本文是Spark NLP Library中各annotator系列中的第2篇文章,
介绍Spark NLP中是如何使用Annotator和Transformer
。如果你想更多的学习Spark NLP及对应的概念,请先阅读下述文章:
Introduction to Spark NLP: Foundations and Basic Components (Part-I)https://medium.com/spark-nlp/introduction-to-spark-nlp-foundations-and-basic-components-part-i-c83b7629ed59
本文主要是作为上篇文章的延续。
在机器学习中,常见的一种做法是运行一系列的算法来处理和学习数据。这种算法序列常被称作做Pipeline。
Pipeline具体来说是一个多阶段的序列,每个阶段由一个Transformer或者Estimator组成。各个阶段按顺序执行,并将输入的DataFrame转换和传递给下一个阶段,数据如此按序的在pipeline中传递。每个阶段的transform()方法函数更新这组数据集并传递到下一阶段。因为有了pipeline,训练数据和测试数据会通过确保一致的特征处理环节。
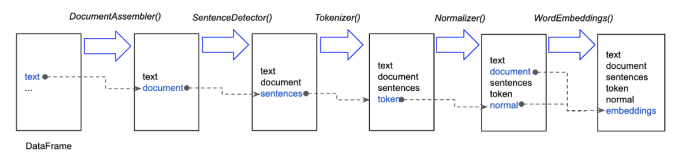
每个使用的annotator 会在pipeline中的这个data frame新添一列。
我们现在来看一下Spark NLP是如果使用Annotator和Transformer完成上述过程。假如我们需要将如下几个环节逐一施加在data frame上:
下面是通过Spark NLP实现这个pipeline的代码:
1from pyspark.ml import Pipeline
2
3document_assembler = DocumentAssembler()\ .setInputCol(“text”)\ .setOutputCol(“document”)
4
5sentenceDetector = SentenceDetector()\ .setInputCols([“document”])\ .setOutputCol(“sentences”)
6
7tokenizer = Tokenizer() \ .setInputCols([“sentences”]) \ .setOutputCol(“token”)
8
9normalizer = Normalizer()\ .setInputCols([“token”])\ .setOutputCol(“normal”)
10
11word_embeddings=WordEmbeddingsModel.pretrained()\ .setInputCols([“document”,”normal”])\ .setOutputCol(“embeddings”)
12
13nlpPipeline = Pipeline(stages=[ document_assembler, sentenceDetector, tokenizer, normalizer, word_embeddings, ])
14
15pipelineModel = nlpPipeline.fit(df)
接下来我们加载了一组数据到这个pipeline中,看一下模型如何工作。
 Dataframe样本(5452行)
Dataframe样本(5452行)
然后运行上述pipeline,我们会得到一个训练好的模型。之后我们用它转换整个DataFrame。
1result = pipelineModel.transform(df)
2result.show()
转换前20行数据用了501毫秒;转换整个data frame共用了11秒。
1%%timeresult = pipelineModel.transform(df).collect()
2>>>CPU times: user 2.01 s, sys: 425 ms, total: 2.43 s
3Wall time: 11 s
如果我们想把这个pipeline保存到硬盘,然后调用它转换一行文字,在线转换时间会多长呢?
1from pyspark.sql import Row
2text = "How did serfdom develop in and then leave Russia ?"
3line_df = spark.createDataFrame(list(map(lambda x: Row(text=x), [text])), ["text"])
4%time result = pipelineModel.transform(line_df).collect()
5
6>>>CPU times: user 31.1 ms, sys: 7.73 ms, total: 38.9 msWall time: 515 ms
转换一行短文字的时间也是515毫秒!几乎是和之前转换20行的时间一致。所以说,效果太好。实际上,类似的情况也发生在使用分布式处理小数据的时候。分布式处理和云计算主要是用来处理大数据,而使用Spark来处理小型数据其实是杀鸡用牛刀。
实际上,由于它内部的机制和优化后的构架,Spark仍适用于中等大小单机可处理的数据。但不建议使用Spark来处理仅仅是几行的数据, 除非使用Spark NLP。
打个比方,Spark 好像一个火车和一个自行车赛跑。自行车会在轻载的时候占上风,因为它更敏捷、提速更快,而重载的火车可能需要一段时间提速,但最终还是会速度更快。
所以,如果我们想要预测的时间更快该怎么办呢?
使用LightPipeline。
LightPipeline
LightPipelines 是Spark NLP对应的Pipeline, 等同于Spark ML Pipeline, 但是用于处理更小的数据。它们适用于小数据集、调试结果,或者是对一次性服务API请求的训练或预测。
Spark NLP LightPipelines 是将Spark ML Pipelines 转换成了一个单机但多线程的任务,对于小型数据(不大于5万个句子)速度会提升10倍。
这些Pipeline的使用方法是插入已训练(已拟合)的模型,然后会标注纯文本。我们都不需要把输入文字转换成Dataframe就可以输入pipeline,虽然pipeline当初是使用Dataframe作为输入。这个便捷的功能适用于使用已训练的模型对少数几行文字进行预测。
1from sparknlp.base import LightPipeline
2LightPipeline(someTrainedPipeline).annotate(someStringOrArray)
下面是一些LightPipelines可用的方法函数。我们还可以用字符列表作为输入文字。
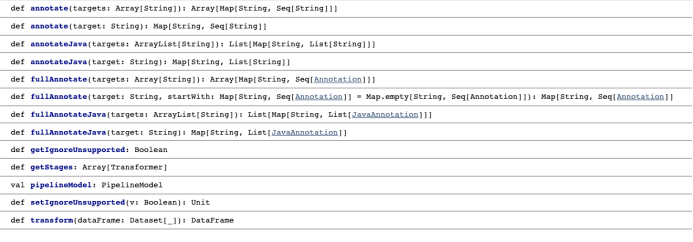 https://nlp.johnsnowlabs.com/api/#com.johnsnowlabs.nlp.LightPipeline
https://nlp.johnsnowlabs.com/api/#com.johnsnowlabs.nlp.LightPipeline
我们可以很方便的创建LightPipelines,也不需要处理Spark Datasets。LightPipelines运行的也很快,而且在驱动节点工作时可执行并行运算。下面是一个应用的例子:
1from sparknlp.base import LightPipeline
2lightModel = LightPipeline(pipelineModel, parse_embeddings=True)
3%time lightModel.annotate("How did serfdom develop in and then leave Russia ?")
4>>>
5CPU times: user 12.4 ms, sys: 3.81 ms, total: 16.3 ms
6Wall time: 28.3 ms
7{'sentences': ['How did serfdom develop in and then leave Russia ?'],
8 'document': ['How did serfdom develop in and then leave Russia ?'],
9 'normal': ['How',
10 'did',
11 'serfdom',
12 'develop',
13 'in',
14 'and',
15 'then',
16 'leave',
17 'Russia'],
18 'token': ['How',
19 'did',
20 'serfdom',
21 'develop',
22 'in',
23 'and',
24 'then',
25 'leave',
26 'Russia',
27 '?'],
28 'embeddings': ['-0.23769 0.59392 0.58697 -0.041788 -0.86803 -0.0051122 -0.4493 -0.027985, ...]}
29
这个代码用了28毫秒!几乎是使用Spark ML Pipeline时的20倍速度。
上面可以看出,annotate只返回了result的属性。既然这个嵌入向量数组储存在embedding属性的WordEmbeddingModel标注器下,我们可以设置parse_embedding = True 来分析嵌入向量数据。否则,我们可能在输出中只能获得嵌入向量的分词属性。关于上述属性的更多信息见以下连接:
https://medium.com/spark-nlp/spark-nlp-101-document-assembler-500018f5f6b5
如果我们想获取标注的全部信息,我们还可以使用fullAnnotate()来返回整个标注内容的字典列表。
1result = lightModel.fullAnnotate("How did serfdom develop in and then leave Russia ?")
2>>>
3[{'sentences': [],
4 'document': [base.Annotation at 0x149b5a320
>],
5 'normal': [base.Annotation at 0x139d9e940>,
6 base.Annotation at 0x139d64860>,
7 base.Annotation at 0x139d689b0>,
8 base.Annotation at 0x139dd16d8>,
9 base.Annotation at 0x139dd1c88>,
10 base.Annotation at 0x139d681d0>,
11 base.Annotation at 0x139d89128>,
12 base.Annotation at 0x139da44a8>,
13 base.Annotation at 0x139da4f98>],
14 'token': [base.Annotation at 0x149b55400>,
15 base.Annotation at 0x139dd1668>,
16 base.Annotation at 0x139dad358>,
17 base.Annotation at 0x139d8dba8>,
18 base.Annotation at 0x139d89710>,
19 base.Annotation at 0x139da4208>,
20 base.Annotation at 0x139db2f98>,
21 base.Annotation at 0x139da4240>,
22 base.Annotation at 0x149b55470>,
23 base.Annotation at 0x139dad198>],
24 'embeddings': [base.Annotation at 0x139dad208>,
25 base.Annotation at 0x139d89898>,
26 base.Annotation at 0x139db2860>,
27 base.Annotation at 0x139dbbf28>,
28 base.Annotation at 0x139dbb3c8>,
29 base.Annotation at 0x139db2208>,
30 base.Annotation at 0x139da4668>,
31 base.Annotation at 0x139dd1ba8>,
32 base.Annotation at 0x139d9e400>]}]
fullAnnotate()返回标注类型中的内容和元数据。根据参考文档,这个标定类型有如下属性:
参考文档:
https://nlp.johnsnowlabs.com/api/#com.johnsnowlabs.nlp.Annotation
1annotatorType: String,
2begin: Int,
3end: Int,
4result: String, (this is what annotate returns)
5metadata: Map[String, String],
6embeddings: Array[Float]
1result[0]['sentences'][0].begin
2>> 0
3result[0]['sentences'][0].end
4>> 49
5result[0]['sentences'][0].result
6>> 'How did serfdom develop in and then leave Russia ?'










