
文 | 传感器技术(WW_CGQJS)
GPU
,是
Graphics ProcessingUnit
的简写,是现代显卡中非常重要的一个部分,其地位与
CPU
在主板上的地位一致,主要负责的任务是加速图形处理速度。
GPU
是显示卡的
“
大脑
”
,它决定了该显卡的档次和大部分性能,同时也是
2D
显示卡和
3D
显示卡的区别依据。
2D
显示芯片在处理
3D
图像和特效时主要依赖
CPU
的处理能力,称为
“
软加速
”
。
3D
显示芯片是将三维图像和特效处理功能集中在显示芯片内,也即所谓的
“
硬件加速
”
功能。

今天,
GPU
已经不再局限于
3D
图形处理了,
GPU
通用计算技术发展已经引起业界不少的关注,事实也证明在浮点运算、并行计算等部分计算方面,
GPU
可以提供数十倍乃至于上百倍于
CPU
的性能,如此强悍的性能已经让
CPU
厂商老大英特尔为未来而紧张。
GPU
的诞生与发展
NVIDIA
公司在
1999
年
8
月
31
日发布
GeForce 256
图形处理芯片时首先提出
GPU
的概念。
GPU
之所以被称为图形处理器,最主要的原因是因为它可以进行几乎全部与计算机图形有关的数据运算,而这些在过去是
CPU
的专利。

从
GPU
诞生那天开始,其发展脚步就没有停止下来,由于其独特的体系架构和超强的浮点运算能力,人们希望将某些通用计算问题移植到
GPU
上来完成以提升效率,出现了所谓的
GPGPU
(
General Purpose Graphic Process Unit
),但是由于其开发难度较大,没有被广泛接受。
2006
年
NVIDIA
推出了第一款基于
Tesla
架构的
GPU
(
G80
),
GPU
已经不仅仅局限于图形渲染,开始正式向通用计算领域迈进。
2007
年
6
月,
NVIDIA
推出了
CUDA
(
ComputerUnified Device Architecture
计算统一设备结构)。
CUDA
是一种将
GPU
作为数据并行计算设备的软硬件体系。在
CUDA
的架构中,不再像过去
GPGPU
架构那样将通用计算映射到图形
API
中,对于开发者来说,
CUDA
的开发门槛大大降低了。
CUDA
的编程语言基于标准
C
,因此任何有
C
语言基础的用户都很容易地开发
CUDA
的应用程序。由于这些特性,
CUDA
在推出后迅速发展,被广泛应用于石油勘测、天文计算、流体力学模拟、分子动力学仿真、生物计算、图像处理、音视频编解码等领域。
GPU
的结构
GPU
实际上是一组图形函数的集合,而这些函数有硬件实现,只要用于
3D
游戏中物体移动时的坐标转换及光源处理。以前,这些工作都是有
CPU
配合特定软件进行的,
GPU
从某种意义上讲就是为了在图形处理过程中充当主角而出现的。
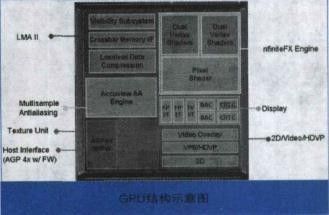
上图就是一个简单的
GPU
结构示意图,一块标准的
GPU
主要包括
2D Engine
、
3D Engine
、
VideoProcessing Engine
、
FSAA Engine
、显存管理单元等。其中,
3D
运算中起决定作用的是
3DEngine
,这是现代
3D
显卡的灵魂,也是区别
GPU
等级的重要标志。
GPU
的工作原理
GPU
中数据的处理流程
我们来看看第二代
GPU
是如何完整处理一个画面。首先,来自
CPU
的各种物理参数进入
GPU
,
Vertex shader
将对顶点数据进行基本的判断。如果没有需要处理的
Vertex
效果,则顶点数据直接进入
T&L Unit
进行传统的
T&L
操作以节约时间提高效率。如果需要处理各种
Vertex
效果,则
Vertex shader
将先对各种
Vertex Programs
的指令进行运算,一般的
Vertex Programs
中往往包含了过去转换、剪切、光照运算等所需要实现的效果,故经由
Vertexshader
处理的效果一般不需要再进行
T&L
操作。另外,当遇到涉及到曲面镶嵌
(
把曲面,比如弓形转换成为多边形或三角形
)
的场合时。
CPU
可以直接将数据交给
Vertex shader
进行处理。
另外,在
DiretX8.0
的
Transform
过程中,
Vertexshader
可以完成
Z
值的剔除,也就是
Back Face Culling
――阴面隐去。这就意味粉除了视野以外的顶点,视野内坡前面项点遮住的顶点也会被一并剪除,这大大减轻了需要进行操作的顶点数目。
接下来,经由
VertexShader
处理完成的各种数据将流入
SetupEngine
,在这里,运算单元将进行三角形的设置工作,这是整个绘图过程中最重要的一个步骤,
Setup Engine
甚至直接影响着一块
GPU
的执行效能。三角形的设置过程是由一个个多边形组成的,或者是用更好的三角形代替原来的三角形。在三维图象中可能会有些三角形被它前面的三角形挡住,但是在这个阶段
3D
芯片还不知道哪些三角形会被挡住,所以三角形建立单元接收到是一个个由
3
个顶点组成的完整三角形。三角形的每个角
(
或顶点
)
都有对应的
X
轴、
Y
轴、
Z
轴坐标值,这些坐标值确定了它们在
3D
景物中的位置。同时,三角形的设置也确定了像素填充的范围。,至此,
VertexShader
的工作就完成了。
在第一代
GPU
中,设置好的三角形本来应该带着各自所有的参数进入像素流水线内进行纹理填充和演染,但现在则不同,在填充之前我们还播要进行
PiexlShader
的操作。其实,
PieXIShader
并非独立存在的,它位于纹理填充单元之后,数据流入像紊流水线后先进入纹理填充单元进行纹理填充,然后便是
Piex!Shader
单元,经由
PiexlShader
单元进行各种处理运算之后再进入像素填充单元进行具体的粉色,再经由雾化等操作后,一个完整的画面就算完成了。值得注意的是,第二代
GPU
中普遮引入了独立的显示数据管理机制,它们位于
VertexShader
、
SetuPEngine
以及像素流水线之间,负资数据更有效率地传输和组合、各种无效值的剔除、数据的压缩以及寄存器的管理等工作,这个单元的出现对整个
GPU
工作效率的保证起到了至关重要的作用。

简而言之,
GPU
的图形(处理)流水线完成如下的工作:(并不一定是按照如下顺序)
顶点处理:这阶段
GPU
读取描述
3D
图形外观的顶点数据并根据顶点数据确定
3D
图形的形状及位置关系,建立起
3D
图形的骨架。在支持
DX8
和
DX9
规格的
GPU
中,这些工作由硬件实现的
Vertex Shader
(定点着色器)完成。
光栅化计算:显示器实际显示的图像是由像素组成的,我们需要将上面生成的图形上的点和线通过一定的算法转换到相应的像素点。把一个矢量图形转换为一系列像素点的过程就称为光栅化。例如,一条数学表示的斜线段,最终被转化成阶梯状的连续像素点。
纹理帖图:顶点单元生成的多边形只构成了
3D
物体的轮廓,而纹理映射(
texture mapping
)工作完成对多变形表面的帖图,通俗的说,就是将多边形的表面贴上相应的图片,从而生成“真实”的图形。
TMU
(
Texture mapping unit
)即是用来完成此项工作。
像素处理:这阶段(在对每个像素进行光栅化处理期间)
GPU
完成对像素的计算和处理,从而确定每个像素的最终属性。在支持
DX8
和
DX9
规格的
GPU
中,这些工作由硬件实现的
PixelShader
(像素着色器)完成。
最终输出:由
ROP
(光栅化引擎)最终完成像素的输出,
1
帧渲染完毕后,被送到显存帧缓冲区。

CPU
与
GPU
的数据处理关系
如今的游戏,单单从图象的生成来说大概需要下面四个步骤:
1
、
Homogeneouscoordinates
(齐次坐标)
2
、
Shading models
(阴影建模)
3
、
Z-Buffering
(
Z-
缓冲)
4
、
Texture-Mapping
(材质贴图)
在这些步骤中,显示部分(
GPU
)只负责完成第三、四步,而前两个步骤主要是依靠
CPU
来完成。而且,这还仅仅只是
3D
图象的生成,还没有包括游戏中复杂的
AI
运算。场景切换运算等等……无疑,这些元素还需要
CPU
去完成,这就是为什么在运行大型游戏的时候,当场景切换时再强劲的显卡都会出现停顿的现象。
接下来,让我们简单的看一下
CPU
和
GPU
之间的数据是如何交互的。
首先从硬盘中读取模型,
CPU
分类后将多边形信息交给
GPU
,
GPU
再时时处理成屏幕上可见的多边形,但是没有纹理只有线框。
模型出来后,
GPU
将模型数据放进显存,显卡同时也为模型贴材质,给模型上颜色。
CPU
相应从显存中获取多边形的信息。然后
CPU
计算光照后产生的影子的轮廓。等
CPU
计算出后,显卡的工作又有了,那就是为影子中填充深的颜色
这一点要注意的是,无论多牛的游戏家用显卡,光影都是
CPU
计算的,
GPU
只有
2
个工作,
1
多边形生成。
2
为多边形上颜色。
传统
GPU
指令的执行
传统的
GPU
基于
SIMD
的架构。
SIMD
即
Single Instruction Multiple Data
,单指令多数据。
其实这很好理解,传统的
VS
和
PS
中的
ALU
(算术逻辑单元,通常每个
VS
或
PS
中都会有一个
ALU
,但这不是一定的,例如
G70
和
R5XX
有两个)都能够在一个周期内(即同时)完成对矢量
4
个通道的运算。比如执行一条
4D
指令,
PS
或
VS
中的
ALU
对指令对应定点和像素的
4
个属性数据都进行了相应的计算。这便是
SIMD
的由来。这种
ALU
我们暂且称它为
4D ALU
。
需要注意的是,
4D SIMD
架构虽然很适合处理
4D
指令,但遇到
1D
指令的时候效率便会降为原来的
1/4
。此时
ALU 3/4
的资源都被闲置。为了提高
PSVS
执行
1D 2D 3D
指令时的资源利用率,
DirectX9
时代的
GPU
通常采用
1D+3D
或
2D+2D ALU
。这便是
Co-issue
技术。
这种
ALU
对
4D
指令的计算时仍然效能与传统的
ALU
相同,但当遇到
1D 2D 3D
指令时效率则会高不少,例如如下指令:
ADD R0.xyz , R0,R1 //
此指令是将
R0,R1
矢量的
x,y,z
值相加
结果赋值给
R0
ADD R3.x , R2,R3 //
此指令是将
R2 R3
矢量的
w
值相加
结果赋值给
R3
对于传统的
4D ALU
,显然需要两个周期才能完成,第一个周期
ALU
利用率
75%
,第二个周期利用率
25%
。而对于
1D+3D
的
ALU
,这两条指令可以融合为一条
4D
指令,因而只需要一个周期便可以完成,
ALU
利用率
100%
。
但当然,即使采用
co-issue
,
ALU
利用率也不可能总达到
100%
,这涉及到指令并行的相关性等问题,而且,更直观的,上述两条指令显然不能被
2D+2D ALU
一周期完成,而且同样,两条
2D
指令也不能被
1D+3D ALU
一周期完成。传统
GPU
在对非
4D
指令的处理显然不是很灵活。
GPU
的多线程及并行计算
GPU
的功能更新很迅速
,
平均每一年多便有新一代的
GPU
诞生,运算速度也越来越快。
GPU
的运算速度如此之快,主要得益于
GPU
是对图形实时渲染量身定制的,具有两点主要特征:超长流水线与并行计算。

多线程机制
GPU
的执行速度很快,但是当运行从内存中获取纹理数据这样的指令时(由于内存访问是瓶颈,此操作比较缓慢),整个流水线便出现长时间停顿。在
CPU
内部,使用多级
Cache
来提高访问内存的速度。
GPU
中也使用
Cache
,不过
Cache
命中率不高,只用
Cache
解决不了这个问题。所以,为了保持流水线保持忙碌,
GPU
的设计者使用了多线程机制
(multi-threading)
。当像素着色器针对某个像素的线程
A
遇到存取纹理的指令时,
GPU
会马上切换到另外一个线程
B
,对另一个像素进行处理。等到纹理从内存中取回时,可再切换到线程
A
。
例如:如果装配一台汽车需要,
10
个时间单元,将它分成
10
个流水线阶段,每个阶段分配一个时间单元,那么一条装配线每一个时间单元就可以生产一辆汽车。显然流水线模式的生产在理想状况下要比串行方式快了十倍。
但是使用这种方法有一个前提,线程
A
与线程
B
没有数据依赖性
,
也就是说两线程之间无需通讯。如果线程
B
需要线程
A
提供某些数据,那么即使切换到线程
B
,线程
B
仍是无法运行,流水线还是处于空闲状态。不过幸运的是,图形渲染本质上是一个并行任务。

并行计算
无论是
CPU
送给
GPU
的顶点数据,还是
GPU
光栅生成器产生的像素数据都是互不相关的,可以并行地独立处理。而且顶点数据(
xyzw
),像素数据(
RGBA
)一般都用四元数表示,适合于并行计算。在
GPU
中专门设置了
SIMD
指令来处理向量,一次可同时处理四路数据。
SIMD
指令使用起来非常简洁。此外,纹理片要么只能读取,要么只能写入,不允许可读可写,从而解决了存贮器访问的读写冲突。
GPU
这种对内存使用的约束也进一步保证了并行处理的顺利完成。
为了进一步提高并行度,可以增加流水线的条数。在
GeForce 6800 Ultra
中,有多达
16
组像素着色器流水线,
6
组顶点着色器流水线。多条流水线可以在单一控制部件的集中控制下运行,也可以独立运行。在单指令多数据流(
SIMD
)的结构中,
GPU
通过单指令多数据
(SIMD)
指令类型来支持数据并行计算。『参见图』在单指令多数据流的结构中,单一控制部件向每条流水线分派指令,同样的指令被所有处理部件同时执行。例如
NVIDIA8800GT
显卡中包含有
14
组多处理器
(MultiProcessor)
,每组处理器有
8
个处理单元(
Processor)
,但每组多处理器只包含一个指令单元
(InstruetionUnit)
。

另外一种控制结构是多指令多数据流(
MIMD
),每条流水线都能够独立于其他流水线执行不同的程序。










