大家好,时隔……(我也不知道到底时隔多久了),媛子终于从精品案例的海洋中探出头来,又出没在“多元剑法”系列(戳这里看其他多元剑法招式)。
今天想跟大家分享的是又一著名招式——判别分析。“判别分析”这个不明觉厉的名字通常和“分类分析”成对出现,有一些熊孩子就问过,这两者到底有什么联系,它们又跟聚类分析有什么不同?
媛子有个两岁的女儿,叫小橙子。在橙子一岁的时候,我发现她可以准确地说出马路上见到的小动物,这只是小猫,那只是小狗。但是其实爸爸妈妈只是陪她看过卡通片或者绘本上面的小动物,告诉他这里面哪些是小猫,哪些是小狗,她并没有见过现实中的猫猫狗狗。那么小孩子为什么会有这种能力,可以从看过的卡通片里面的小动物中,学习到小猫和小狗的区别,并准确将一只从未见过的小动物归类到“小猫”或“小狗”的行列呢?

再比如,当一个人向银行贷款买房买车的时候,作为银行的借贷员,你需要根据这个人的个人信息、贷款记录等历史数据判断这个人的还款能力。简单来说,你需要通过以上信息将这个人归为“可以按时还款,非违约”和“不能按时还款,违约”这两组中的一组。那么如何能尽量准确地分组呢?

又或者,医生在诊断重大疾病的时候,通常都有一堆的指标作为参考。他们会根据这些指标对病人疾病的所属类别进行一个判断,然后对症治疗。那么如果从数据本身出发,怎样从过去病人的历史数据中总结规律,从而对新病人的病情判断进行指导呢?
上述的这些例子背后所遵从的数据分析的原理其实都是相通的——我们分两步解决这些问题:首先需要有一些“前人的经验”,即历史数据,在这些数据中清晰地知道每个个体所属的类别。所以,这第一步就是从这些信息中,总结出各个类别彼此之间的差异,找到区别各个类别最有效的“分类规则”;第二步就是对于一个新来的个体,虽然并不事先知道它是属于哪个类别的,但是可以根据第一步找到的“分类规则”,将这个个体分类到所有类别中的某一个。这两个步骤中的第一步,在多元分析里面,就称之为“判别分析”(discriminant analysis),而第二步,就是“分类”(classification)。判别分析是描述性的,而分类分析是推断性的。当然,这二者并不是可以严格割离的,因为判别分析的主要目的就是进一步进行分类,而分类分析通常都要有判别分析的结果做基础。我们这一次就先讨论第一步,判别分析。
需要注意的是,这里我们明确地知道在历史数据中,每个个体分别属于哪一个类别(橙子在她看过的卡通片里,是知道哪些是小猫,哪些是小狗的)。而对于每一个新个体而言,它也有一个明确的类别属性,只是我们暂时并不知道,因此需要用已有的信息去推断。这就好像有个无所不知的“上帝”在监督着的分类,所以习惯上把这种分类分析称为“监督式学习”(Supervised learning)。之后我们还会讲到没有上帝监督的情况,叫做“无监督式学习”(Unsupervised learning),例如聚类分析。
我们刚刚提到了,判别分析是指,从历史数据中总结各个类别的规律,建立“分类规则”。橙子看到的卡通片或者绘本里面的小动物,就是她所收集到的“历史数据”。当她看到很多只小猫小狗之后,就会无形之中总结出一种规律。比如,耳朵大的通常是狗;个头很大的通常也是狗;体毛较长的多是小狗;尾巴细长的更多的是小猫……这些信息便构成了一组多元数据,包括“耳朵大小”、“个头大小”、“体毛长度”、“尾巴特征”等变量。
如果按一元数据的处理思想,只将里面的某一个变量单独挑出来,比如“耳朵大小”,用它来区分猫和狗,这显然不是一种明智的选择,毕竟有很多狗的耳朵也像猫一样小。所以,其实橙子脑海中默认的方式是,把这些变量综合考虑,得到一个“综合指标”来刻画猫与狗的不同。
这种“综合指标”的获得在统计上有很多种方式,这里主要介绍一种像主成分分析(戳这里)一样,对原始变量求“线性加权平均”的规则形式。这种方法是由费歇尔(R.A. Fisher)最早提出的,所以称它为“Fisher线性判别法则“(Fisher’s linear discriminant analysis, LDA)。
比如在天气预报中,根据经验,今天和昨天的湿温差和气温差是关于预测明天下雨或不下雨的两个重要因素。那么如何利用这两个因素来得到晴天和雨天的费歇尔线性判别法则,并用它来进行以后天气的预报呢?(当然,这个例子只是用来展示判别分析的方法,如果真的用它来做天气预报肯定是图样图森破了)
现在假设有如下10天的历史数据可供使用:(数据来源见[4])
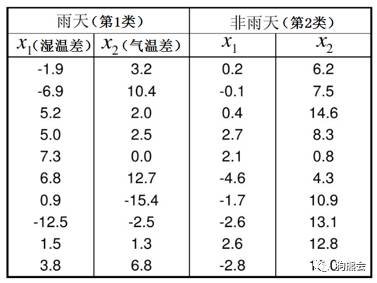
其中x1和x2分别是该样本点获得时前两天的湿温差及气温差,而该样本点收集当天是否下雨决定了它属于第1类(雨天组)还是第2类(非雨天组)。将这组多元数据画成下面这种散点图,并标明每个点来自的组别:
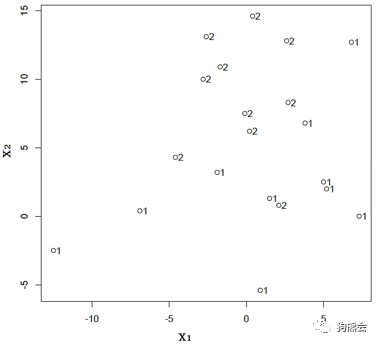
从图中可以看出,无论单独使用湿温差x1(也就是只考虑上述散点的横坐标的值)还是气温差x2(只考虑纵坐标),都无法将下雨组和不下雨组很好地分离开。但如果仔细观察这些散点,就会发现其实可以用一条直线将两组较好地分开(比如下图中红线所示),其中雨天(第1类)基本集中在红线之下,而非雨天(第2类)反之:
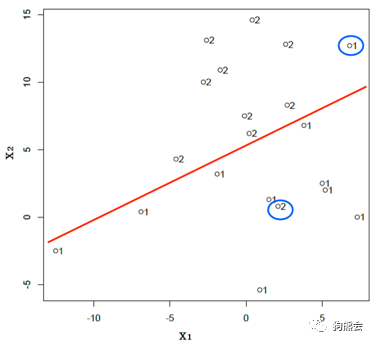
当然,我们无法做到完美,总是有一些点(比如上图中蓝色圈内的点)无法被准确地分到它本该属于的组别——橙子在辨认小猫小狗的时候还是有可能出错。但我们所能够做到的就是,找到的一个规则,使得用它分辨错误的概率在所有类似的分类规则中最小,或者说使得两组数据在这个规则下分离得最开。
那么怎样找到这个规则呢?
由于我们的目标是用一条分割线将两组数据尽量分得越开越好,用几何图形表示就是在如下这条与分割线垂直的方向(下图紫色直线)上,两组数据在该方向上的投影分离得越开越好:
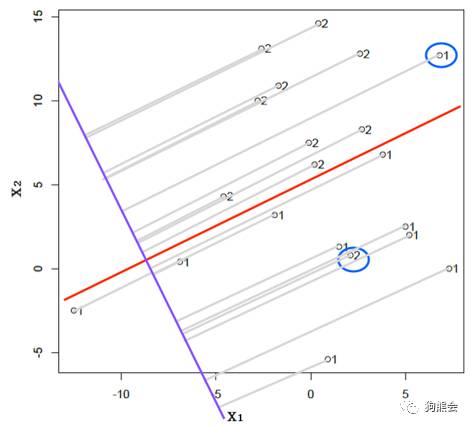
所以,Fisher判别法则给出的结果其实并不是分割线本身(图中红色直线),而是跟它垂直的投影线(图中紫色直线)。而由于这里所使用的判别法则是线性的,所以对应的分割线和投影线均为直线,而不是曲线或其他图形。学过几何的朋友应该知道,在坐标系中的直线可以表示为横纵坐标的线性函数ax1+bx2的形式。所以,这里的任务就是寻找针对投影线的系数估计a和b。在这个例子中,根据软件求得的a和b分别为a=-0.104, b=0.225。也就是说,可以根据湿温差和气温差的线性组合建立一个新的综合指标:-0.104*湿温差+0.225*气温差,用这个指标就可以将下雨组和不下雨组很好地分离开来。确定了这个新的指标,即紫色投影线之后,红色分割线的方向也一目了然了——就是与投影线垂直的方向。
对于橙子而言,根据费歇尔判别法则来区分猫和狗,就是应用耳朵大小、个头大小、体毛长度等变量的线性组合来作为她的规则。当然,判别法则不只有费歇尔线性法则一种,例如还可以用曲线来作为判别函数。在这里就不再涉及细节。
判别分析显然不只可以用到分辨小动物和天气预报中,在商业领域有更加广泛的应用。例如征信分析,在大数据时代下数据导向的互联网征信领域,当需要判断某客户的贷款审批是否予以通过时,所参考的历史数据中将会包含历史借款人的诸多信息——用户自填数据(年龄、职业、收入、婚姻状况、信用卡张数等),用户行为数据(刷卡详单、刷卡商户分布、月消费等),甚至还会有跨平台的数据(招聘网站的简历数据等):
同时,历史借款人是否按时还款是有记录的,因此可以根据历史数据找到基于以上变量的Fisher判别法则,用一个或几个原始变量的线性函数,将“未违约组”和“违约组”充分分离。
判别分析还可应用于其他商业领域,例如市场营销中新用户、流失用户和忠实用户的分离;消费者对不同竞争品牌的不同属性偏好;市场细分等。当然,判别分析只是用来找寻规则的,还属于描述性分析范畴,至于一个新来的个体到底属于哪个类别,还需要推断性的分类分析来告诉你。那就且听下回分解吧。
>>>>参考文献:
[1] Richard A. Johson and Dean W. Wichern. “Applied Multivariate Statistical Analysis”.
[2] Alvin C. Rencher and William F. Christensen. “Methods of Multivariate Analysis”.
[3] Brian Everitt and Torsten Hothorn. “An Introduction to Applied Multivariate Analysis with R”.
[4] 王斌会 《多元统计分析及R语言建模》
媛子简介
毕业于美国宾夕法尼亚州立大学统计系的博士小海龟一只;
就职于厦门大学经济学院统计系、王亚南经济研究院的小青椒一个;
学术方面关注高维数据的统计模型和方法、网络数据和图模型、统计基因学等;
实践方面关注统计咨询,想让更多的人认识统计了解统计会用统计。
文章来源:狗熊会,已经获得授权。
《END》
写在后面:各位圈友,一个等待数日的好消息,是计量经济圈应圈友提议,09月04日创建了“计量经济圈的圈子”知识分享社群,如果你对计量感兴趣,并且考虑加入咱们这个计量圈子来受益彼此,那看看这篇介绍文章和操作步骤哦(戳这里)。进去之后一定要看“群公告”,不然接收不了群信息。













