23年2月的论文“Composer: Creative and Controllable Image Synthesis with Composable Conditions“,来自阿里。
 最近在大数据上学习的大规模扩散生成模型能够合成令人难以置信的图像,但可控性有限。
这项工作提供了一种范式,允许灵活控制输出图像,如空间布局和调色板,同时保持合成质量和模型创意。
以合成性为核心思想,首先将图像分解为具有代表性的因素,然后以所有这些因素为条件训练扩散模型来重新合成输入。
在推理阶段,丰富的中间表示作为可组合元素工作,为可定制的内容创建带来了超大的设计空间(即,与分解因子数量成指数比例)。
值得注意的是,称之为Composer的方法支持各种级别的条件,例如作为全局信息的文本描述、作为局部指导的深度图和草图、用于低级别细节的颜色直方图等。
除了提高可控性外,Composer作为一个通用框架,在没有重新训练的情况下促进了广泛的经典生成任务。
最近在大数据上学习的大规模扩散生成模型能够合成令人难以置信的图像,但可控性有限。
这项工作提供了一种范式,允许灵活控制输出图像,如空间布局和调色板,同时保持合成质量和模型创意。
以合成性为核心思想,首先将图像分解为具有代表性的因素,然后以所有这些因素为条件训练扩散模型来重新合成输入。
在推理阶段,丰富的中间表示作为可组合元素工作,为可定制的内容创建带来了超大的设计空间(即,与分解因子数量成指数比例)。
值得注意的是,称之为Composer的方法支持各种级别的条件,例如作为全局信息的文本描述、作为局部指导的深度图和草图、用于低级别细节的颜色直方图等。
除了提高可控性外,Composer作为一个通用框架,在没有重新训练的情况下促进了广泛的经典生成任务。
如图所示是组合图像合成的概念:它首先将图像分解为一组基本成分,然后以高度的创造性和可控性重新组合一个新图像。为此,各种格式的组件在生成过程中充当扩散条件,并允许在推理阶段进行灵活的定制。
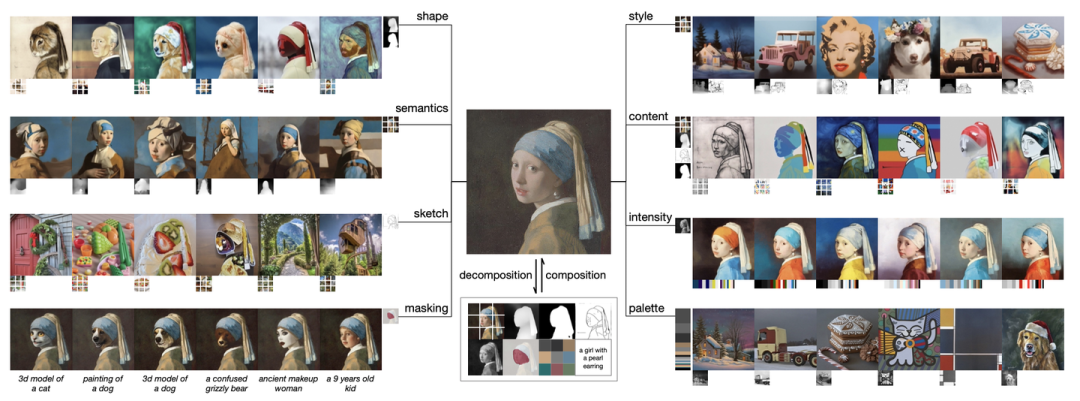 提出的框架包括:
一个分解阶段,图像被划分为一组独立的组件;
以及一个组成阶段,利用条件扩散模型重新组装部件。
提出的框架包括:
一个分解阶段,图像被划分为一组独立的组件;
以及一个组成阶段,利用条件扩散模型重新组装部件。
先说
分解
。将图像分解为解耦的表示,这些表示捕捉图像的各个方面。这项工作使用八种表示,都是在训练过程中动态提取的。
-
字幕:直接使用图像文本训练数据中的字幕或描述信息(例如,LAION-5B(Schuhmann2022))作为图像字幕。当标注不可用时,还可以利用预训练的图像字幕模型。用预训练的CLIP-ViT-L/14@336px模型(Radford2021)提取的句子和单词嵌入来表示这些字幕。
-
语义和风格:用预训练的CLIP-ViT-L/14@336px(Radford2021)模型提取的图像嵌入来表示图像的语义和风格,类似于unCLIP(Ramesh2022)。
-
颜色:用平滑的CIELab直方图来表示图像的颜色统计(Sergeyk2016)。将CIELab颜色空间量化为11个色调值、5个饱和度值和5个光照值,并用平滑sigma=10。根据经验,发现这些设置效果良好。
-
草图:用边缘检测模型(Su 2021),然后应用草图简化算法(Simo-Serra 2017)提取图像的草图。草图捕捉图像的局部细节,语义较少。
-
实例:用预训练的YOLOv5(Jocher2020)模型对图像进行实例分割,提取其实例掩码。实例分割掩码反映视觉目标的类别和形状信息。
-
深度图:用预训练的单目深度估计模型(Ranftl 2022)提取图像的深度图,该深度图大致捕捉图像的布局。
-
强度:引入原始灰度图像作为表示,迫使模型学习处理颜色的自由度。为了引入随机性,从一组预定义的RGB通道权重中均匀采样,以创建灰度图像。
-
掩码:引入图像掩码,使Composer能够将图像生成或操作限制在可编辑区域。用4通道表示,其中前3个通道对应于掩码RGB图像,而最后一个通道对应二值掩码。
应该注意的是,虽然这项工作使用了上述八个条件进行实验,但用户可以使用Composer自由定制条件。如图所示:(a) 图像变化。对于每个示例,第一列显示源图像,而随后的四列是源图像的变型,这些通过将Composer条件化为其表示的不同子集而产生。(b) 图像插值。第一行是对源图像(第一列)和目标图像(最后一列)之间的所有分量进行插值的结果。剩下行代表源图像的一些组件(即左边列出)保持不变的结果。
 再说
组成
。用扩散模型从一组表示中重新组合图像。具体而言,利用GLIDE(Nichol 2021)架构并修改其调节模块。探索了两种不同的机制根据表示调节模型:
再说
组成
。用扩散模型从一组表示中重新组合图像。具体而言,利用GLIDE(Nichol 2021)架构并修改其调节模块。探索了两种不同的机制根据表示调节模型:
-
全局调节:对于包括CLIP语句嵌入、图像嵌入和调色板在内的全局表示,将它们投影并添加到时间嵌入中。此外,将图像嵌入和调色板投影到八个额外的tokens中,并与CLIP单词嵌入连接起来,然后将其用作GLIDE中交叉注意的上下文,类似于unCLIP(Ramesh2022)。由于条件是可加性的,或者可以在交叉注意中选择性地屏蔽,因此在训练和推理过程中放弃条件,或者引入新的全局条件是很简单的。
-
局部调节:对于包括草图、分割掩码、深度映射、强度图像和掩码图像在内的局部表示,用堆叠卷积层将它们投影到与噪声潜信号具有相同空间大小的均匀维嵌入中。然后,计算这些嵌入的总和,并在将结果输入UNet之前将其连接到噪声潜信号。由于嵌入是加性的,因此很容易适应缺失的条件或引入新的局部条件。
设计一种联合训练策略至关重要,该策略使模型能够学习从各种条件组合中解码图像。作者对几种配置进行了实验,并确定了一种简单而有效的配置,其对每个条件使用0.5的独立放弃概率,放弃所有条件的概率为0.1,对保留所有条件使用0.1%的概率。对强度图像使用0.7的特殊放弃概率,因为其包含了关于图像的绝大多数信息,并且在训练过程中可能会减轻其他情况的重量。
基础扩散模型生成64×64分辨率的图像。为了生成高分辨率图像,训练两个无条件扩散模型进行上采样,分别将图像从64×64提升到256×256、从256×256提升到1024×1024分辨率。上采样模型的架构是从unCLIP(Ramesh2022)修改而来的,在unCLIP中,低分辨率层使用更多的通道,并引入自注意块来扩大容量。还介绍了一种可选的先验模型(Ramesh2022),该模型从字幕中生成图像嵌入。根据经验发现,对于某些条件组合,先验模型能够提高生成图像的多样性。










