2 月 18 日,DeepSeek 和月之暗面(Moonshot AI)几乎在同一时间发布了各自最新的研究成果,巧合的是,两篇论文的主题高度一致——都聚焦于改进 Transformer 架构中最核心的注意力机制,旨在提升其处理长上下文的能力并降低计算成本。由此可见,大家都在争相研究如何让 AI 更好地处理长文本,这不仅说明了行业对高效处理长文本的需求非常迫切,也是技术创新竞争进入白热化的缩影。
更有趣的是,两家公司的技术派明星创始人都亲自参与了研究,他们的名字分别出现在各自的论文和技术报告中,此举引发了外界的强烈关注。
2017 年,Transformer 架构被谷歌提出后便在技术圈内掀起热潮,它的出现被认为是 AI 发展史上的重要里程碑。但如此厉害的注意力机制,却有一个问题,它计算起来的复杂程度是和输入序列的长度是相关的,具体来说计算复杂度是输入序列长度 n 的平方,写成公式就是 O (n²)。
这就导致了在处理长的文本序列时,比如长度超过 1 万个 token 的文本,计算所需要的成本会大幅增加,而且还会占用很多内存。这就成了限制模型进一步扩大规模、提升能力的主要障碍。
DeepSeek 和月之暗面这两个研究团队都在想办法解决这个问题,他们用的方法叫稀疏注意力(Sparse Attention)。稀疏注意力的主要思路就是,在进行注意力计算的时候,减少那些没有必要的交互计算。这样一来,计算复杂度就能从原来的 O (n²) ,降低到 O (nlogn),甚至能达到 O (n)。而且,在降低复杂度的同时,还尽量让模型保持对长文本上下文的理解和处理能力。
那么,这两篇论文都具体说了什么?
首先是 DeepSeek 的论文,这篇论文名为《Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention》,主要讲述了 DeepSeek 提出的一种可原生训练的稀疏注意力机制 NSA(英文全称:Natively Trainable Sparse Attention,简称 NSA),能够通过动态分层稀疏策略,结合粗粒度 token 压缩和细粒度 token 选择,实现了对长上下文的高效建模。简而言之,就是能通过减少不必要的计算,让模型在处理长文本时既快又好。

长上下文建模是指让语言模型能够理解和处理很长的文本(比如一本书或一篇长文章)。这对于下一代语言模型非常重要,因为很多任务需要模型记住和理解大量的信息。但现在的问题是,现有的标准注意力机制(比如 Transformer 中的注意力机制)在处理长文本时计算量非常大,导致训练和推理速度变慢,成本也很高。
稀疏注意力是一种改进的方法,它通过减少不必要的计算来提高效率,同时尽量保持模型的能力。NSA 就是一种新的稀疏注意力方法,它通过两个关键创新来实现高效的长上下文建模,具体而言:
算法优化
:NSA 机制设计了一种平衡计算强度的算法,并且针对现代硬件进行了优化。简单来说,它通过减少不必要的计算步骤,让模型在保持性能的同时跑得更快。这就像在读一本很厚的书时,不再需要逐字逐句地读,而是通过快速浏览章节标题和重点段落来理解主要内容。NSA 就像这种高效的阅读方式,它只关注重要的部分,跳过了不重要的细节,从而节省了时间。
端到端训练
:NSA 还允许模型从头到尾(从输入到输出)进行训练,而不需要在中间增加额外的计算步骤。这样既减少了训练时间,又不会降低模型的表现。
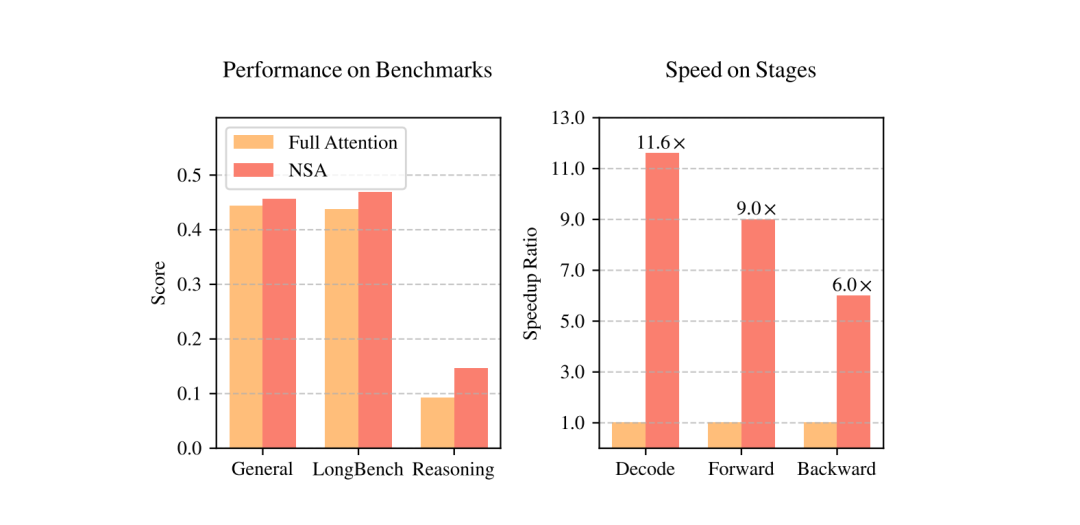
实验表明,使用 NSA 训练的模型在多个任务上(比如阅读理解、长文本生成等)表现得和全注意力模型一样好,甚至更好。而且,在处理非常长的文本(比如 64k 长度的序列)时,在解码、前向传播和后向传播过程中分别实现了 2.5 倍、3.1 倍和 2.8 倍的加速,同时在多个长上下文任务(如长文本生成、问答和指令推理)中保持了与全注意力模型相当甚至更好的性能。
也就是说,NSA 通过减少不必要的计算,让模型在处理长文本时既快又好。
下图是全注意力模型(Full Attention)与 DeepSeek NSA 模型在性能和效率上的对比:
同一天,月之暗面提交的论文名为《MoBA: Mixture of Block Attention for Long-Context LLMs》,也是一篇针对模型架构展开的讨论。
月之暗面的论文中提出了一个在核心思想上与 NSA 较为一致的架构:
注意力混合架构 MoBA
。(英文全称:Mixture of Block Attention,简称 MoBA)。

月之暗面同样阐述了目前世面上主流 AI 语言模型在处理长文本时,面临一个很大的问题:随着文本变长,计算量会急剧增加。这是因为传统的注意力机制需要计算每个词与其他所有词的关系,导致计算复杂度呈二次增长(比如文本长度增加 10 倍,计算量可能增加 100 倍)。这不仅让模型变慢,还增加了成本。
而现有方法在应对上述问题时都有局限性,比如:
因此,月之暗面提出了一种新方法,叫做混合块注意力(MoBA)。它的核心思想是:让模型自己决定该关注哪些部分,而不是人为规定。这种方法借鉴了“专家混合(MoE)”的思想,就像让一群专家分工合作,每个人负责自己擅长的部分。
MoBA 的优势主要有两点:一是可以灵活切换:MoBA 可以根据需要,自动在全注意力和稀疏注意力之间切换。全注意力适合处理复杂任务,而稀疏注意力适合处理长文本,效率更高;二是高效且不影响性能:MoBA 在保持模型性能的同时,显著降低了计算量。比如在处理长文本时,它可以跳过一些不重要的部分,只关注关键信息,从而节省时间和资源。
目前,MoBA 已经被用在 Kimi(一个 AI 助手)中,帮助它更好地处理长文本请求。比如,当你让 Kimi 总结一本长篇小说时,MoBA 可以让它快速找到关键情节,而不需要逐字逐句地分析整本书。
下图是切注意力混合(MoBA)示意图:
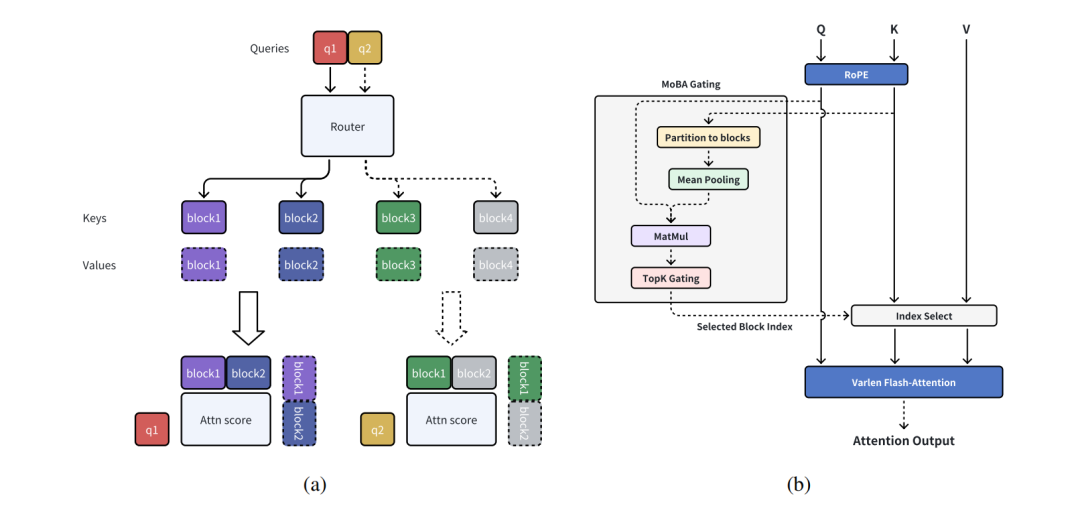
(a) 切块注意力混合(MoBA)的一个实例;(b)将块注意力混合(MoBA)集成到快速注意力机制(Flash Attention)中。
那与全注意力机制相比,效果如何?下图展示了 MoBA(蓝色线条)和全注意力机制(红色线条)在不同方面的对比情况:
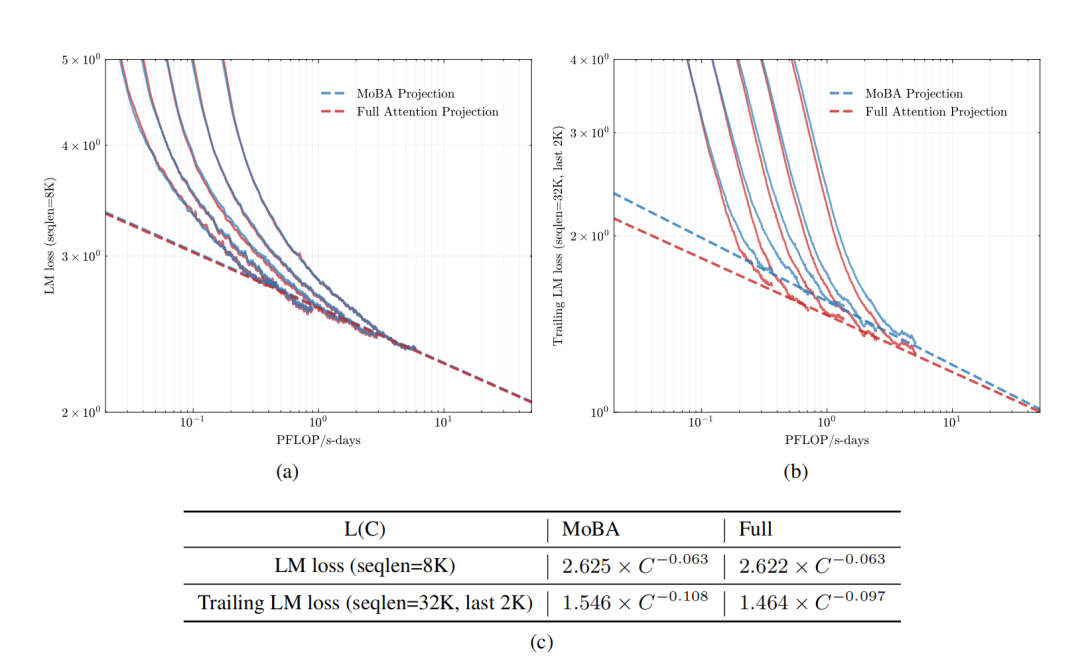
(a) 验证集上的语言模型损失(序列长度 = 8K);(b) 验证集上的尾随语言模型损失(序列长度 = 32K,最后 1K 个标记);(c) 拟合的缩放定律曲线。
-
(a) 子图:展示了在序列长度为 8K 时,验证集上的语言模型损失随着 PFLOP/s - days(一种计算量单位)的变化趋势。可以看到随着计算量的增加,两种方法的语言模型损失都在下降,且 MoBA 和全注意力机制的曲线较为接近。
-
(b) 子图:显示了在序列长度为 32K 且只关注最后 1K 个标记时,验证集上的尾随语言模型损失随 PFLOP/s - days 的变化。同样,随着计算量上升,损失下降,两者曲线有相似的下降趋势。
-
(c) 表格:给出了拟合的缩放定律曲线公式。这些公式可以用于预测在不同计算资源(C)下的损失情况。
也就是说,在不同序列长度和损失计算方式下,MoBA 和全注意力机制在计算量与损失关系上表现出一定的相似性。
事实上,这不是两家公司第一次中心思想“大撞车”。
在 DeepSeek 发布 R1 时,Kimi 也难得地公开了 K1.5 的技术报告。要知道,Kimi 这家公司以前并不太喜欢对外展示自己的技术思路,但这次却破例了。有意思的是,这两篇论文的目标非常相似,都是想通过强化学习(RL)来提升 AI 的推理能力。
如果你仔细对比这两篇论文,会发现 K1.5 的报告在“如何训练一个推理模型”这个问题上,讲得更详细、更深入。无论是提供的信息量,还是技术细节的丰富程度,K1.5 都更胜一筹。不过,由于 DeepSeek 的 R1 发布后吸引了更多人的关注,K1.5 的论文反而被“冷落”了,没有得到应有的讨论和重视。
值得注意的是,连 OpenAI 也注意到了这两家总是思想撞车的 AI 明星创企。OpenAI 在其关于 o 系列模型推理能力讲解的论文里提及 DeepSeek - R1 和 Kimi K1.5。
DeepSeek - R1 通过独立研究运用思维链学习(COT)方法,实现了在数学解题和编程挑战中的优异表现。
在数学解题中,这种方法可以帮助模型更好地理解问题的逻辑结构,从已知条件逐步推导得出正确答案。例如在解决几何证明题时,模型可以按照思维链的步骤,先识别图形的性质和已知条件,然后运用相应的定理和规则进行推理,最终完成证明。
在编程挑战中,思维链学习使模型能够更清晰地规划代码结构,理解不同代码片段之间的逻辑关系,从而编写出更高效、准确的代码。
Kimi K1.5 同样通过独立研究采用思维链学习(COT)方法,在数学解题与编程挑战提高了模型效果。
而 OpenAI 选择 DeepSeek - R1 和 Kimi k1.5 作为对比的推理模型,一方面体现了这两个模型在推理能力已经得到了行业巨头的认可;另一方面,这也反映出思维链学习(COT)方法在提升模型推理能力方面的有效性和重要性得到了广泛关注。
这次两家又一起“杠”上了模型架构,或许从侧面说明了,我们距离下一步模型创新又近了一步。
声明:本文为 InfoQ AI前线整理,不代表平台观点,未经许可禁止转载。
参考链接:
https://arxiv.org/html/2502.11089v1
https://github.com/MoonshotAI/MoBA?tab=readme-ov-file










