
扫描下方海报
试读


本文来源:
kk的技术分享
1、前言
前段时间在忙,这几天抽时间写一下阿里比赛总结,以往比赛都是前十名入围,这次只有复赛前五才能入围,竞争非常激烈,我和普哥一组,在普哥的帮助下学到不少优化技巧。先贴下成绩
初赛第五,有些遗憾复赛只搞到第九,重在参与哈哈。
2、初赛
2.1、赛题回顾
自适应负载均衡:实现一套负载均衡算法,使系统吞吐量达到最大
要求:
实现接口LoadBalance,实现一套自适应负载均衡机制。要求能够具备以下能力:
-
Gateway(Consumer) 端能够自动根据服务处理能力变化动态最优化分配请求保证较低响应时间,较高吞吐量;
-
Provider 端能自动进行服务容量评估,当请求数量超过服务能力时,允许拒绝部分请求,以保证服务不过载;
-
当请求速率高于所有的 Provider 服务能力之和时,允许 Gateway( Consumer ) 拒绝服务新到请求。
LoadBalance接口(其他辅助接口不再一一列举):
1public interface LoadBalance {
2
3 /**
4 * select one invoker in list.
5 *
6 * @param invokers invokers.
7 * @param url refer url
8 * @param invocation invocation.
9 * @return selected invoker.
10 */
11 @Adaptive("loadbalance")
12 Invoker select(List> invokers, URL url, Invocation invocation) throws RpcException;
13
14}
2.2、赛题解析
在解析赛题之前我们先了解两个概念:
延迟
:处理单次事件所需时间。
吞吐
:单位时间内程序可以处理的事件数。
假如一个程序只有1个线程,这个线程每秒可以处理10次事件,那么我们说这个程序处理单次事件的延迟为100ms,吞吐为10次/秒
假如一个程序有4个线程,每个线程每秒可以处理5次事件,那么我们说这个程序处理单次事件的延迟为200ms,吞吐为20次/秒
假如一个程序有1个线程,每个线程每秒可以处理20次事件,那么我们说这个程序处理单次事件的延迟为50ms,吞吐为20次/秒
以上我们可以看出,在一个没有瓶颈的程序中,
增加线程可以增加吞吐,降低延迟也可以增加吞吐,但低延迟不一定高吞吐,高延迟也不一定低吞吐
。
赛题要求实时根据Provider能力大小动态选择Provider来处理请求,这里说一下三个Provider的
线程和延迟都是会变
,且
单个Provider总的能力呈泊松分布
也就是说多次请求的
rtt方差会比较大
,但是
rtt均值在时间段内波动较小
所以只要我们每次请求都打到正确(
延迟小且有剩余线程
)的Provider上就ok,前面在钉钉群里发现有不少选手有这样两个疑问,这里解释一下
选手A
:我一顿操作下来分数竟然比随机算法低很多,
为什么随机算法会有那么高的分数?
解析
:其实随机算法的分数是可以计算出来的,举个例子,假如我们有三个容器,容量分别为1L,2L,3L,我们有6L水,每次随机往某个容器倒入1L水,容器里最终能够保持多少水呢?
答案是5L,因为6L水随机倒入三个容器每个容器都会获得2L水,第一个容器因为容量只有1L所以溢出1L,假如满分120分的话我们可以拿到100分,如果三个容器容量分别是1.5L,2L,2.5L,那么我们的分数将会高达110分。
(评测环境情况比这个要复杂一些,需要多考虑一些变量,原理差不多这里不再展开)
选手B:我的程序评测下来全程没有error出现可是分数还是上不去,咋回事呢?
解析
:不知道大家有没有注意到Provider的总连接数是大于请求数的,有些请求打到有剩余线程但是延迟不一定小的Provider上了
所以看起来没错误但是延迟很高RPS很难上去(因为评测程序中Provider总吞吐是大于请求总数的,所以一般情况下也很难出现错误)。贴一张Provider请求数与RTT的图,
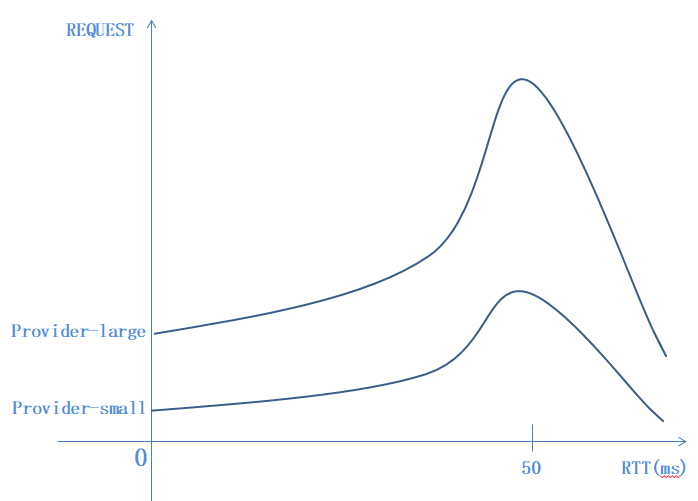
我们这里用的是
基于历史rtt为参考的选择策略
,因为rtt是呈泊松分布的,
所以单看rtt(延迟低的)数量,能力大的Provider一定比能力小的Provider的多
,所以我们可以搞棵树把每次请求rtt存储起来,排序一下
这里需要为rtt特别的低的Provider提权,即当rtt小于某值(或百分比)时,往树里多add几个该Provider,同时从数尾移除相同数量的Provider
提权的目的探测Provider能力变化及探测Provider的真实能力(比如说在所有Provider都不拒绝服务的情况下,单凭树里的rtt并不能真实反映出Provider的实际处理能力),每次选择Provider是从树里移除rtt最小的那个Provider,把请求发送到该Provider,如果某个低延迟的Provider线程不够时,该Provider的rtt逐渐变大,直到出现拒绝服务,此时只要不把reject的res加入到树就ok。
3、复赛
3.1、赛题回顾
实现一个进程内基于队列的消息持久化存储引擎
,要求包含以下功能:
-
发送消息功能
-
根据一定的条件做查询或聚合计算,包括
A. 查询一定时间窗口内的消息
B. 对一定时间窗口内的消息属性某个字段求平均
例子:t表示时间,时间窗口[1000, 1002]表示: t>=1000 & t<=1002 (这里的t和实际时间戳没有任何关系, 只是一个模拟时间范围)
消息包括两个字段,一个是业务字段a,一个是时间戳,以及一个byte数组消息体。
程序接口如下:
1public abstract class MessageStore {
2 /**
3
* 写入一个消息;
4 * 这个接口需要是线程安全的,也即评测程序会并发调用该接口进行put;
5 * @param message message,代表消息的内容,评测时内容会随机产生
6 */
7 abstract void put(Message message);
8
9 /**
10 * 根据a和t的条件,返回符合条件的消息的集合. t是输入时间戳模拟值,和实际时间戳没有关系, 线程内升序
11 * 这个接口需要是线程安全的,也即评测程序会并发调用该接口
12 * 返回的List需要按照t升序排列 (a不要求排序). 如果没有符合的消息, 返回大小为0的List. 如果List里有null元素, 会当结果失败处理
13 * 单条线程最大返回消息数量不会超过8万
14 * @param aMin 代表a的最小值(包含此值)
15 * @param aMax 代表a的最大值(包含此值)
16 * @param tMin 代表t的最小值(包含此值)
17 * @param tMax 代表t的最大值(包含此值)
18 */
19 abstract List getMessage(long aMin, long aMax, long tMin, long tMax);
20
21 /**
22 * 根据a和t的条件,返回符合条件消息的a值的求平均结果. t是输入时间戳模拟值,和实际时间戳没有关系, 线程内升序
23 * 这个接口需要是线程安全的,也即评测程序会并发调用该接口
24 * 结果忽略小数位,返回整数位即可. 如果没有符合的消息, 返回0
25 * 单次查询求和最大值不会超过Long.MAX_VALUE
26 * @param aMin 代表a的最小值(包含此值)
27 * @param aMax 代表a的最大值(包含此值)
28 * @param tMin 代表t的最小值(包含此值)
29 * @param tMax 代表t的最大值(包含此值)
30 */
31 abstract long getAvgValue(long aMin, long aMax, long tMin, long tMax);
32
33}
发送消息如下(忽略消息体):
1消息1,消息属性{"a":1,"t":1001}
2消息2,消息属性{"a":2,"t":1002}
3消息3,消息属性{"a":3,"t":1003}
查询如下:
1示例1-
2 输入:时间窗口[1001,9999],对a求平均
3 输出:2, 即:(1+2+3)/3=2
4
示例2-
5 输入:时间窗口[1002,9999],求符合的消息
6 输出:{"a":1,"t":1002},{"a":3,"t":1003}
7示例3-
8 输入:时间窗口[1000,9999]&(a>=2),对a求平均
9 输出:2 (去除小数位)
语言限定
:JAVA
评测指标和规模
:评测程序分为3个阶段:发送阶段、查询聚合消息阶段、查询聚合结果阶段:
发送阶段:假设发送消息条数为N1,所有消息发送完毕的时间为T1;发送线程多个,消息属性为: a(随机整数), t(输入时间戳模拟值,和实际时间戳没有关系, 线程内升序).消息总大小为50字节,消息条数在20亿条左右,总数据在100G左右
查询聚合消息阶段:有多次查询,消息总数为N2,所有查询时间为T2; 返回以t和a为条件的消息, 返回消息按照t升序排列
查询聚合结果阶段: 有多次查询,消息总数为N3,所有查询时间为T3; 返回以t和a为条件对a求平均的值
若查询结果都正确,则最终成绩为N1/T1 + N2/T2 + N3/T3
3.2、赛题分析
-
实现一个进程内消息持久化引擎,
不需要考虑程序崩溃及被kill情况
-
评测三个阶段相互独立,
不需要考虑同时读写情况
-
消息有三个属性,t(long),a(long),b(byte[34]),
消息为定长消息,简化索引设计及存储缓存设计
-
t在线程内有序(可能重复),线程间无序
线程内无需排序,只需要做线程间消息排序
-
消息数在2G(20亿)条左右,消息总量约为100G,
其中t16G,a16G,b68G,
-
两次查询分别是msg和avg,
t,a,b,分别存储,有利于avg查询
3.3、程序设计
3.3.1、存储
前面提到过,t在线程内有序,借助这一点我们可以少很多排序量,只需要做线程间排序就好
这里我们把每个发送线程当作一个Queue,把每个Queue当作一个整体,对多个Queue进行排序,得到一个有序的Queue队列,
贴张图:
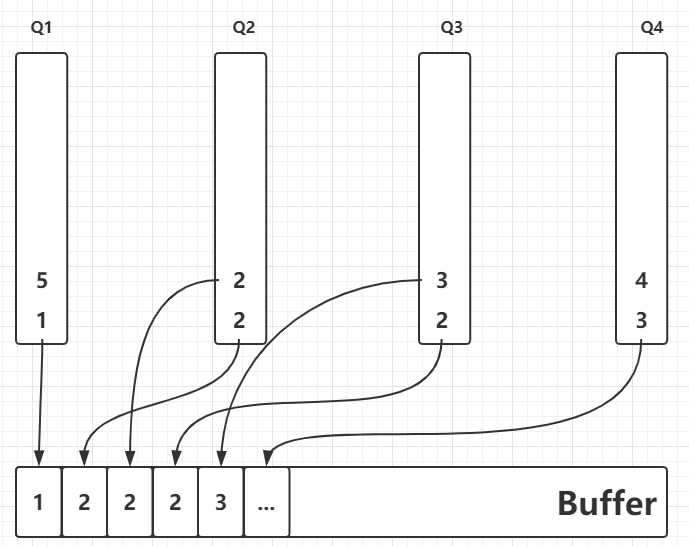
每次从Queue的头部取出一个消息,然后对Queue队列进行排序:
1MQueue sort_head = this.sort_head;
2if (queue == sort_head) {
3 for (; ; ) {
4 Message message = sort_head.remove();
5 if (message == null) {
6
break;
7 }
8 put_message(message);
9 MQueue next = sort_head.next;
10 if (next == null) {
11 break;
12 }
13 if (sort_head.cur_t() > next.cur_t()) {
14 sort_head = sort(next, sort_head);
15 }
16 }
17 this.sort_head = sort_head;
18}
这样我们得到一个全局有序的队列,buffer落盘即可。这里落盘之前我们需要对t和a进行压缩(delta),t压缩后接近3.8G可以全部放在内存,a压缩后大约9G出头。
因为t排序后再次对a排序,导致t在分片内乱序,所以t用zigzag压缩。
因为a排序是升序,所以对a使用vlong压缩,这里说下a压缩对vlong做下改进,采用定长(4字节)+变长的方式进行压缩,代码如下:
1public long readVLong() {
2 long b1 = get() & 0xff;
3 long b2 = get() & 0xff;
4 long b3 = get() & 0xff;
5 long v = 0;
6 int off = 0;
7 for (; ; ) {
8 long b = get();
9 v |= (b & 0b0111_1111) <10 if (b >= 0) {
11 break;
12 }
13 off += 7;
14 }
15 v <<= 24;
16 return v | ((b1 <16) | (b2 <8) | (b3));
17}
18
19public
void writeVLong(long v) {
20 long w = v & (0xffffff);
21 v >>>= 24;
22 put((byte) (w >>> 16));
23 put((byte) (w >>> 8));
24 put((byte) (w));
25 for (; ; ) {
26 w = v & 0b0111_1111;
27 v >>>= 7;
28 if (v != 0) {
29 put((byte) (w | 0b1000_0000));
30 } else {
31 put((byte) w);
32 break;
33 }
34 }
35}
有对b尝试使用lz4压缩,效果不理想,放弃对b压缩
3.3.2、查询
先上张图
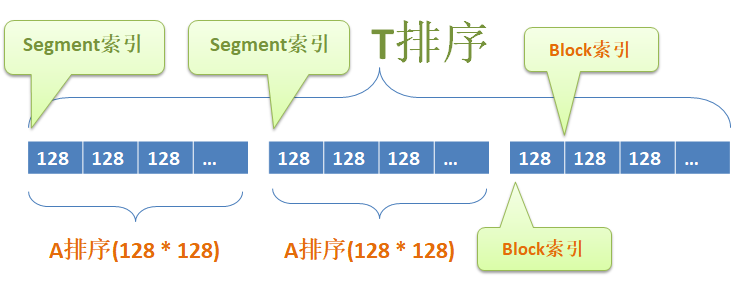
(我们是按t的个数分segment的,按t值划分的也写了一版,试了下两个方案分数差不多,因为感觉按t个数划分的更好处理些,因为时间原因后面都是按个数划分来优化的,理论上按t值划分分数应该更好)
从图中可以每隔16384做一次segment,segment内每隔128条消息做一个block,每个block内有128条消息,每隔128条消息做一次索引,索引分别是:
1ByteBuffer index_t_sparse = allocateDirect(SPARSE_INDEX_COUNT * 8);
2ByteBuffer index_t_data_pos = allocateDirect(COMPACT_INDEX_COUNT * 8);
3long[] index_a_data_pos = new long[COMPACT_INDEX_COUNT];
4long[] index_t_compact = new long[COMPACT_INDEX_COUNT];
5long[] index_a_compact = new long[COMPACT_INDEX_COUNT];
6long[] index_a_sum = new long[COMPACT_INDEX_COUNT];
7long[] index_a_min_max = new long[COMPACT_INDEX_COUNT * 2];
-
index_t_sparse
:segment索引,记录t值,用于快速定位查询所在segment
-
index_t_data_pos
:block索引,t压缩后位置索引,记录t数据block起始位置,用于计算t真实值
-
index_a_data_pos
:同index_t_data_pos
-
index_t_compact
:block索引,记录t值,用于计算t真实值
-
index_a_compact
:同index_t_compact
-
index_a_sum
:block索引,记录block内a的sum值,用于avg时快速跳过block
-
index_a_min_max
:block索引,记录block内a的min,max值,用于avg时快速跳过block
查询msg时首先定位所在segment:
1int t_index_cnt = (index_t_sparse.position() >>> 3) - 1; // size -1
2int t_index_min = half_find(index_t_sparse_addr, 0, t_index_cnt, min_t);
3int t_index_max = get_t_index_max(index_t_sparse_addr, t_index_min, t_index_cnt, max_t);
得到segment起始位置:t_index_min,t_index_max
这里需要处理下首尾segment,因为首尾segment的t值可能不在查询范围内需要单独处理,
遍历segment定位block范围:
1int a_index_off = get_a_read_index_off(index_a_min_max, a_index_cnt, a_index_min, min_a);
2int a_index_len = get_a_read_index_len(index_a_min_max, a_index_cnt, a_index_min, a_index_off, max_a);
得到某个segment内block的off和len:a_index_off,a_index_len
根据off和len定位a,b的读取pos和len
1long a_read_pos = index_a_data_pos[a_index_off];
2long b_read_pos = 1L * (a_index_off * A_BLOCK) * B_LEN;
3










