.retrosheet.org/gamelogs/index.html)
原始数据放在127个csv文件中,我们已经用
csvkit
(https://csvkit.readthedocs.io/en/1.0.2/)
将其合并,并添加了表头。如果你想下载我们版本的数据用来运行本文的程序,我们提供了
下载地址
。
(
https://data.world/dataquest/mlb-game-logs
)
我们从导入数据,并输出前5行开始:

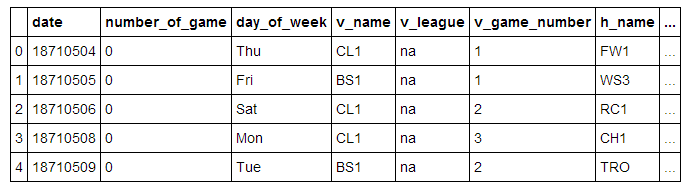
我们将一些重要的字段列在下面:
-
date
- 比赛日期
-
v_name
- 客队名
-
v_league
- 客队联赛
-
h_name
- 主队名
-
h_league
- 主队联赛
-
v_score
- 客队得分
-
h_score
- 主队得分
-
v_line_score
- 客队线得分, 如010000(10)00.
-
h_line_score
- 主队线得分, 如010000(10)0X.
-
park_id
- 主办场地的ID
-
attendance
- 比赛出席人数
我们可以用
Dataframe.info()
方法来获得我们dataframe的一些高level信息,譬如数据量、数据类型和内存使用量。
这个方法默认情况下返回一个近似的内存使用量,现在我们设置参数
memory_usage
为
'deep'
来获得准确的内存使用量:

我们可以看到它有171907行和161列。pandas已经为我们自动检测了数据类型,其中包括83列数值型数据和78列对象型数据。对象型数据列用于字符串或包含混合数据类型的列。
由此我们可以进一步了解我们应该如何减少内存占用,下面我们来看一看pandas如何在内存中存储数据。
在底层,pandas会按照数据类型将列分组形成数据块(blocks)。下图所示为pandas如何存储我们数据表的前十二列:
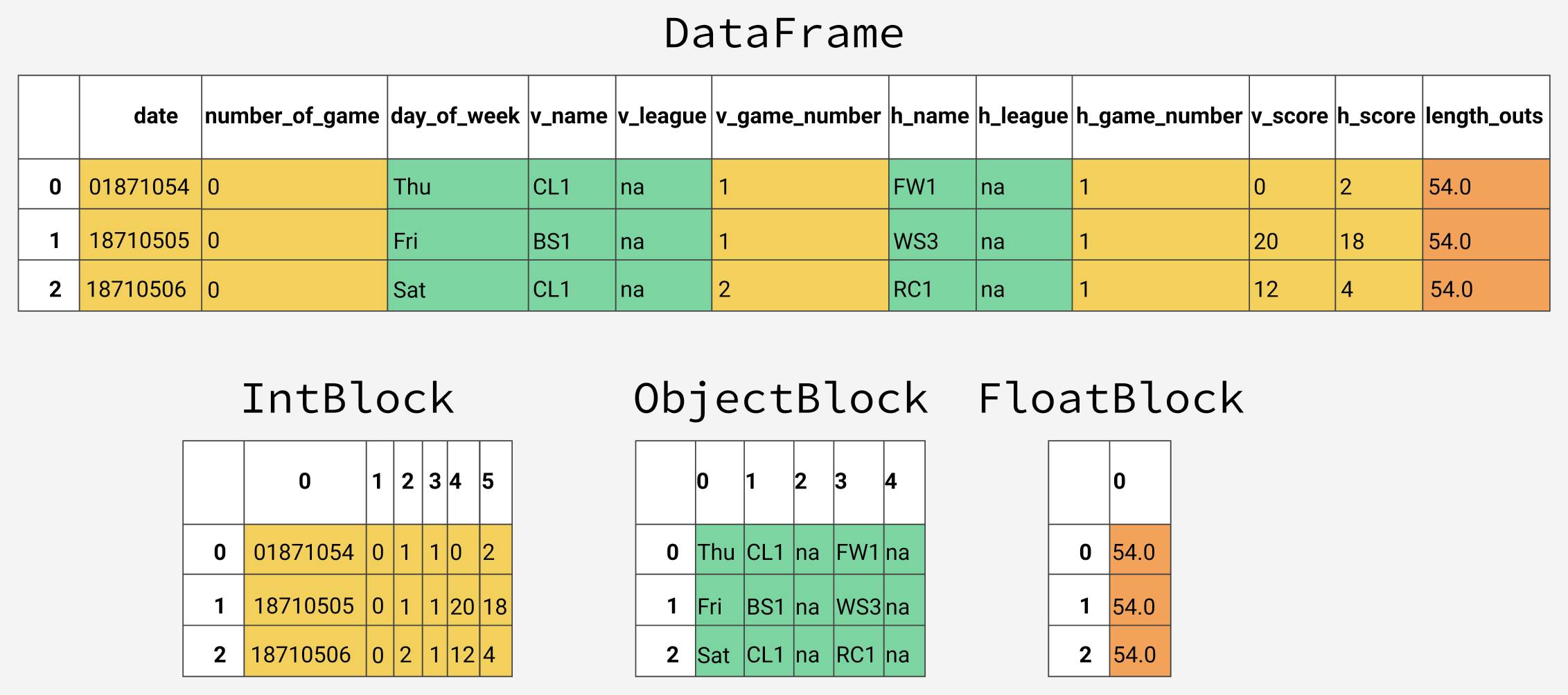
可以注意到,这些数据块没有保持对列名的引用,这是由于为了存储dataframe中的真实数据,这些数据块都经过了优化。有个
BlockManager类
会用于保持行列索引与真实数据块的映射关系。他扮演一个API,提供对底层数据的访问。每当我们查询、编辑或删除数据时,dataframe类会利用BlockManager类接口将我们的请求转换为函数和方法的调用。
每种数据类型在
pandas.core.internals
模块中都有一个特定的类。pandas使用ObjectBlock类来表示包含字符串列的数据块,用FloatBlock类来表示包含浮点型列的数据块。对于包含数值型数据(比如整型和浮点型)的数据块,pandas会合并这些列,并把它们存储为一个Numpy数组(ndarray)。Numpy数组是在C数组的基础上创建的,其值在内存中是连续存储的。基于这种存储机制,对其切片的访问是相当快的。
由于不同类型的数据是分开存放的,我们将检查不同数据类型的内存使用情况,我们先看看各数据类型的平均内存使用量:
由于不同类型的数据是分开存放的,我们将检查不同数据类型的内存使用情况,我们先看看各数据类型的平均内存使用量:
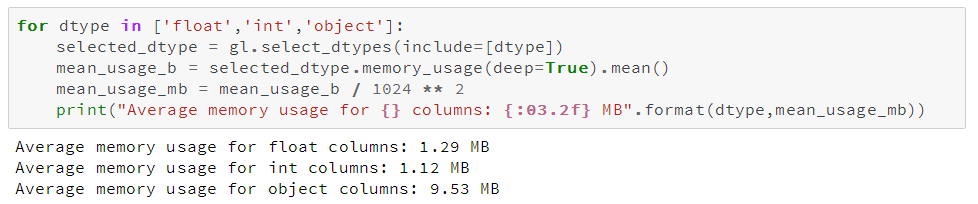
我们可以看到内存使用最多的是78个
object
列,我们待会再来看它们,我们先来看看我们能否提高数值型列的内存使用效率
。
刚才我们提到,pandas在底层将数值型数据表示成Numpy数组,并在内存中连续存储。这种存储方式消耗较少的空间,并允许我们较快速地访问数据。由于pandas使用相同数量的字节来表示同一类型的每一个值,并且numpy数组存储了这些值的数量,所以pandas能够快速准确地返回数值型列所消耗的字节量。
pandas中的许多数据类型具有多个子类型,它们可以使用较少的字节去表示不同数据,比如,
float
型就有
float16
、
float32
和
float64
这些子类型。这些类型名称的数字部分表明了这种类型使用了多少比特来表示数据,比如刚才列出的子类型分别使用了2、4、8个字节。下面这张表列出了pandas中常用类型的子类型:
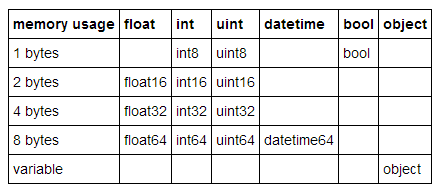
一个
int8
类型的数据使用1个字节(8位比特)存储一个值,可以表示256(2^8)个二进制数值。这意味着我们可以用这种子类型去表示从-128到127(包括0)的数值。
我们可以用
numpy.iinfo
类来确认每一个整型子类型的最小和最大值,如下
:
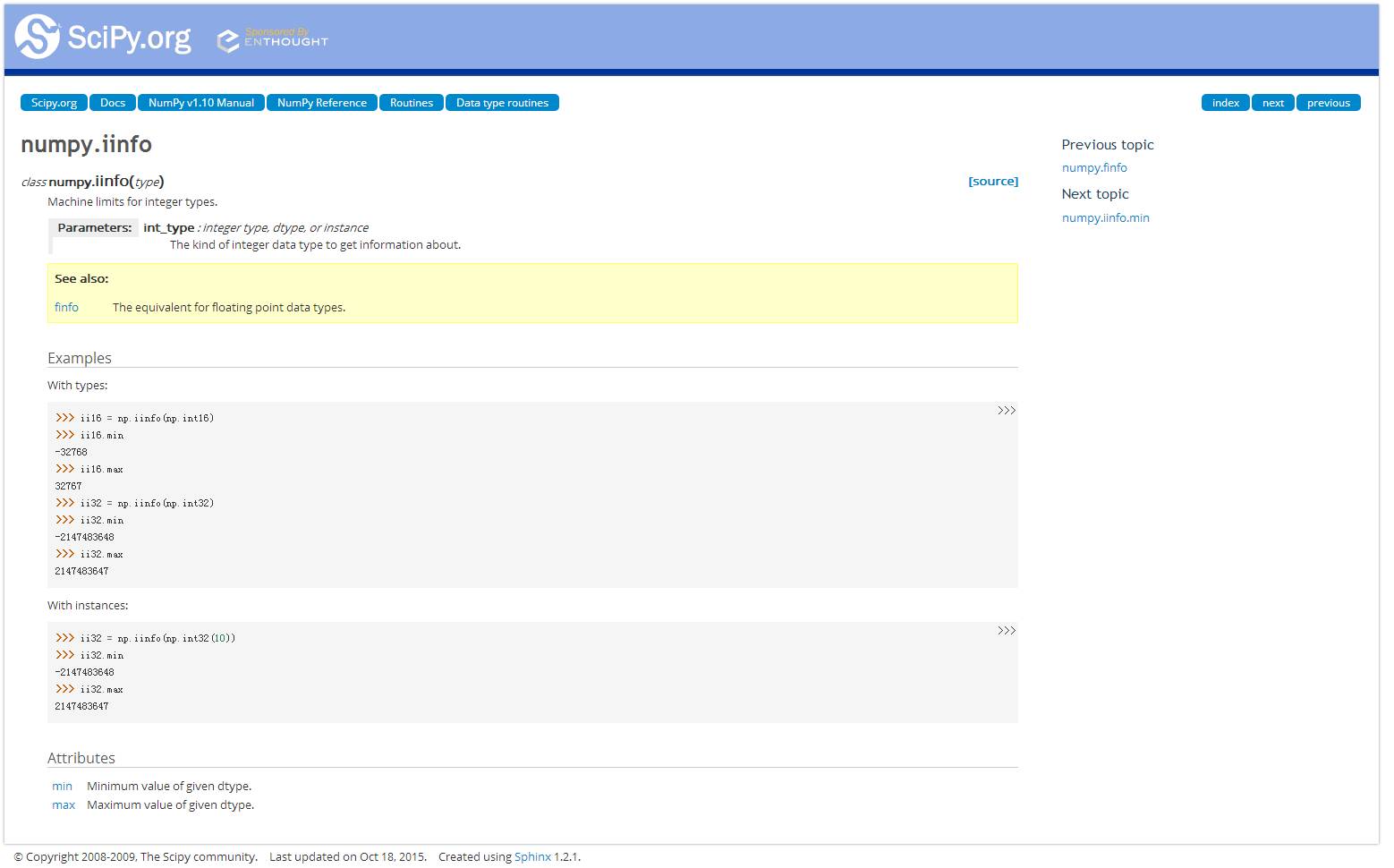
这里我们还可以看到
uint
(无符号整型)和
int
(有符号整型)的区别。两者都占用相同的内存存储量,但无符号整型由于只存正数,所以可以更高效的存储只含正数的列。
我们可以用函数
pd.to_numeric()
来对数值型进行向下类型转换。我们用
DataFrame.select_dtypes
来只选择整型列,然后我们优化这种类型,并比较内存使用量。
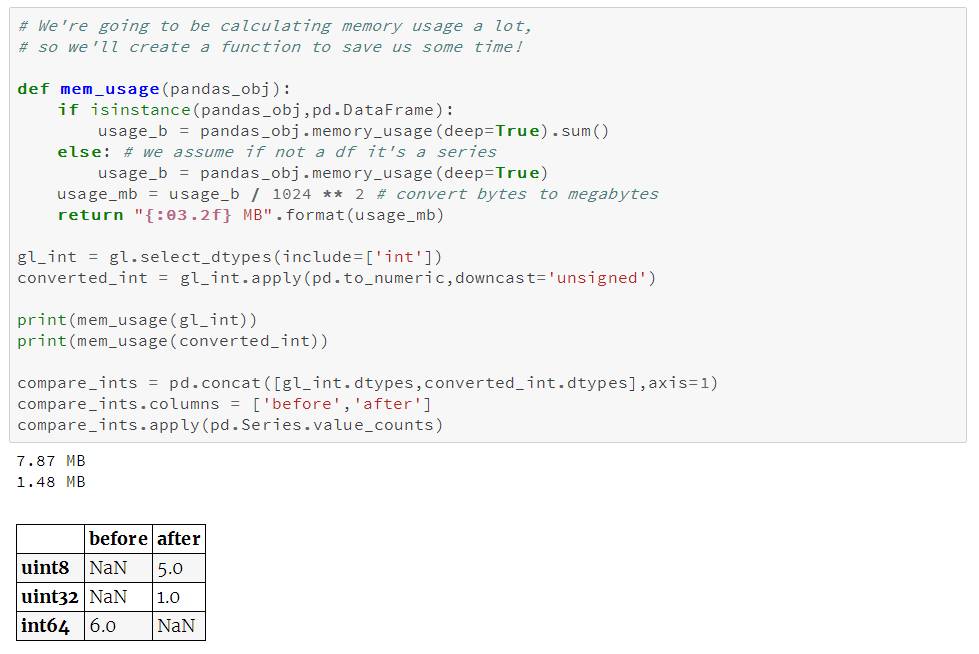
我们看到内存用量从7.9兆下降到1.5兆,降幅达80%。这对我们原始dataframe的影响有限,这是由于它只包含很少的整型列。
同理,我们再对浮点型列进行相应处理:
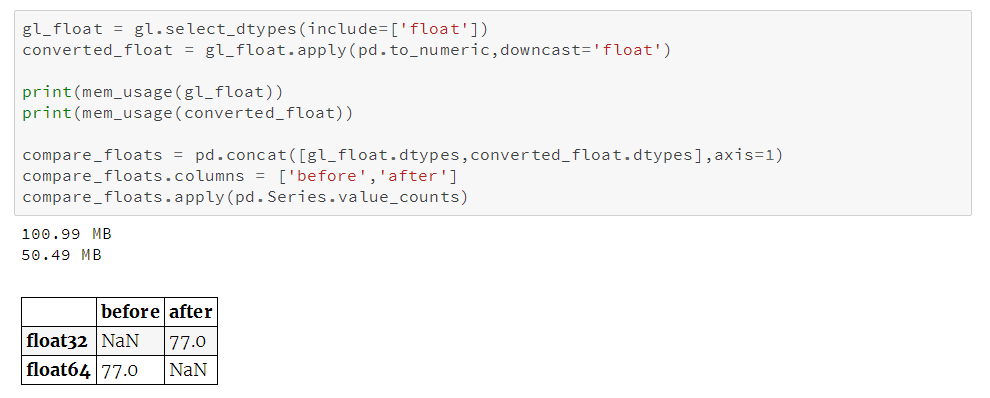
我们可以看到所有的浮点型列都从
float64
转换为
float32
,内存用量减少50%。
我们再创建一个原始dataframe的副本,将其数值列赋值为优化后的类型,再看看内存用量的整体优化效果。

可以看到通过我们显著缩减数值型列的内存用量,我们的dataframe的整体内存用量减少了7%。余下的大部分优化将针对object类型进行
。
在这之前,我们先来研究下与数值型相比,pandas如何存储字符串。




