
本文简要介绍
ICCV2019
录用的一篇文章
GA-DAN:Geometry-Aware Domain Adaptation Network for Scene Text Detection and Recognition
。该文章使用生成对抗网络的思想来做D
omain Adaptation
,解决了源域(S
ource Domain
)和目标域(T
arget Domain
)由于数据分布差异大造成训练效果差的问题。
近年来,随着深度神经网络的发展,很多领域都取得了突破性的进展。但是,要训练一个鲁棒的深度神经网络需要大量的标注数据,这就需要耗费大量的人力物力成本。而现有的基于监督学习方法训练得到的深度神经网络模型泛化能力有限,当新的测试数据与训练数据存在差异时,可能会导致训练好的模型在新的测试数据上效果较差,而要想取得一个较好的效果就需要再额外标注一批与测试数据分布相似的数据。数据集可迁移性较低导致标注成本大大提高。为了解决这个问题,作者提出了一种基于生成对抗网络的D
omain Adaptation
的方法用来缩小
Source Domain
和
Target Domain
的差异。
基于生成对抗网络的
Domain Adaptation
方法已经有比较多的研究,但是现有的方法主要解决的问题是数据在外观上(
Appearance
)的差异,往往忽略数据在几何形状(G
eometry
)上的差异。作者认为数据在几何形状上的差异和外观上的差异都会造成模型效果下降,从而提出
Geometry-Aware Domain Adaptation Network (GA-DAN)
,该模型同时对外观(
Appearance
)和几何形状(
Geometry
)进行迁移。作者将
GA-DAN
应用到自然场景文本检测识别任务上,取得了很好的迁移效果。
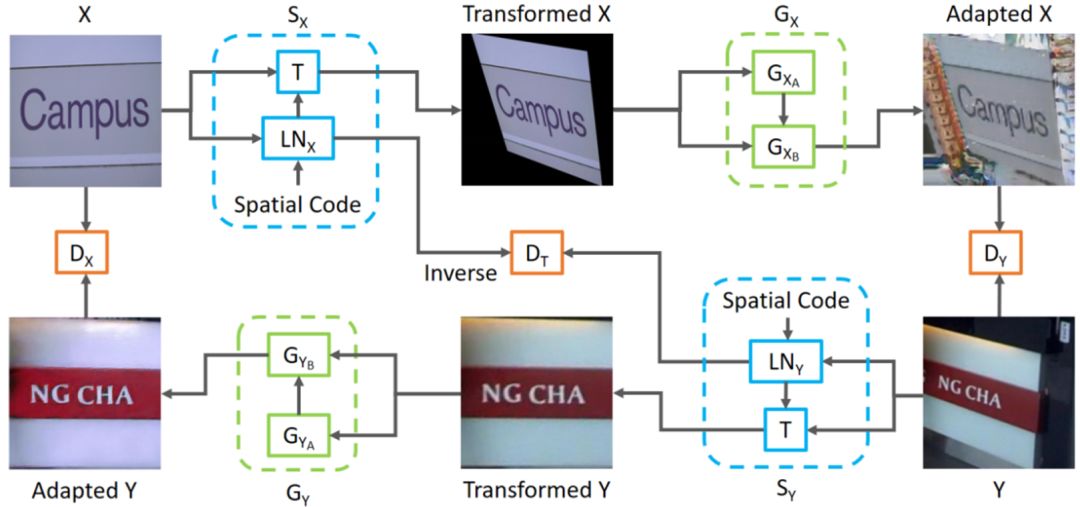
Fig.1. Overall architecture.
Fig. 1
是
GA-DAN
的整体网络结构图。总体网络结构是基于
CycleGAN[1]
的改进,图片从
Source Domain
到
Target Domain
主要是经过两个模块,第一个模块是对几何形状进行迁移(对应
Fig. 1
中的蓝色虚线框内的模块),第二个模块是对图片外观进行迁移(对应
Fig.1
中的绿色虚线框内的模块),这个模块由两个网络组成和。经过几何变换后,图片边缘会存在空缺,主要是用来对边缘空缺像素做一个填充,是对填充后的图片进行外观上的迁移。通过这两个模块的迁移,可以生成几何形状和外观都和
Target Domain
比较相似的图片。从
Target Domain
到
Source Domain
的循环过程同样也包括上面所述的两个模块。判别器主要由两个部分组成,其中一个主要用来判别外观上是否真实(对应
Fig.1
中的和),另一个主要用来判别几何变换是否真实(对应
Fig. 1
中的)。
为了输入一张图片能有多张不同形状的图片输出,作者设计了一个
Multi-modal Spatial Learning
的模块(
Fig. 1
中的蓝色虚线框内的模块)。做法就是在预测几何变换过程中加入一个
Spatial Code
,这个
Spatial Code
是一个随机向量,不同的
Spatial Code
可以生成不同的几何变换。所以当网络训练完成后可以通过多次前向操作生成多张不同形状的图片,大大扩充数据集。
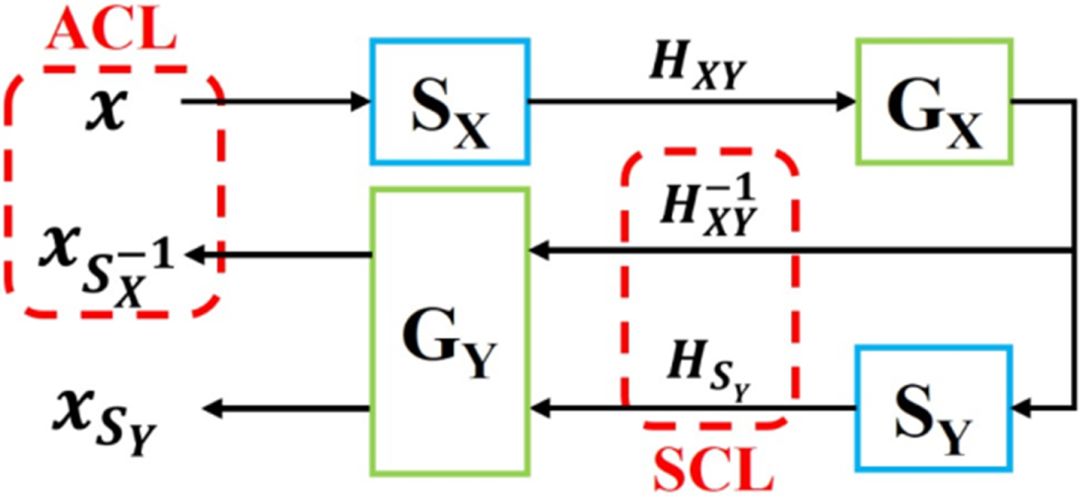
Fig .2.
Illustration of the disentangled cycle-consistency loss.
本文的总体框架是基于
CycleGAN
的,与
CycleGAN
不同的其中一个点是作者同时考虑了数据在几何形状和外观上的差异,还有一个不同点是
Cycle-consistency Loss
设计不同。在
CycleGAN
中
Cycle-consistency
Loss
的提出主要是为了解决S
ource Domain
和T
arget Domain
中数据没有一一配对而提出的一个损失函数,通过
Cycle-consistency
约束可以在一定程度上约束
Source Domain
到
Target Domain
的变换是能够保留主要信息的。本文的方法对几何变换进行了显性的建模,也就是说S
ource Domain
的图片到
Target Domain
的图片一般是会存在几何变换的,C
ycle
的过程就是将生成的图片再迁移回
Source Domain
,这个过程同样也会有几何形状和外观上的迁移,但是几何变换如果不加约束的话很难做到将图片的几何形状恢复原样,也就是说生成回来的图片与原图片可能会存在几个像素的偏移,而
Cycle-consistency Loss
一般是对整张图片做逐像素的
L1
或者
L2 Loss
,当生成回来的图片与原图有几个像素的偏移时
Loss
就会很大,影响网络的训练。
针对这个问题作者设计了一个
Disentangled Cycle-consistency Loss
,具体细节如
Fig. 2
所示,是几何变换网络用来获取从
X
(
Source Domain
)到
Y
(T
arget Domain
)的几何变换,表示从
X
到
Y
的几何变换矩阵,通过我们可以直接计算逆变换矩阵,通过逆变换矩阵可以直接将变换后的图片恢复原来的形状,那么在
Cycle
的过程我们就可以用直接替换网络预测的变换,那么这时生成回来的图片就不会与原来的图片有几何形状的差异,同时也可以用来指导的生成。通过分解后得到的
Loss
有两个部分,如下:
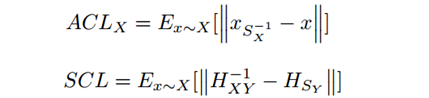
网络训练的损失函数主要包含三个部分,一个是
Disentangled Cycle-consistency Loss
,一个是
GAN
的对抗
Loss
,还有一个
I
dentity Loss
用来保留原图的主要信息,分别如下:
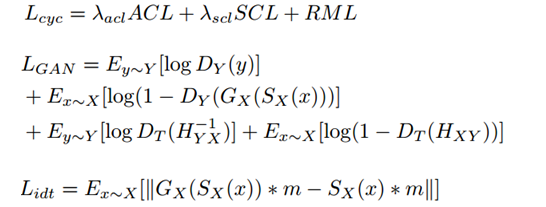
本文在自然场景文本检测和识别这两个任务上验证了
GA-DAN
的有效性,首先在自然场景文本检测任务上,作者用
ICDAR2013
数据集作为
Source Domain
,这个数据集主要包含一些规则的自然场景文本,然后分别以
ICDAR2015
和
MSRA-TD500
作为T
arget Domain
进行实验验证,这两个数据集与
ICDAR2013
数据集有较大的差异。检测网络使用的是
EAST[2].
TABLE 1. Scene text detection over the test images of the target datasets ICDAR2015 and MSRA-TD500.
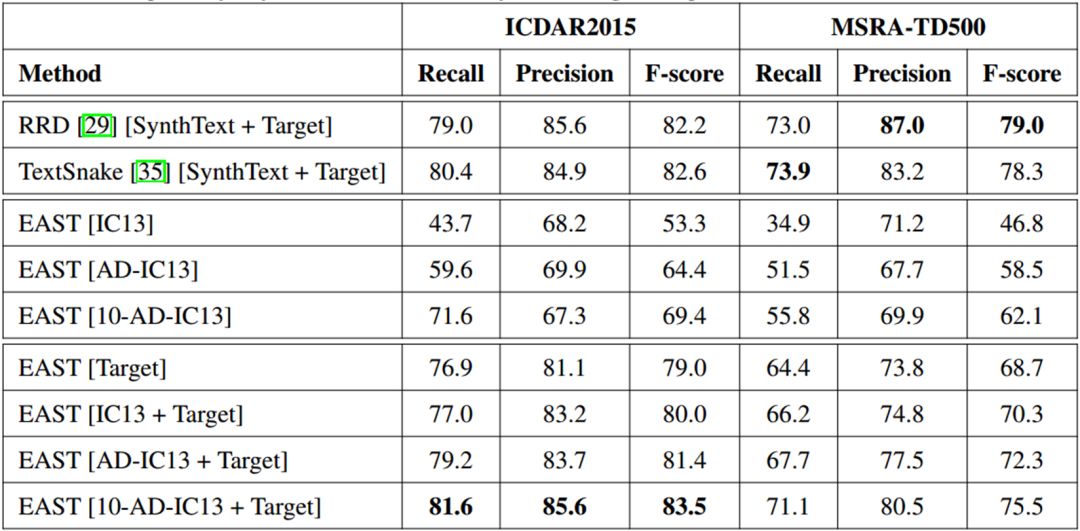
TABLE 1
是
GA-DAN
在检测任务上的实验结果,其中
EAST[IC13]
表示直接用
ICDAR2013
训练检测模型,然后分别用
ICDAR2015
和
MSRA-TD500
测试得到的结果。
EAST[AD-IC13]
表示使用
GA-DAN
以
ICDAR2013
数据集作为
Source Domain
,分别以
ICDAR2015
和
MSRA-TD500
作为
Target Domain
进行迁移的结果,一张
Source Domain
的图片只生成一张T
arget Domain
的图片。
可以看到,相比于直接用
ICDAR2013
训练,使用
GA-DAN
生成的图片训练检测模型检测结果有明显的提升,其中在
ICDAR2015
测试集上
F-score
有
11.1%
的提升,在
MSRA-TD500
测试集上
F-score
有
11.7%
的提升。
EAST[10-AD-IC13]
表示一张S
ource Domain
的图片生成
10
张T
arget Domain
的图片。可以看到,相比于只生成一张图片(
EAST[AD-IC13]
),检测效果有进一步的提升,从而也证明了
Multi-Modal Spatial Learning
的有效性。
TABLE 1
中
[Target]
表示用了T
arget Domain
的图片训练检测模型,可以看到使用
GA-DAN
生成的图片再加上T
arget Domain
的训练数据训练得到的检测模型甚至超过了一些比
EAST[2]
更加先进的检测模型,比如(
RRD[3]
和
TextSnake[4]
)。
Fig. 3
可视化了
GA-DAN
和其他D
omain Adaptation
方法生成图片的差异,可以看到
GA-DAN
生成的图片还是比较真实的。

Fig.3. Comparing GA-DAN with state-of-the-art adaptation methods.
TABLE 2. Scene text detection on the IC15 test images
(
comparison with other domain adaptation methods
).
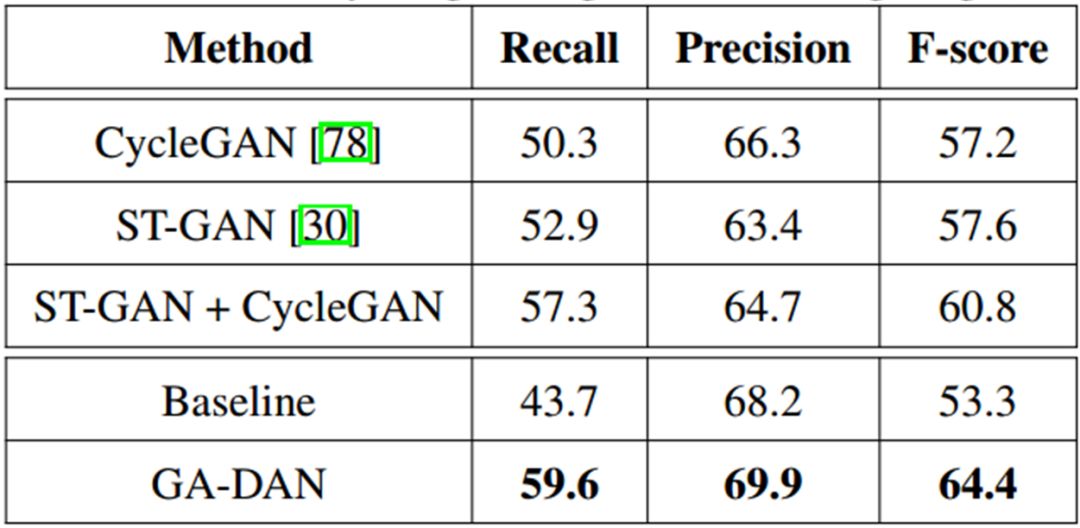
TABLE 2
对比了
GA-DAN
与其他D
omain Adaptation
方法的差异,其中
CycleGAN
是在外观上(A
ppearance
)进行迁移的方法,
ST-GAN
是在几何形状上(G
eometry
)进行迁移的方法,
ST-GAN+CycleGAN
是作者将这两个算法拼接起来。可以看到,用
GA-DAN
生成图片训练得到的检测器在检测结果上显著超过其他方法。就算是将
CycleGAN
和










