
环境:Python3.6
模块:requests、beautifulsoup4
步骤
1.获取网页源码
用浏览器的F12可以看到网页的源码,但我们现在要用python这样做。

如果没问题的话结果会是这样类似

这些就是网页的源码了。
2.寻找所需信息
切换浏览器,右键‘查看网页源代码’,可以发现有很多这样的信息
<
li
>
<
a
href
=
"http://www.mzitu.com/89334"
target
=
"_blank"
>
<
img
width
=
'236'
height
=
'354'
class
=
'lazy'
alt
=
'我是标题我是标题我是标题我是标
那么我们只需要提取这些东西就可以了…but:我写不出这么复杂的正则!!!没关系,我们的神器BeautifulSoup要上场了!
我们的步骤是:①将获取的源码转换为BeautifulSoup对象②搜索需要的数据

这样就找到了当页所有套图的标题

3.进入下载
点进一个套图之后,发现他是每个页面显示一个图片。

比如
http://www.mzitu.com/26685
是某个套图的第一页,后面的页数都是再后面跟/和数字
http://www.mzitu.com/26685/2
(第二页),那么很简单了,我们只需要找到他一共多少页,然后用循环组成页数就OK了。

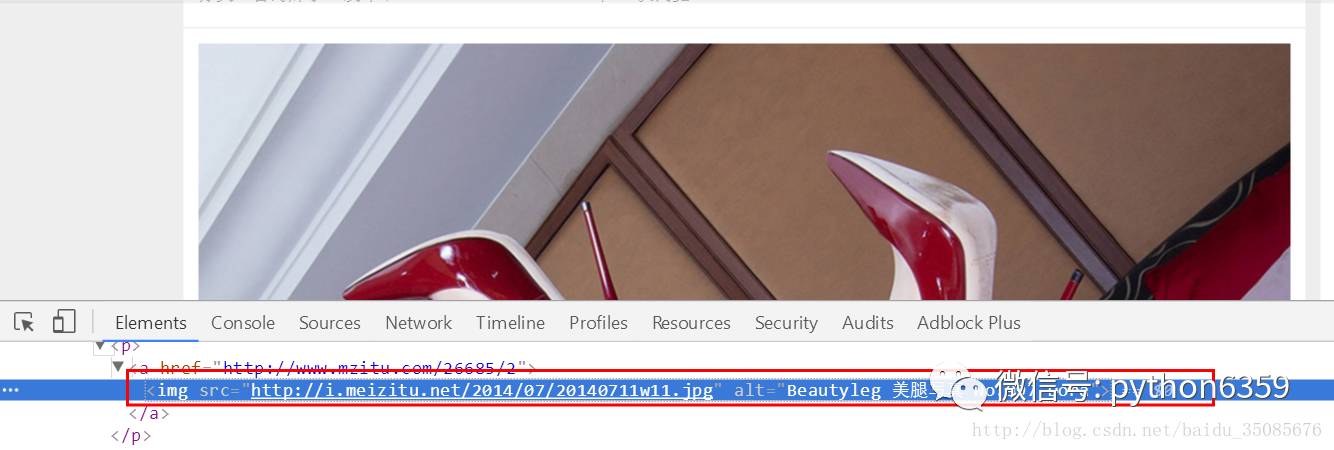
好了,那么我们接下来就是进行寻找图片地址并且保存了,右键妹纸图片,“检查”可以发现
<
img
src
=
"http://i.meizitu.net/2014/07/20140711w11.jpg"
alt
=
"Beautyleg 美腿写真 No.997 Dora"
>
那么这就是图片的具体地址了,那么我们的目的就要达成,保存它。
不出意外你脚本所在的地方会有12张图片
4.批量下载
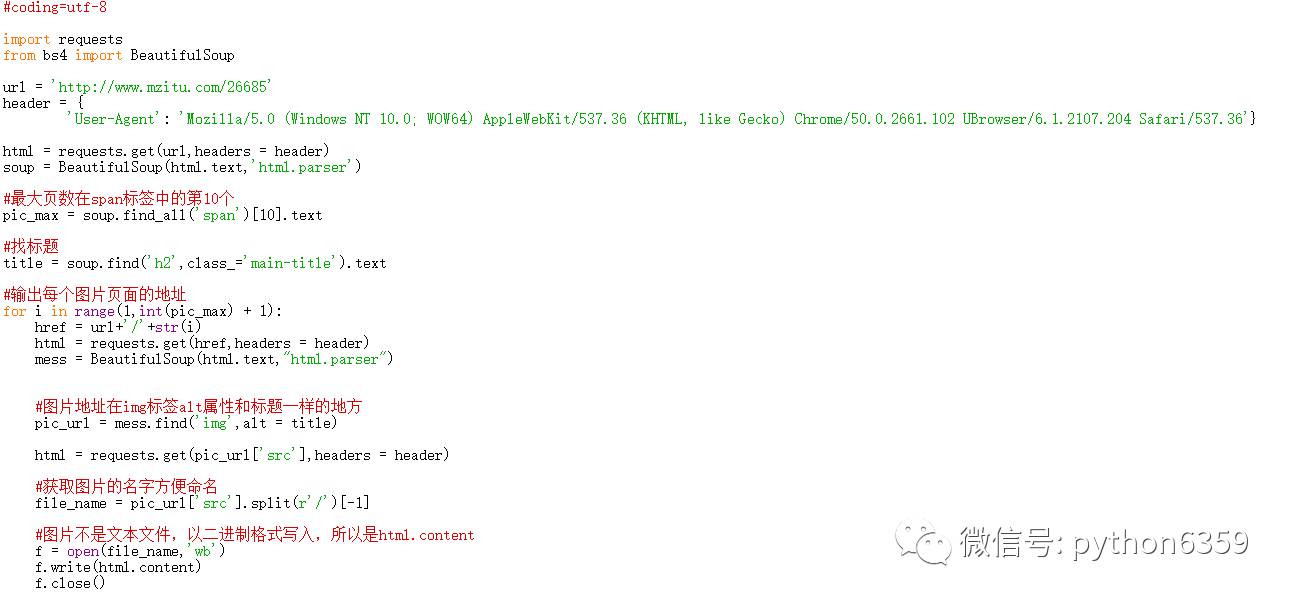
上面讲了如何下载一个套图,其实所有的套图下载只是加上两重循环。成品如下:
#coding=utf-8
import requests
from bs4 import BeautifulSoup
import os
import sys
'''
#安卓端需要此语句
reload(sys)
sys.setdefaultencoding('utf-8')
'''
if(os.name == 'nt'):
print(u'你正在使用win平台')
else:
print(u'你正在使用linux平台')
header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 UBrowser/6.1.2107.204 Safari/537.36'}
#http请求头
all_url = 'http://www.mzitu.com'
start_html = requests.get(all_url,headers = header)
#保存地址
path = 'D:/mzitu/'
#找寻最大页数
soup = BeautifulSoup(start_html.text,"html.parser")
page = soup.find_all('a',class_='page-numbers')
max_page = page[-2].text
same_url = 'http://www.mzitu.com/page/'
for n in range(1,int(max_page)+1):
ul = same_url+str(n)
start_html = requests.get(ul, headers=header)
soup = BeautifulSoup(start_html.text,"html.parser")
all_a = soup.find('div',class_='postlist').find_all('a',target='_blank')
for a in all_a:
title = a.get_text() #提取文本










