Freeline
技术揭秘
1)Freeline是什么?
Freeline是蚂蚁金服旗下一站式理财平台蚂蚁聚宝团队15年10月在Android平台上的量身定做的一个基于动态替换的编译方案,5月阿里集团内部开源,稳定性方面:完善的基线对齐,进程级别异常隔离机制。性能方面:内部采用了类似Facebook的开源工具buck的多工程多任务并发思想:端口扫描,代码扫描,并发编译,并发dx,并发merge dex等策略,在多核机器上有明显加速效果,另外在class及dex,resources层面作了相应缓存策略,做到真正增量开发,另外引入并优化buck的部分加速组件dx,DexMerger,资源编译方面,深入改造了Aapt资源编译流程,当资源发生改变时候,秒级完成增量包编译,其中增量包仅含最小的变更集合(10Kb~数百Kb内),后期也被运用到线上进行资源/代码动态替换。相比目前instant-run,buck,layoutcast等方案快数倍速度。
2)有何优势?
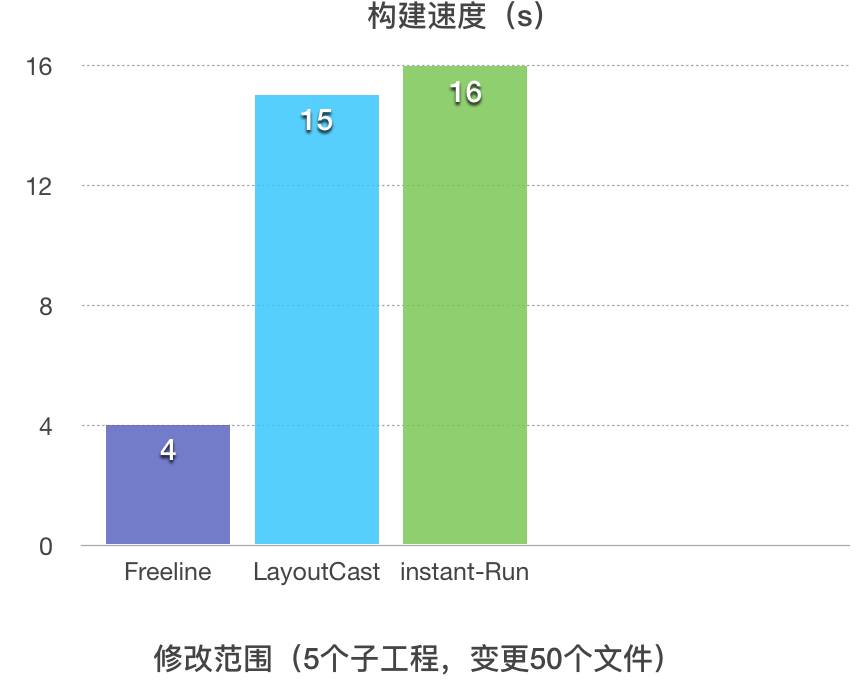
1.真增量,构建过程快且增量包体积小,极大提升更改代码部署到手机速度,较Android studio2.0及 LayoutCast快3~5倍;
2.跨平台Linux,mac,windows;
3.全版本覆盖 2.x ~ 6.x版本均支持;
4.部署流程简化,更改代码后,构建过程中,与手机建立了tcp长连接,一行命令即可完成增量部署,毋需到各自子bundle所在的目录构建完成后再进入portal/launcher进行打包再安装到手机的过程;
5.事务支持,在开发过程引入的异常不会破坏工作空间;
6.无缝支持mPass,解决了类似maven各个节点需merge合并等与常规开发流程不一致的问题;
7.进程级别异常隔离,开发体验持续稳定。
3)谁在用?
目前 Freeline 在阿里内部稳定支撑蚂蚁聚宝,高德地图等ANDROID技术团队日常开发,兼容mPaas/gradle架构。
开源地址:
https://github.com/alibaba/freeline
技术内幕:方案对比
先看看传统的Android打包流程:
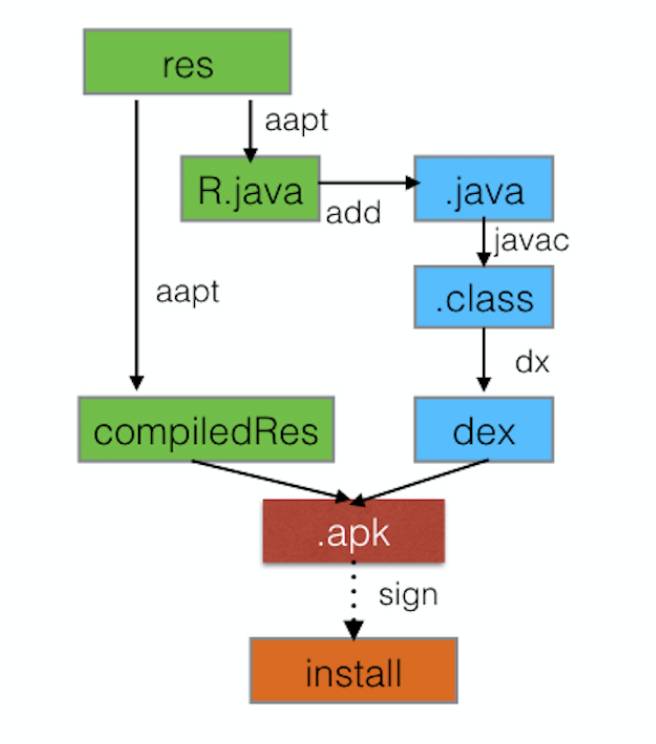
单线程沿着流水式的任务从上到下进行打包构建,其中,aapt会执行2次,第一次是生成R.java,参与javac编译,第二次是对res里面的资源文件进行编译,最后APKBuilder会把DEX文件与编译好的资源文件及DEX文件进行打包成APK,签名并安装至手机。整个流程下来,没有任何缓存,没有并发,也没有增量,每次构建都是一个全新的过程,所以每次构建时间也比较恒定,代码量,资源量越多,构建时间越慢。
下面对业内3个比较主流的增量构建方案进行对比分析:
LayoutCast
增量的思想源自于LayoutCast,与LayoutCast不同的是,Freeline把连接设备与各个工程间扫描及构建增量包任务仿照Buck的思路进行拆解,而LayoutCast是传统流水式任务构建,性能可能会被中间某个环节的耗时被拖慢,没有充分利用到多核优势。另外在资源变化后,LayoutCast选用的方案与Android Studio2.0 instant-run思路一致 ,把整个应用的资源打成资源包,推送至手机,若资源包大小较大,该过程耗费的时间相当可观,而资源包的大小直接影响了后面通过tcp传输的耗时,从资源变更的角度的来说,LayoutCast并实现没有真正意义上的增量。
另外,LayoutCast通是过运行期手机端反射R Class field的方式来生成ids.xml及public.xml,用于保证增量包的资源id与全量包的资源id一致,该方案存在几个缺陷:
通过手机端运行期反射,R有上万个field,效率相当低下,Galaxy note4上耗费近1s
存在致命缺陷,举个例子,app声明的attrs.xml若存在一个定义如下:
其中 ”pullFromStart“,”pullFromEnd” 对应的id值如下:
public static final class id {
public static final int pullFromEnd=0x56050005;
public static final int pullFromStart=0x56050004;
}
实际上上面2个枚举常量生成的id的type类型是“id”,若生成ids.xml及public.xml时候,不排除这些枚举id,最终的结果就是aapt给每个资源分配id时候,发生数组越界,aapt程序coredump掉,无法构建出资源包,而手机端运行期反射时候,仅知道”pullFromStart“,”pullFromEnd”为id类型,不足以知道其对应的是枚举常量,故仅仅通过运行期反射,上述致命缺陷无法解决。
再有,由于没有缓存机制,LayoutCast编译速度会随着修改文件的增加越来越慢。最后,由于代码增量使用的是dex插入系统dexlist最前位置的方式,在4.x的机器上面系统安全校验不通过,所以LayoutCast并不支持5.0以下的手机。
BUCK
下面说说BUCK,先看一幅其官方的构建过程图
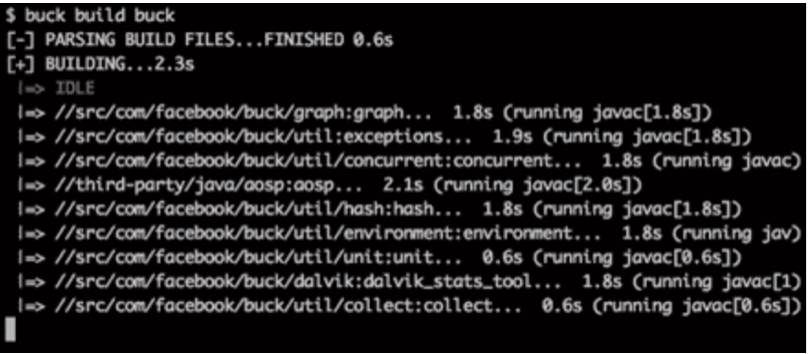
BUCK把原来单流水线任务以工程为单位拆分成多个可并发执行的子任务节点,梳理好各个节点前后的依赖关系,整理出有向拓扑图,通过多条线程并发把各个子任务节点构建出来,充分利用多核优势。
BUCK建立了一套完善的依赖规则以及细化的缓存系统来缩减编译时间,其增量构建的原理,实际是以工程目录为单位进行增量构建,发生变更时候,变更的工程,以及该工程作为父节点或祖先节点的工程,均需要重新构建,构建完这些变更涉及的工程后,Buck需要重新走一次合并各工程DEX,对齐,签名,打包APK的过程,构建完毕后,还要继续走安装流程,到最后手机查看修改效果时,可能还需要几个页面的切换才能进入之前修改的页面,这些流程整个下来,耗费的时间是相当可观的,另外不支持windows,以及较强的入侵性(整个工程需要做较大的调整才能使用)均是接入BUCK的门槛,但不得不承认,若作为全量构建的角度,BUCK的确是不二的选择,背后还有强大的Facebook技术团队在维护,在Facebook内部,所有的app构建工具均为BUCK,在国内,BUCK也被微信应用为默认构建方案。
instant-run
最后是谷歌官方的增量解决方案Android Studio2.0 instant-run ,首先其基本流程与LayoutCast有点相似,但因其代码增量是通过运行期hack method实现,所以进行了instant-run后,实际App没有重新走原有该走的生命周期,导致要看到类似onCreate,onResume等生命周期方法修改后的效果,必须手动重启一次进程,另外因为不同手机指令集合的不同,instant-run还会有一定挂掉的机会,最后,因为instant-run采用hack的方式,导致debug包调试时候无法看到对应的method堆栈,不得不说,这是个巨大的弊端,最后,与LayoutCast一样,instant-run不支持5.0以下的机器。
核心思想
正因为上面几个方案各自有各自的优缺点,Freeline融合各自优点而生,核心技术思想源自于Buck,LayoutCast,并在此基础上进行一步改良,争取把增量思想做到极致。
主要有如下几点:
多任务并发,多级缓存,增量范围最小化,懒加载,基于长链接无安装式运行期动态替换,基线对齐触发机制,可调试。
多任务并发
研究过Buck的同学应该清楚,Buck把原来单流水线任务以工程为单位拆分成多个可并发执行的子任务节点,梳理好各个节点前后的依赖关系,整理出有向拓扑图,通过多条线程并发把各个子任务节点构建出来,充分利用多核优势,在macbook上默认16条线程并发。
Freeline在启动时候仿照了Buck,根据工程间及任务间的依赖关系,提前计算好有向拓扑图,进行并发任务执行,默认开启8条线程(因聚宝工程数较少,没有必要开启过多线程),下面先简单介绍一下相关知识:
有向拓扑图
拓扑图是图的一种,“有向”保证了依赖关系和顺序关系,可以有多个根,
子可以有多个父。
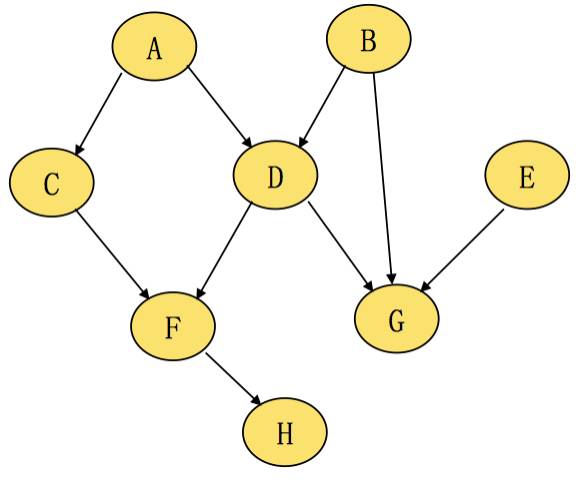
下面先以一张图简要说明Freeline构建期间各个工程任务工作次序:
整个工程角度来看,主要分成:
PC端与手机建立TCP长连接,扫描各个子工程文件变化,各个子工程的增量dex构建,增量资源包构建,合并所有工程dex,传输增量包。
上图中,分叉的箭头代表任务是并发的,同一时间,不同的工程可能处于不同的构建阶段,Freeline在启动时候,会先定义好各个子工程及其子任务前后的依赖关系,每个任务的前置任务,后置任务,位于同一层级的工程会进行并发构建,默认8线程并发。
单个工程流程
上面从总体上介绍了Freeline工作的整体情况,接下来详细介绍Freeline每个子工程做的事情:先以一张图说明Freeline构建期间单个工程为单位的任务流程:
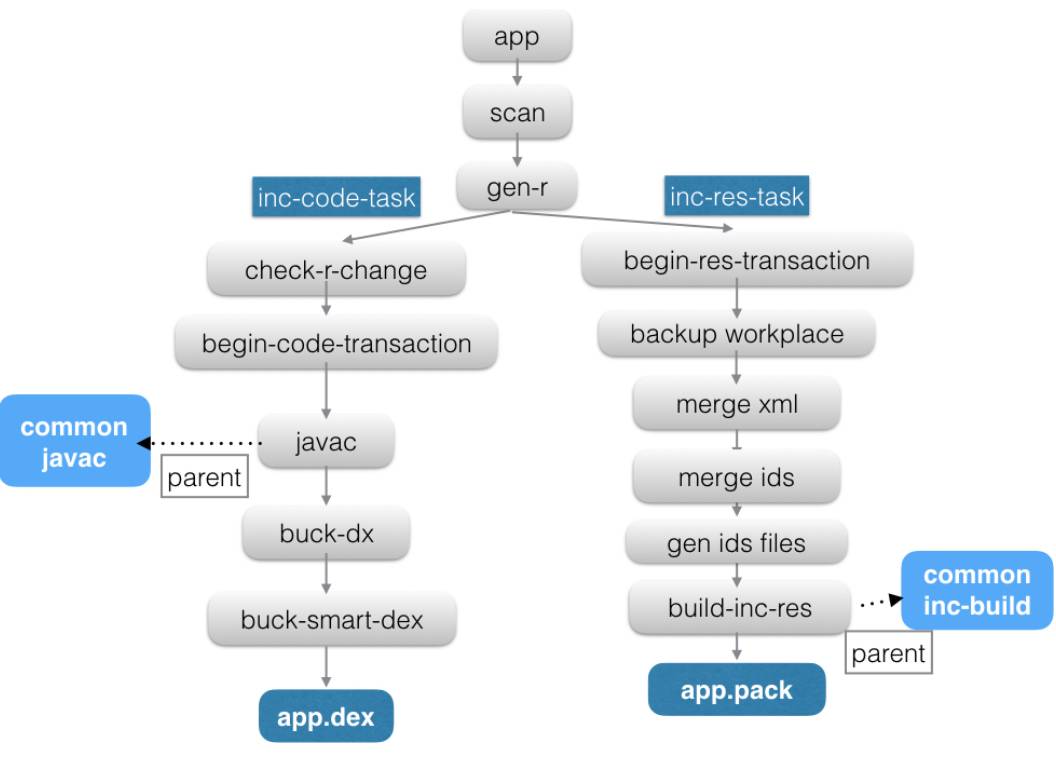
以app工程为例子,这里app依赖common ,构建过程有如下步骤:
1.scan扫描app工程内文件变化;
2.根据扫描结果,若同时有资源及代码变化则并发运行inc-code-task 及inc-res-task,以”inc“开头代表该任务是增量任务。
inc-code-task介绍
从上到下分别为:
check-r-change:
(校验R文件MD5是否发生变化),若发生变化则把新的R.java加入变更列表
begin-code-transaction:
该过程会把代码增量所必需的工作空间进行备份,若下面其中一个过程发生错误,则会把整个过程中构建的产物进行事务回滚
javac:
把扫描出来的java变更集合,进行编译,若存在dependency (上面例子为common工程)也在构建,则挂起,等待前置任务javac构建完毕后再往下执行
buck-dx:
这里实际上是把上面编译后的class文件变成dex文件,这里用“buck-”描述是因为该dx工具是从Buck中提取出来,经实测比Android原生的dx工具快40%左右
buck-smart-dex:
同上,该工具在buck工具中提取而得,目的是使上一步打出来的dex体积进一步减小,最后生成的dex则为该工程该次增量dex构建的最终结果。
inc-res-task介绍
begin-res-transaction:
该过程会把资源增量所必需的工作空间进行备份,若下面其中一个过程发生错误,则会把整个过程中构建的产物进行事务回滚
merge xml:
若更改的文件在其他子工程也存在,以mPaas架构为例,存在api,biz,build,或tools,这些工程可能会存在同名的xml文件,这种情况需要对这些xml文件内对应的节点进行合并
merge ids:
若上面gen-r 阶段发现R的md5发生过变更,或更改的文件集合里面有ids.xml或public.xml,则把目标目录里面的ids.xml及public.xml与新变更的ids.xml 与public.xml进行xml节点合并。
gen id files:
该过程是实现资源增量的关键,该过程会通过最后一次构建的资源包,反向生成
ids.xml及public.xml,该两个文件在构建增量资源包时候参与编译,可以使得
最后构建出来的资源包的内对于的资源ID与前一次构建的资源包保持一致,该过程原理后面篇幅会详细介绍。
build-inc-res:
该过程会把上面scan过程扫描出来的资源变更集合参与作为参数传入我们自己改写过的increment版本的Aapt,该工具主要完成几个事情:
1.构建增量包,生成最终的资源包时候,仅仅包含编译后的变更资源集及“resources.arsc” 与 “AndroidManifest.xml”;
2.兼容mPaas架构Base Package id 问题;
3.根据ids.xml及public.xml生成保持id值与前一次构建结果里面的id值相同,若该任务有前置的资源任务(上面例子为common),则等待其前置增量资源任务先构建完毕,最后构建出来的包以“.pack”结尾。
多级缓存
在代码变更方面,Freeline在各个工程的Class,dex层面加入了缓存,已经编译过的java文件,直接从增量工作空间里面的的Class pool获取,已经dx过的Class文件,会直接从dex pool中获取,最后实现的效果是,每次增量构建都是一个全新的流程,此前的修改不会参与到本次增量编译过程,不存在LayoutCast方案随着修改文件的增多越来越慢的问题。
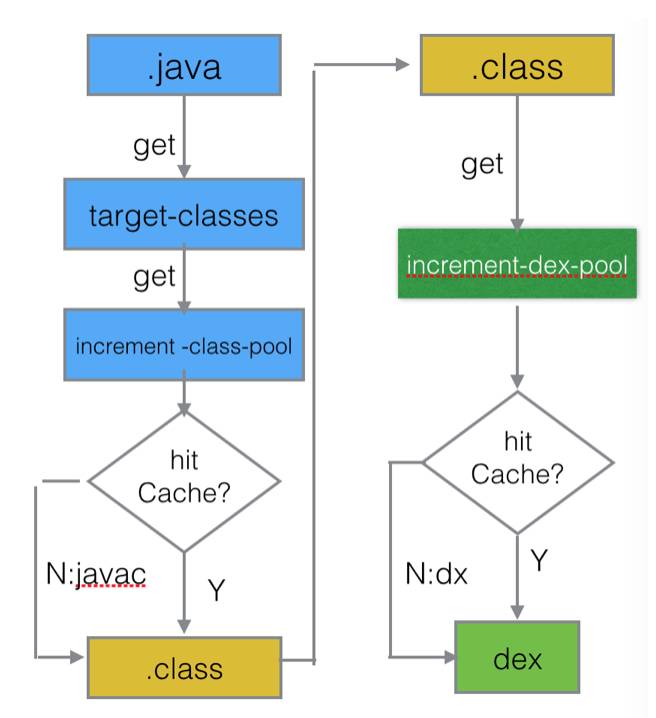
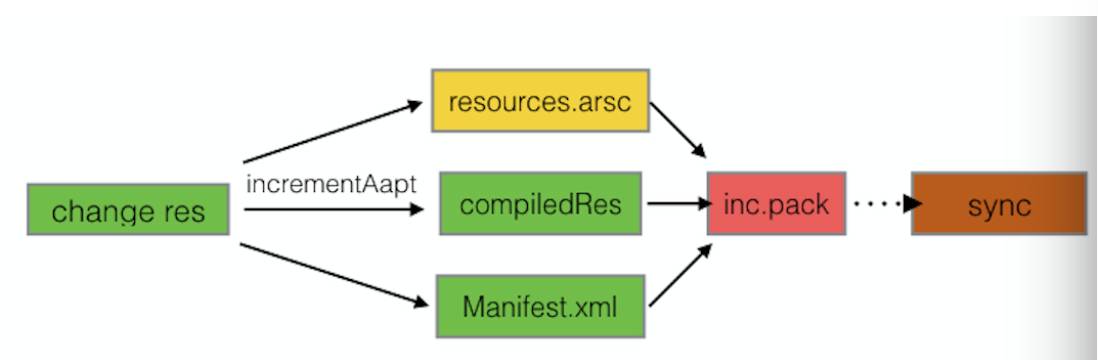
在资源变更方面,Freeline会在每次增量包构建后,把增量修改的资源文件与手机端对应的文件进行一次sync同步,每次资源增量构建范围仅仅是本次修改的集合,此前的修改均在此前的sync同步过程中同步至手机端。与代码变更一样,不需要构建此前修改的增量集合。
加入多级缓存及多任务并发策略后数据对比:
增量范围最小化
Freeline会尽可能把增量的范围缩小到单次修改对应的必须要更改的文件集合,不定期与手机端进行同步,以减少随着修改范围增大带来的性能损耗。
代码层面,运用了上面提到的多级缓存,每次仅仅编译本次修改的文件,此前修改过的文件不在本次编译范围。
资源层面,我们为了尽可能降低增量包的体积及构建成本,在aapt的基础上,拓展了一个叫IncrementAapt的工具,并把其编译成linux,mac,windows三个不同平台以做平台兼容,该工具会根据修改的资源文件,及最后一次资源构建结果,构建出对应的增量包,该增量包仅仅含变更的资源集合,且进行过7-zip压缩,大小视更改修改量而定,一般情况只有数百kb。极大程度降低打资源包及最后tcp传输的耗时。
懒加载
Freeline 把任务尽可能延后到真正需要的时候进行,例如对R文件的javac编译,若仅仅修改资源文件,即便是新增了资源文件,如:加了新的id,新的图片,layout等,触发了新的R文件与旧的R文件的id集合不一致,但此如果没有修改过java文件,则不会触发对R文件的编译,也就是如果只修改资源,没有更改过java代码的话,不管实际上应用的id集合是否已经变更,Freeline会以极小的代价构建出增量的资源包,推送至手机,直接在当前的Actvity刷新,不需要重启进程。对于新的R文件的编译,会延后到该工程有java文件更改才执行,这样也保证代码里面真正需要R文件新增的id值的时候,能找到对应的值,在没有代码更改前,进程无需重启,加快刷新效率。
可调试
Android studio instant-run 因采用的是Hack method 的方案,存在被修改的方法无法调试问题,LayoutCast构建的增量Class,在Debug调试下也存在参数值无法显示的问题,Freeline在该点上进行了处理,使得增量构建的类文件与全量构建一致,不影响日常调试。
基于长连接无安装式动态替换
无安装式动态替换与LayoutCast及Android Stduio2.0 instant-run一致,也是该两种增量构建方案的最大的优点,整个构建过程不需要重新安装app,动态替换代码及资源,省去了安装app及重启进程进入对应界面的过程。整个交互流程图见下:
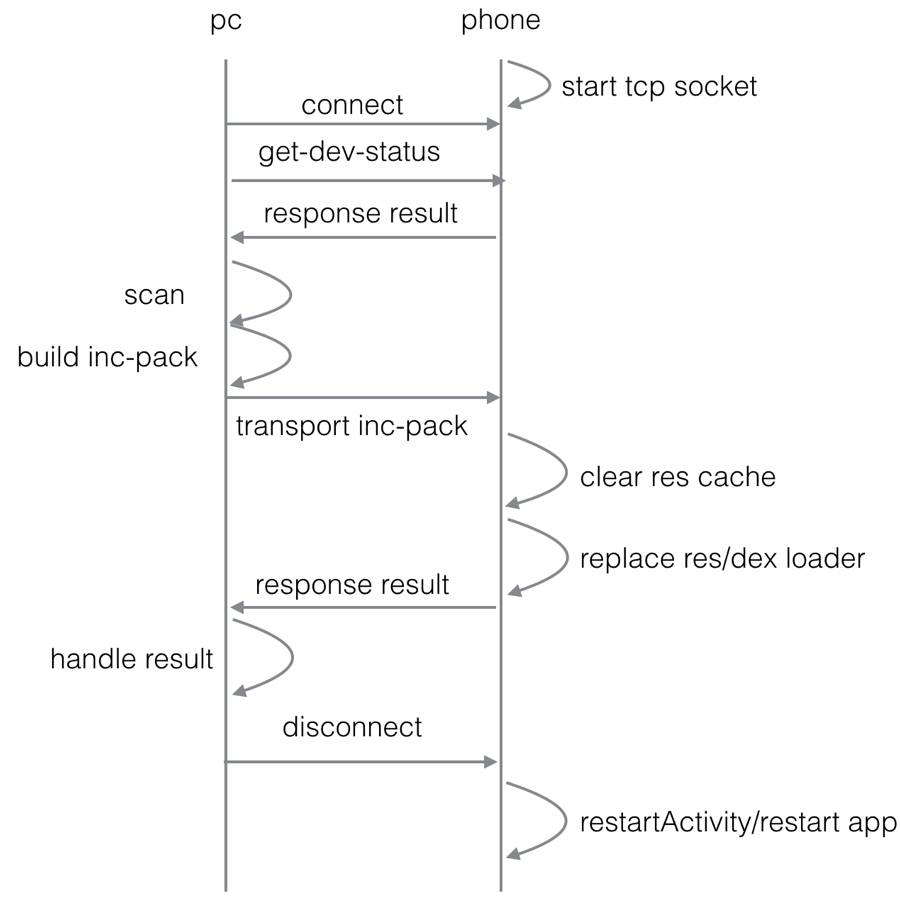
1.phone端会架设一个tcp socket作为服务器。
2.pc端会与手机端进行socket连接。
3.pc端与phone端会通过自定义协议进行交互,pc端会询问phone状态,比如获取手机端基线包版本,sdk版本号,当前手机是否支持资源增量,当前Activity名字等等,后续传输增量包,手机端向pc端返回增量构建结果等,整个通讯过程,均会沿用同一条长连接进行。
4.在同步完增量包后,phone端会根据当前变化是代码变化还是仅仅res变化来决定下一步操作,若仅仅res变化,则直接restart 整个Activity栈里面的Activity,若存在代码变更,则直接重启当前进程,由于Android系统Activity栈的管理,进程被杀若Activity栈还存在Activity,则在该app重启时候,会沿用原来的栈顺序重新创建这些Activity。最终的结果,重启后,界面就会出现最后显示的Activity,(这里有特殊情况,如果该Activity的launchmode设置的是singleTask,或singeInstance,则重启后除了最后的这个Activity,堆栈内的其他Activity均会被清空,这涉及到Android对Activity的管理机制问题,这里不细说,有兴趣的同学可以到自行google。)而按返回键后UI也会顺着原来栈里的Activity顺序显示。
基线对齐触发机制
Freeline会在下面情况重新构建基线包:
1.在git pull 或 一次性修改大量的文件情况下,会导致增量包体积大增,影响后期传输及手机重启后对增量包进行dexopt的速度,考虑到这种情况毕竟是少数,没必要为一次的变更影响后期的增量构建速度。
2.无法依赖增量实现的修改:修改AndroidManifest.xml,更改第三方jar引用,
依赖编译期切面,注解或其他代码预处理插件实现的功能等。
3.更换调试手机或同一调试手机安装了与开发环境不一致的安装包。
由于在重建基线包前,可能已经进行了若干次的增量构建,故在重建基线包时候,要把这些增量构建对应的module进行全量构建,以使得最新的基线包包含了所有过去的修改。整个流程如下图:(A,B, C 分别为3个不同子工程)
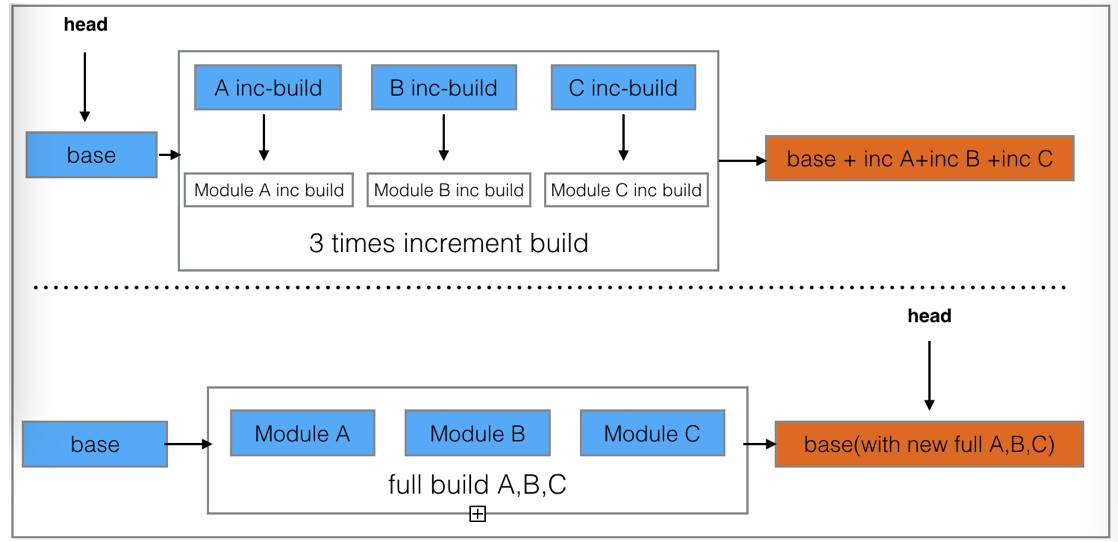
head 作为指针,指向最新的基线包状态,base为对应初始的基线状态,在经过3次增量构建,手机端内app的状态会变成base + 3次增量的结果,上面例子里面,3次增量构建涉及A,B,C 3个Module,那么,在触发基线包对齐过程中,会对A ,B,C 按照原来的全量构建方式进行构建,与增量包构建一样,全量包的构建顺序会按照A,B,C前后的依赖关系按顺序进行,位于同层级的工程会进行并发构建,构建完毕后会重新安装至手机,在此之后,手机端内app以全量的方式包含A,B,C的修改,此前的3个增量包会在覆盖安装后第一次启动中被清除,此时基线指针head会从最初的base指向最新的base(with new A,B,C),至此,整个基线对齐就完成了,若中间发生异常,则在下次运行时候仍然会进行一次基线对齐过程,保证手机端安装上最新的全量包。
基线对齐的校验机制
上面的介绍的是基线对齐的整体思路,下面介绍一下校验部分的关键思路:
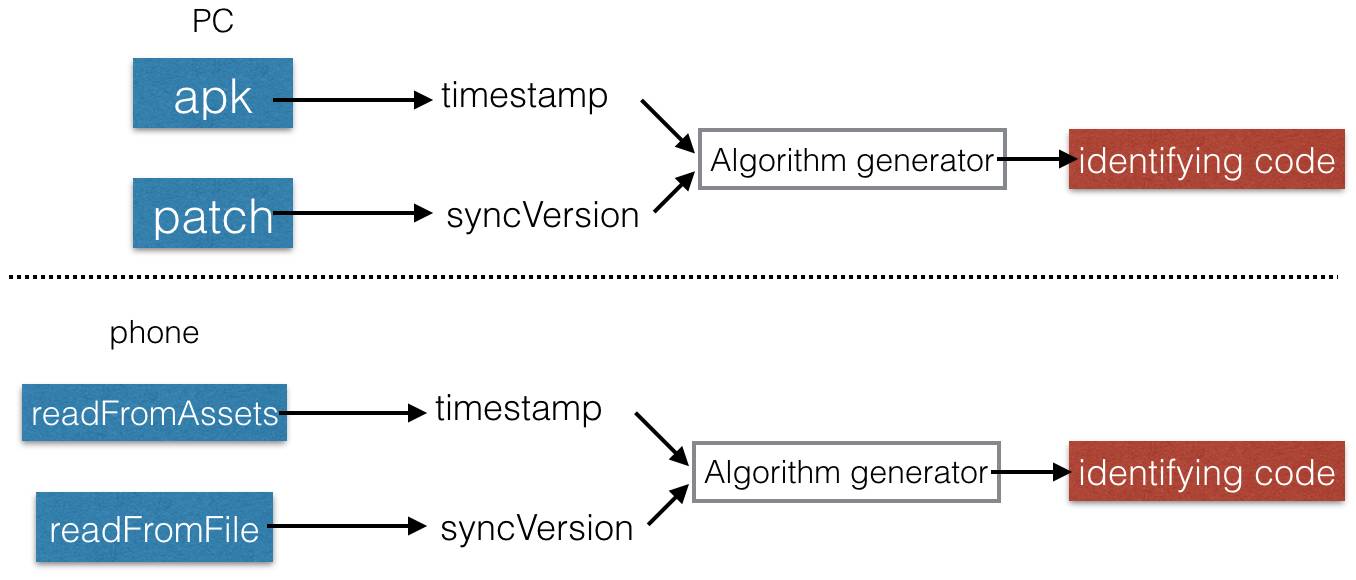
1)在全量包构建的时候,把当前的时间戳打包进assets目录,该值用于确保全量包的一致性。
2)每次进行增量包传输后,由手机端与PC端共同维护了一个自增长的sync id,每次传输成功后,该id会触发更新,该值用于确保开发环境的开发状态与手机端增量的开发包的状态一一对应。
3)在每次传输增量包前,手机端与pc端会基于上述两个值的生成一个验证码,并且对这个验证码进行校对,若两端的验证码不一致,则认为校验不通过,需进行基线对齐。
进程级别异常隔离
Freeline的socket tcp server是运行是独立进程的,之所以要进行进程隔离为的是当开发增量部分传输至主进程后,导致crash的情况,防止无法进行进行增量传输,故把tcp传输部分独立到单独进程,保证传输过程持续稳定,实际上这也是遵循”轻重分离“,把刷新替换部分较重的容易导致crash的部分交由主进程执行,把建立连接,传输及基线对齐等较稳定的部分移至独立进程。
增量原理
代码增量:
关于代码增量,与业内主流的通过植入Dex 到 系统DexList 实现hotpatch方案相同,关于其原理网上也有不少介绍,这里再简单的提一下:
系统查找Class,最后会到BaseDexClassLoader查找
最后调用到DexPathList
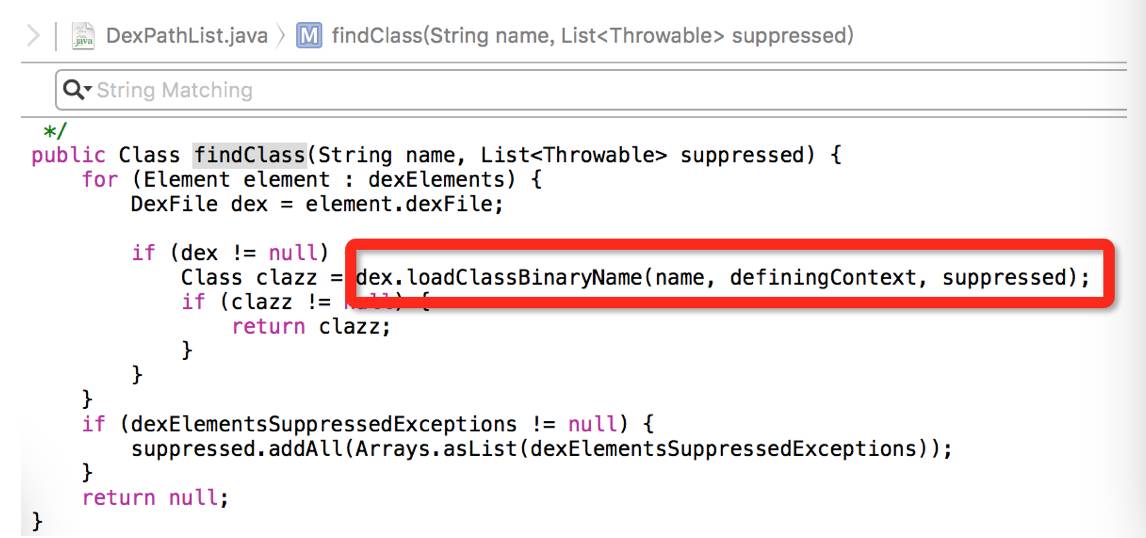
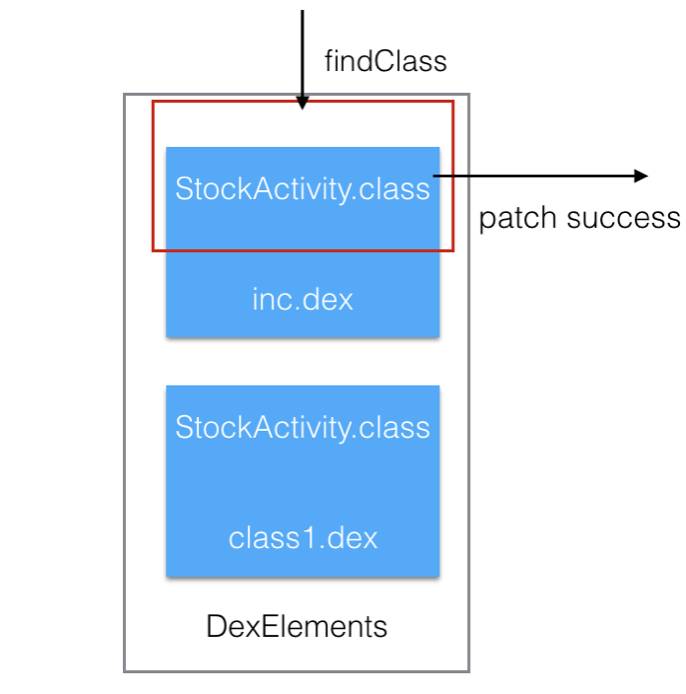
其中DexFile对应的为默认安装包里面的class.dex,class2.dex...等。在Google支持MultiDex后,构建工具默认会按照65536方法及LinearAlloc内存限制进行分包,一般一个大型app,会有多个dex文件存在,从上面的代码来看,对于类的查找,从dex数组,最前的位置开始找,找到对应的Class则不会继续往下找,这也给利用该特性进行增量带来了契机。
在应用启动时候,把我们准备好的增量dex通过反射注入到DexElements最前面,则整个增量部署就完成了。
资源增量:
资源增量是开发Freeline过程中,攻克时间最长的一块,也是Freeline相对其他构建方式,比较明显的一个特性,前面说过,LayoutCast和instant-run在资源更改后,实际上是把全量的res资源重新打包,推送至手机,进行整个资源包的更换,所以资源数量越多,大小越大,构建的时间就越长。
先说说开发一个资源增量的特性需要解决什么问题:
1.增量包资源id怎么兼容基线包资源id?
2.怎么样高效构建出仅仅包含变更集合的资源包?
3.怎么样在手机端让上面构建的增量包生效?
带着问题,我们一步步来介绍:
先解答第一个问题:基线包资源id与增量包资源id怎么保持一致?
1.关于资源包id向前兼容的问题,业界一般采用上一次资源包生成的public.xml 及 ids.xml参与后续资源编译解决,业界生成上述2个文件,主要有如下2个方案:
Freeline采取的思路是通过最后一次编译res过程的R.java,反向导出保留id所需要的两个文件,这个功能抽成单独的工具“id-gen-tool”,该工具会根据枚举常量生成的id的上下文特征,过滤掉枚举常量,解决掉其引起的内存越界问题。
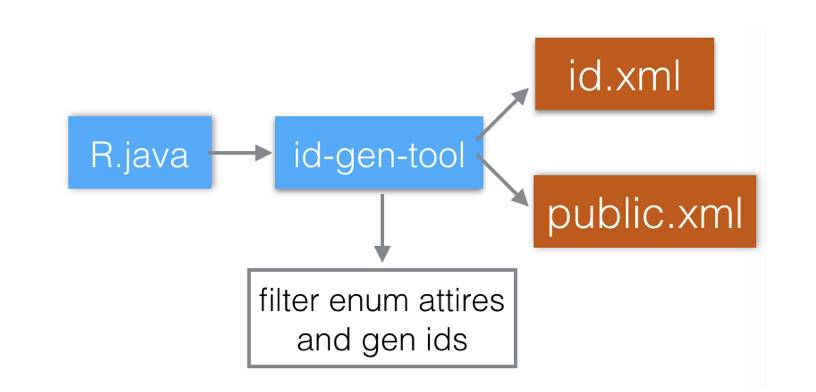
由于整个过程仅仅需要对R.java一个文件进行分析导出,不需要解压APK以及反编译APK资源包内资源,故整个过程基本不受资源包内资源大小,数量影响,另外因为是在pc端进行,故整个过程比在手机端快90%以上。下面是数据对比:
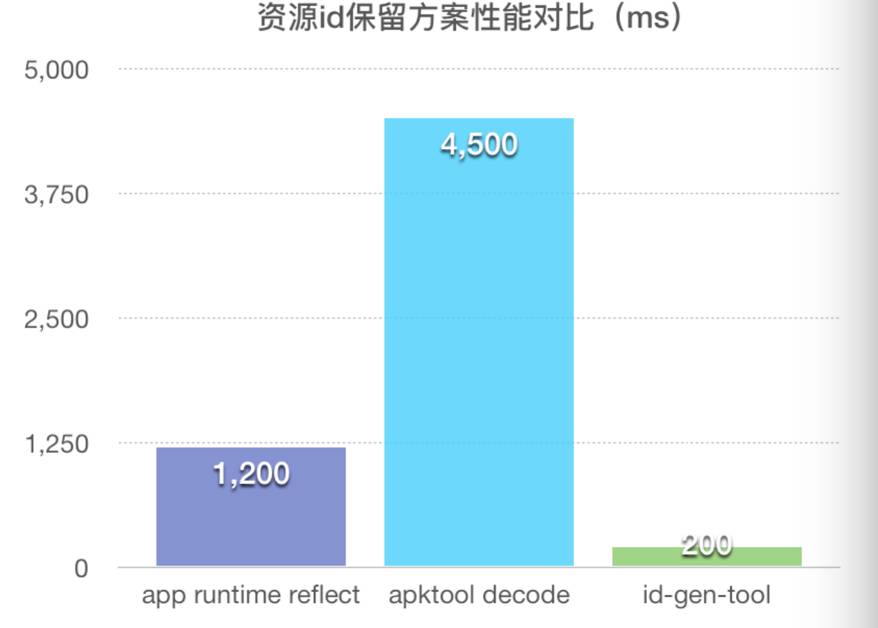
在30mb的资源数量下,id-gen-tool的速度较app反射方案快90%,较apktool反编译方案快95%以上,随着资源数越多,差距会越来越明显。
id-gen-tool细节问题
有了这两个文件,资源id的问题算是搞定了,实际上真的这么简单么?等等,把这两个文件放置到资源目录里面的values目录下,对资源进行编译,又出现意想不到的问题:
且看看在styles.xml上这个定义
@anim/pump_bottom
@anim/disappear
生成的R.java对应的id是什么:
public static final class style {
public static final int Animations_Pop=0x1f0b002c;
………………….
}
也就是说,R.java内的资源命名,压根不存在“.”, 这样而通过R.java生成的id就会变成这样:
………………………
这样,最终导致的结果是编译资源时候找不到"Animations_Pop" 这个资源而编译报错。而因为无法从R.java 变量命名来推断出原资源定义里面是" ." 还是 "-" 。这个这么看来,通过R.java反向生成id文件的办法是行不通的,但还好,aapt程序也在我们手里,只要让aapt针对这种情况进行兼容,那上面的方案就是行得通,最后,我们拓展aapt寻找资源的策略,发现找不到资源时候,会尝试把资源名称里面“-”替换成“.”,继续寻找,如此一来,上面问题也就解决了。
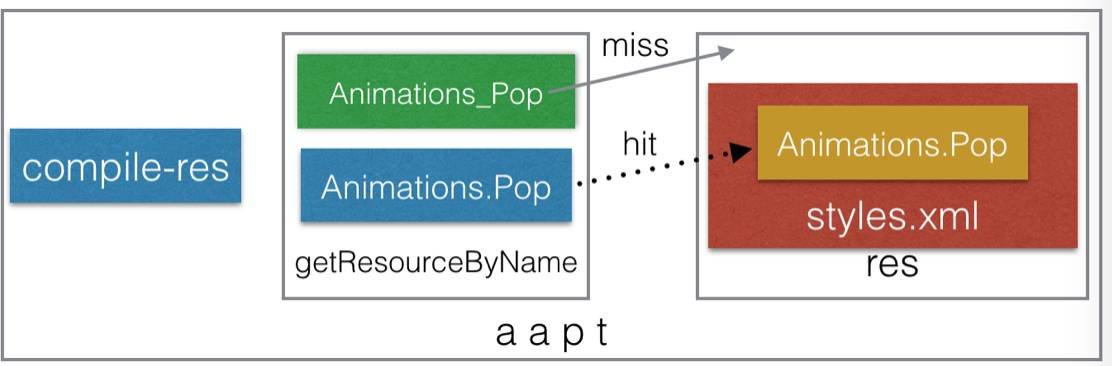
最后提一点,在基线包id被固定后,新增资源就不会对原有资源id的访问造成影响,也就是说,基于这个前提下,我们就不需要保证增量包里面的资源数与基线包一致。这也解决了日常开发引入新的资源可能会引起的与基线包id不对称问题。
下面来介绍第二点:怎么样高效构建出仅仅包含变更集合的资源包?
关于Android资源编译,可以看看老罗的这篇博客:
http://blog.csdn.net/luoshengyang/article/details/8744683
这里把过程图片借鉴一下:
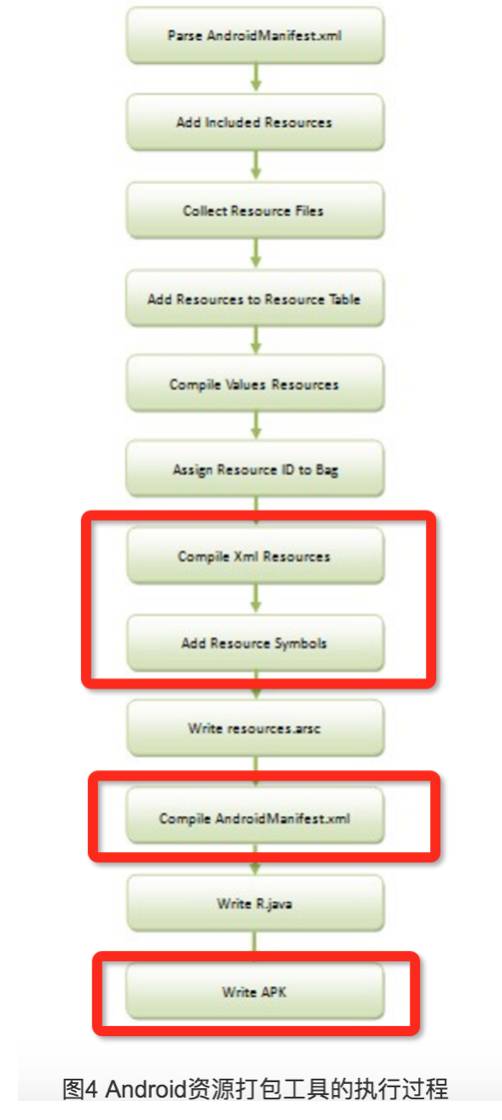
我们把整个资源包构建可以优化的技术点在上面图片的红圈标了出来:实际上,在前一步通过资源ids.xml及public.xml生成出来,放进values目录参与编译后,即便不对未变更的layout资源及AndroidManifest.xml进行编译,最终对生成的resoucres.arsc是没有影响的。也就是在保留了资源id的情况下,只需要编译变更了的xml文件就能实现对resoucres.arsc的更新。
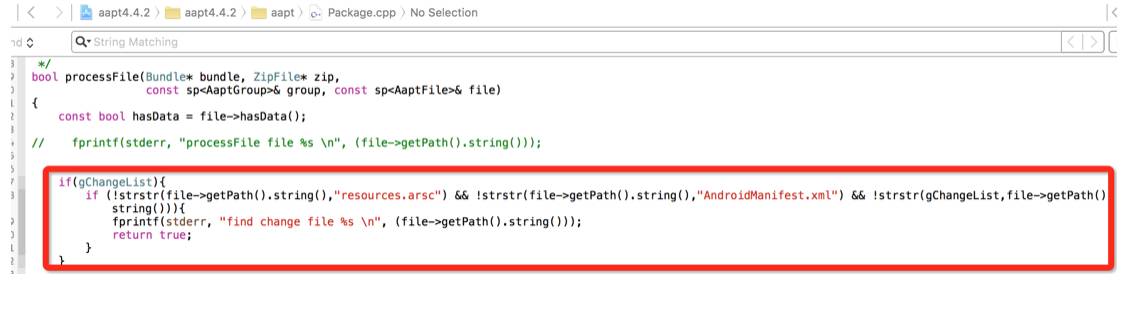
在前面扫描里面,我们知道了总共有哪些变更的资源文件,py会把这些资源文件相对路径截出来,作为参数’—buildIncrement’传入到incrementAapt工具里面,在编译资源的流程里面,如果非变更的资源,我们利用了最后一次资源包里面编译好的资源作为缓存,非变更的文件,我们直接让其从编译好的资源读取,整个过程不需要重新对非变更资源进行编译。(由于这块代码更改地方较多,这里就不贴出来,后面整理好后,会进行开源)
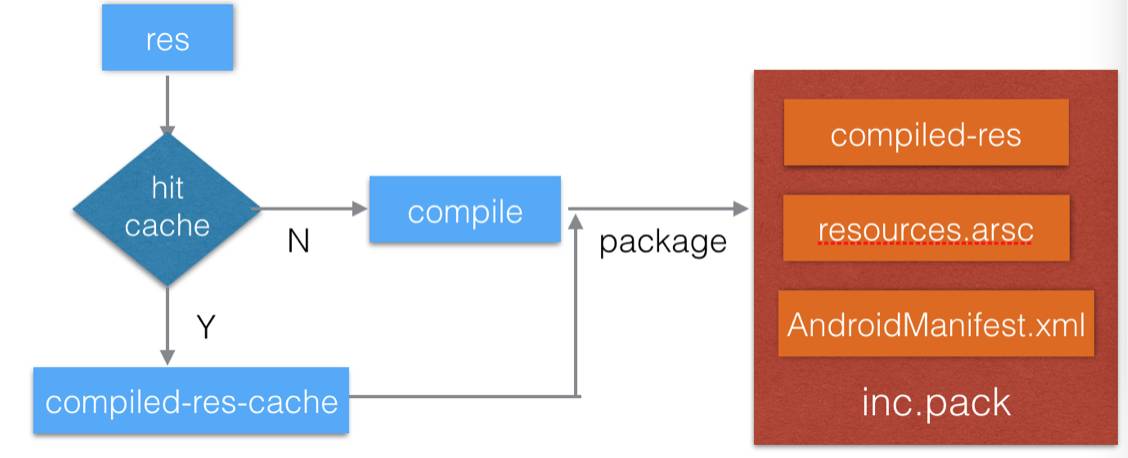
最后打包成最终APK时:我们还修改了打包文件的流程,incrementAapt仅仅对修改的文件对应的编译后的资源进行打包:
整个流程下来,最终构建出来的包就仅包含变更的资源集及“resoucres.arsc”与“AndroidManifest.xml”。
这里解答一下:为何需要对“resoucres.arsc”与“AndroidManifest.xml”进行打包?
由于当有新增资源后,“resoucres.arsc” 是会变化的,代码里面对新增资源的引用就是通过更新”resoucres.arsc” 来实现。这里打包“AndroidManifest.xml”原因是,在sdk19之后,底层AssetsManager->addpath 过程会触发对res资源包的校验过程,没有“AndroidManifest.xml”的资源包会被认为不合法的资源包,不会被成功添加。
资源编译各步骤优化数据:
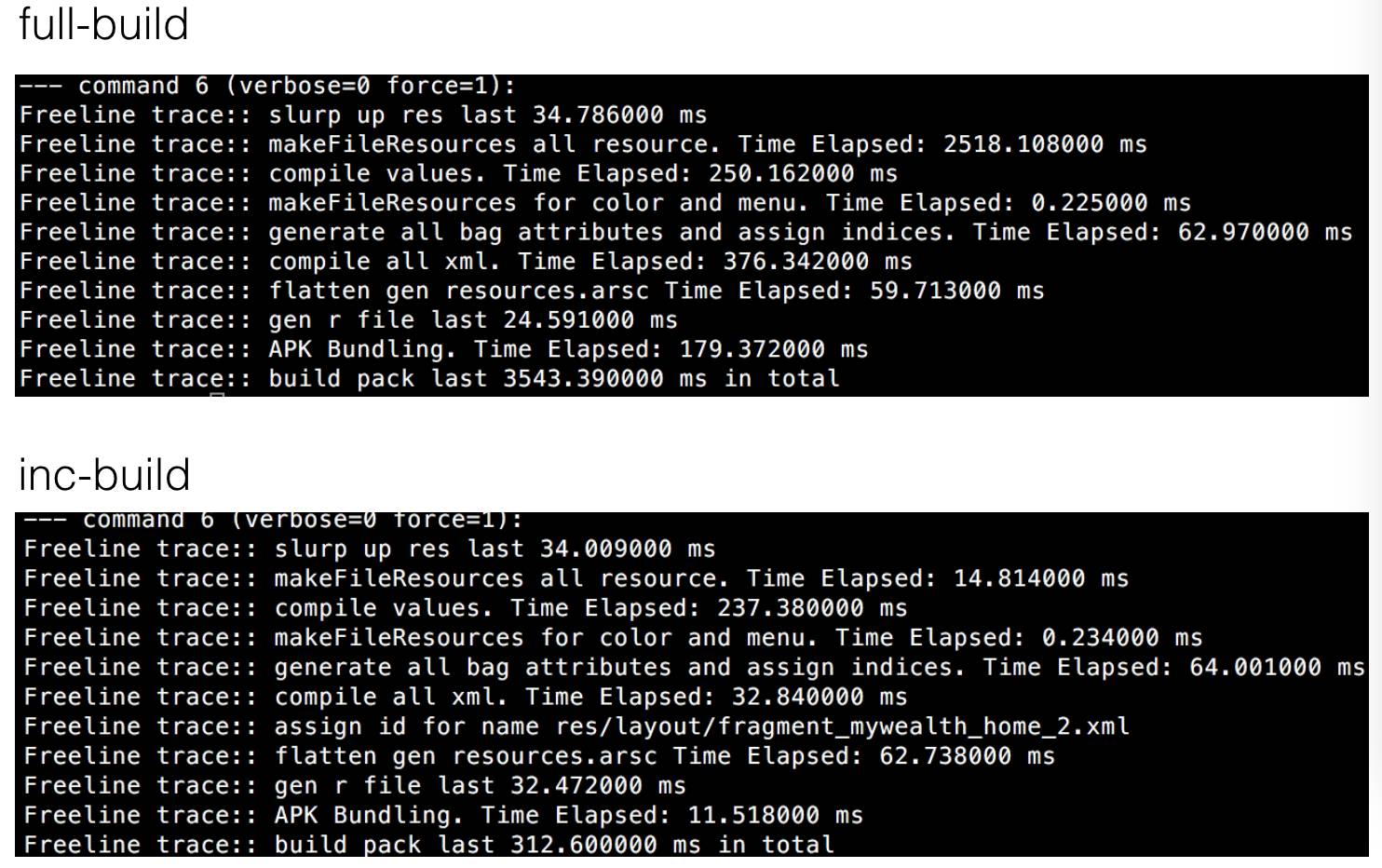
以30mb的资源为例子,下面是整个资源编译流程优化前后数据:
下面简单介绍一下各个步骤,详细流程可以到上面提到的老罗的博客看。
slurp up res: 收集资源。
makeFileResoucres all resource: 把上一步收集的资源添加进内存,如果有图片,则会在这一步对图片资源进行处理。
compile value:对“value”目录下面的资源进行编译。
makeFileResoucres for color and menu :对”color“ 及”menu“目录的资源进行编译。
generate all bag attr:为“bag”类型分配资源id。
compile all xml:这一步是真正对layout,anim,animator,interpolator,transition,xml,color,menu目录所包含的资源进行编译,压平。
flatten gen resources.arsc :根据上面收集的信息生成“resources.arsc”文件。
gen r file:生成R.java。
APK Bunding:对所有编译后的资源进行打包。
可以通过数据对比看到:主要的速度提升在compile all xml(编译xml文件) ,APK Bunding(打包APK),makeFileResoucres all resource(对图片资源进行预处理)几个步骤。若通过传统方式aapt编译打包,接近3.5s,而通过上述方式,整个构建时间仅仅需要300ms。这比前者快90%,随着资源数的增多,总大小的增大,差距会越来越明显。
怎么让上面构建出来的增量包在手机端生效?
经过深入AssetsManager底层的分析,我们发现,res实际上是支持以目录的形式存在,那么整个增量包生效的思路就呈现出来了,流程如下:
1)首次运行增量构建,手机端会对基线包的base.apk(在mPaas,这里是Bundle对应的资源jar路径)进行解压:
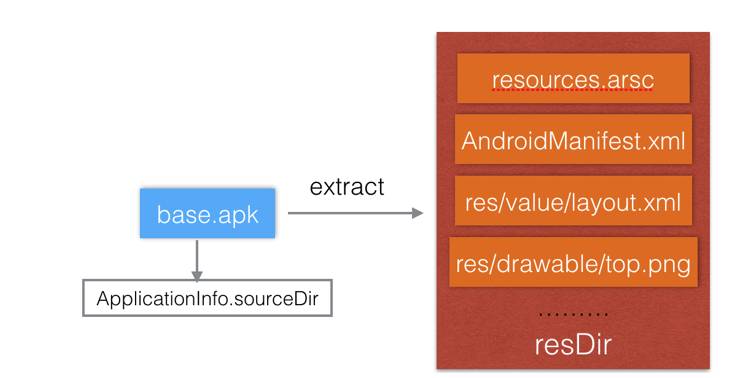
在这之后,resDir目录里面就包含了所有该资源包里面的文件。在此之后我们可以把
AssetsManager所对应的path指向resDir,这样一来,实际上UI对应的资源就来自于resDir目录。在进行资源更改后,在前面介绍知道,Freeline通过tcp连接把增量的资源包 inc.pack 传输进手机后,会触发一次sync,用于把增量包的修改同步到手机端。流程见下图:
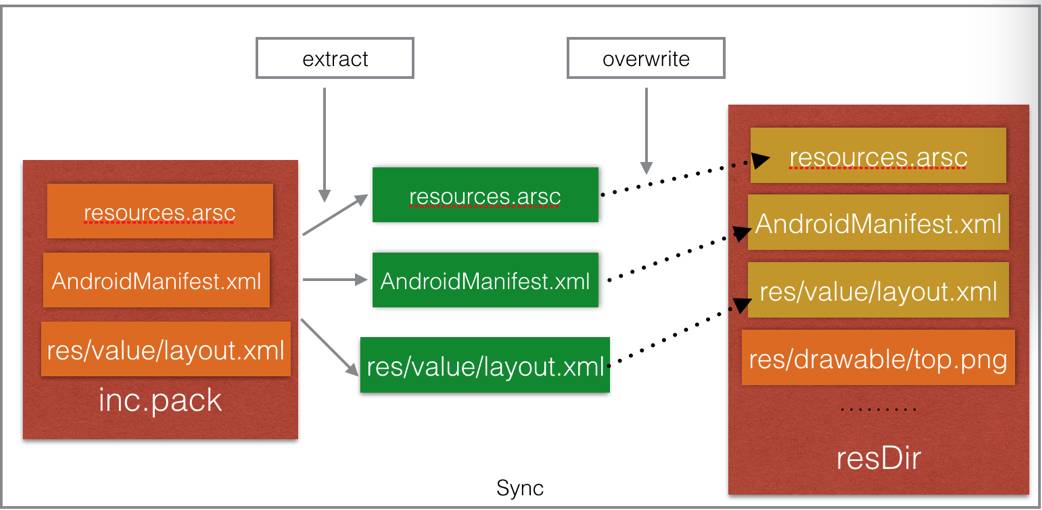
手机端会将inc.pack进行解压,然后把解压后的buffer,直接写入resDir目录里面的相对位置,整个过程仅有从压缩包提取-写入文件系统两步。最后一步,就剩下清空Resources资源对应的Cache,重新构建新的Resources并让app使用之,这一步网上已经有很多介绍,这里就不另作篇章了。对于mPaas架构而言,要使之生效,无非是找到对应的Bundle所在的Resources,清除其缓存,重新刷新一次UI。
资源增量构建数据对比:
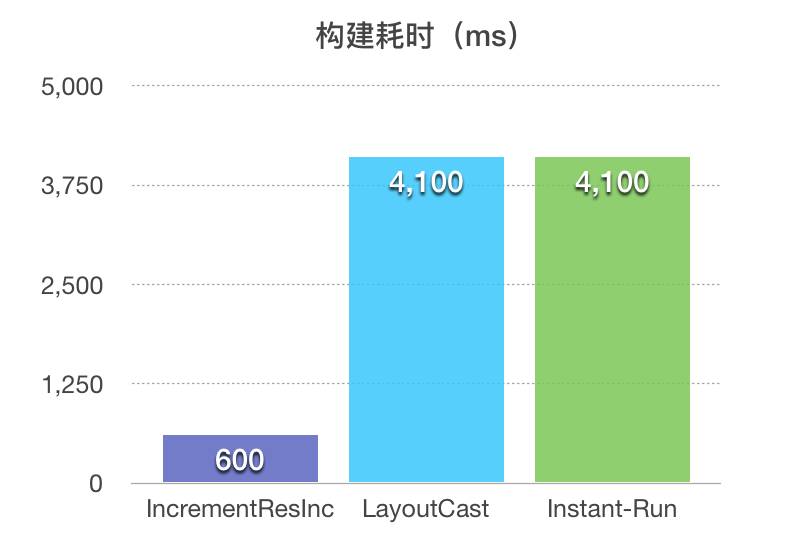
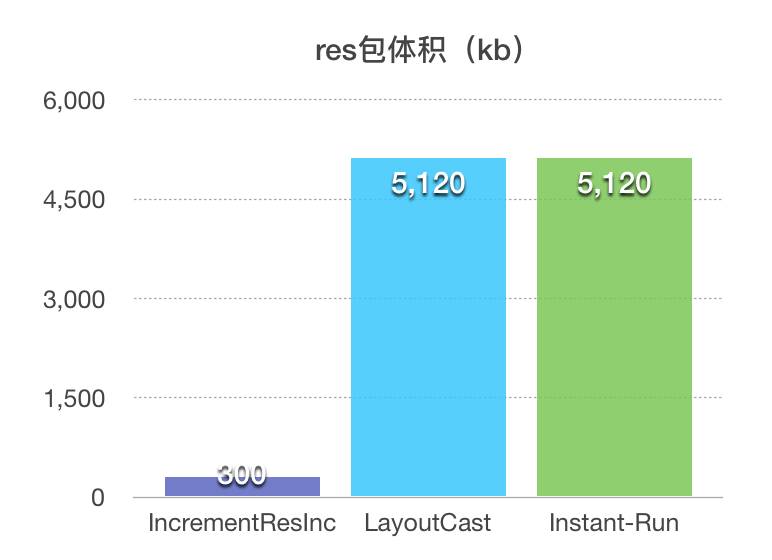
在40mb的资源下,构建出一个资源增量包,上述方案仅仅需要600ms,其他方案要4s以上,增量包体积仅仅为300kb,而其他方案构建出的资源包为5mb。
这里提一点:让增量资源包生效的还有另外一条路径是采用系统自带的”overlay”方案。
也就是“layout”,”drawable“,”color“,”anim“,”xml“ ,”raw”,”animator”,”interpolator“,”menu“等目录类型所在的资源id对应的索引项在构建“resources.arsc ”时候设成“NO_ENTRY”,运行期生成AssetsManager时候把增量资源包的path顺序放在添加全量包的前面。利用系统查找机制来覆盖掉更改的资源。
Freeline这里没有选用上述方案的一点原因是:
1)由于系统overlay设计限制,资源无法实现新增功能,只能修改,这在日常开发中极不方便。
2)每次构建增量资源包时必须保证要把全量资源包构建以来的所有修改的资源文件都要参与编译及打包。也就说,随着资源修改量的增加,越往后,参与编译及打包的资源数量会越来越大。而采用上面提到的方案,简单的讲,就是能做到完全不受累积的修改影响,每次修改在与手机同步后,这次修改就算清除了,后续编译也无需把此前的修改的资源文件拉进来参与编译打包。这也使得Freeline在修改UI时候能持续保持稳定的性能,不受修改范围的累积的影响。
资源索引Cache
resoucre.arsc是保存Android资源id索引的索引文件,在一些大型的app,arsc的体积不小,6m~10m是比较常见的情况,Freeline在arsc进行打包前,做了一个优化策略,当资源修改不引起arsc更新时,不会把arsc打包进增量包,避免无用的打包及TCP传输,采取的策略是,入参传入上一份arsc的md5,在aapt编译流程进行打包时,对C++层arsc内存块进行提前MD5计算,发现与上一份arsc的MD5不一致才进行打包。在大型的app(资源数量较大的)情况下,(tcp传输+打包+解包)可优化降低接近3~5s的时间。
全平台覆盖背后
构建过程选用python + java作为构建语言,其中py负责文件扫描,调度各个
工具(dx,smart-dex,merger,increment-res-tool),与手机建立tcp连接及传输增量包等。
C++编写的IncrementAapt 分别编译成3个不同平台运行库的方式,实现平台兼容。
非Art版本手机上,代码兼容方案是使用Asm技术在编译期动态修改基线包的Class字节码,在每个类构造函数插入外部dex的引用,使之绕开dvm的对Class 的安全检验,我们称之为“hackbyte”。
这里介绍下其原理:
在安装包进行安装流程里面的dexopt步骤会对DEX文件所有的Class文件进行扫描,当Class文件内所有直接引用到的类,与该Class均在同一个DEX,那么这个类就会被打上“CLASS_ISPREVERIFIED”标签。
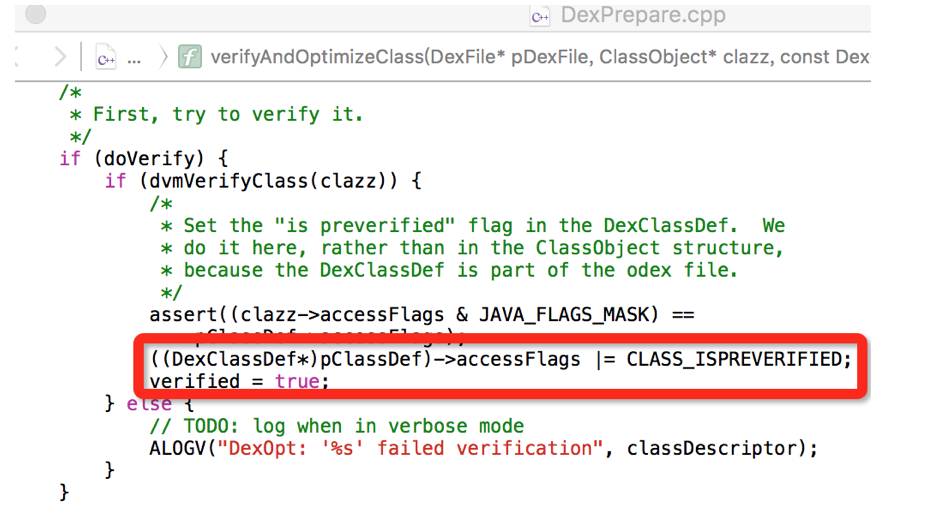
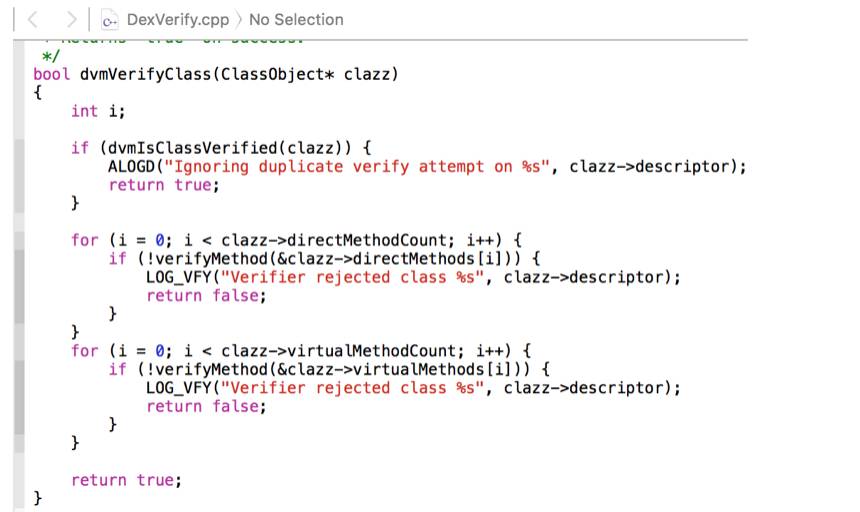
而被标上“CLASS_ISPREVERIFIED”的类,dvm在运行期载入Class时候,会对其内存中对应的直接引用类进行校验,如果该类存在与直接引用类所在的dex不是同一个,则直接报“pre-verification” 错误,该类无法加载(注意:无法加载的是这个被标上“CLASS_ISPREVERIFIED”的类,非其直接引用类),也就是说,若我们通过增量包推送进去的类作为其他类的直接引用类时候,这些引用了增量包里面类的类在加载时候就可能出现校验失败。
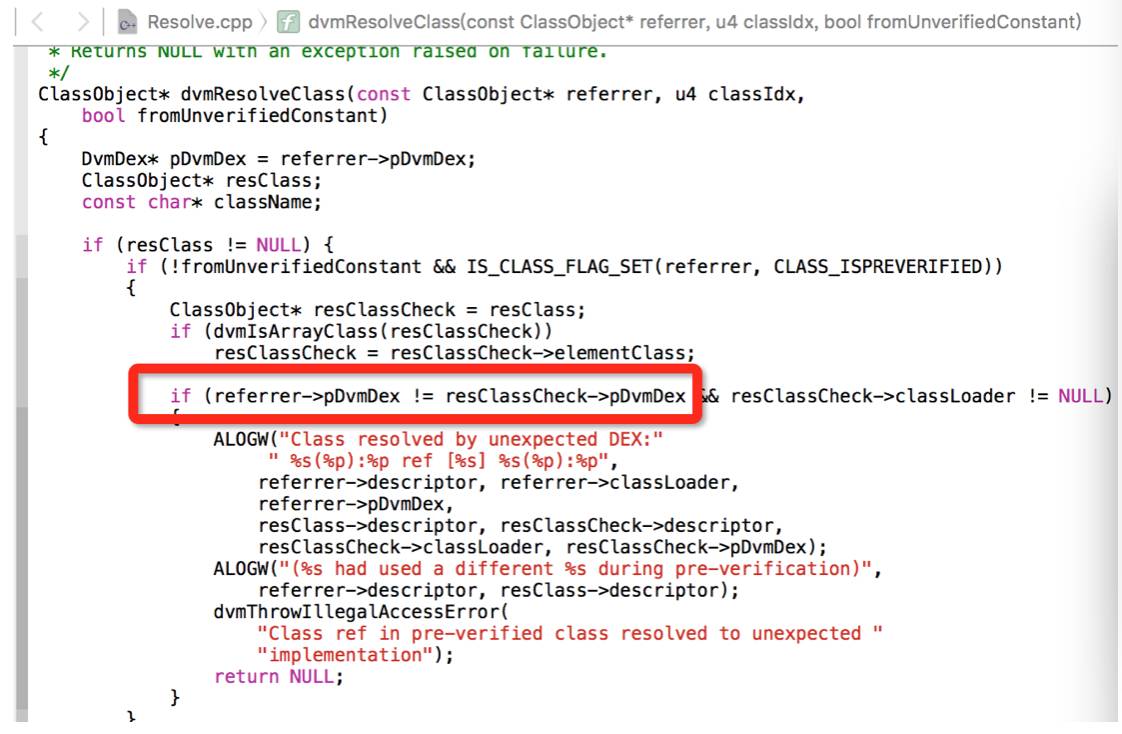
实际上上面这一步也是google为了防止外部DEX注入的一个安全方案,即保证运行期的Class与其直接引用类之间所在的DEX关系要与安装时候一致。
通过上面分析,只要一个类的存在直接引用类与该类不在同一个DEX,我们就可以让该类避免被贴上”CLASS_ISPREVERIFIED“的标签,接下来要做的事情只需要把自己工程的代码在编译之后,通过ASM技术动态修改Class字节码,给自己工程所有的Class植入一个来自其他DEX的类,注意这里只需要给我们自己能改的工程注入,对于第三方jar包,无需做这一步,因为依赖关系,第三方jar不会反过来引用我们的工程代码,也就不存在上面的问题。
最终,我们植入代码后,反编译出来的代码是这样子:
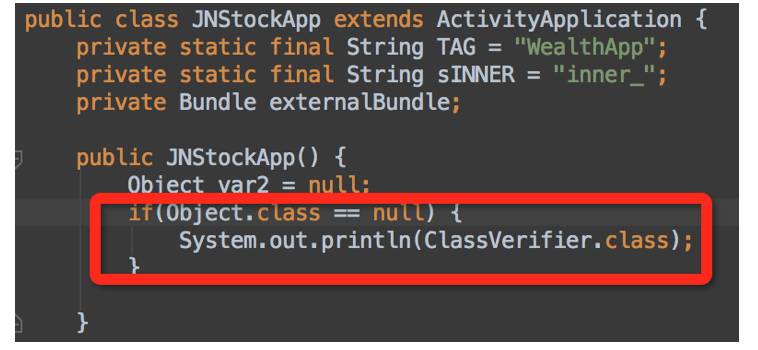
之所以选择构造函数植入因为其不增加方法数,其中ClassVerifier.class来自于一个单独的DEX,该DEX只有ClassVerifier.class一个类,在app启动时候,把该DEX注入到上面提到的DexList的最前面。则在5.x以下,该方案就会生效。
最后提一点,实际上业内,该方案也被应用到hotpatch里面,国内手机QQ空间的hotpatch就是这么做的。而我们是把其应用到增量构建方案里面。
细节处理
经过研究,在art上,dexopt过程中会对final class里面的基本类型进行优化,所有对final class的static变量进行访问,都会被优化成通过offset的方式进行访问,举个例子:
final class A {
public static int a = 1;
public static int b = 2;
}
假设我们在开发过程中,在a前间插入了一个新的变量:public static int a0 = 0;若通过上面的方案来进行代码增量,则会出现其他类访问a得到的值是a0的值,访问b得到的是a的值。也就是所有对的static。
int类型的值访问都被往下挪了一位,导致其他类在从这个被patch过的类获取到的值是不对的。最典型的就是R.java文件,里面如果用了类似buck来构建全量包,生成的R.java文件里面的field就是非final的,当我们新增了资源,即便我们通过前文提到的方式解决了资源id前后一致的问题,也无法保证新增的资源id其他类能正确访问到,甚至会导致其他类里面的通过”R.xxx.xxx“的形式访问资源id得到的值是乱掉的。
在这一点上面,freeline也进行了处理,目前采取的方案是在开发环境时候在Manifest.xml关闭android:vmSafeMode来解决。
篇幅问题,关于art上面对这个环节的优化及解决原理,后续打算以单独一篇文章来介绍,这里不细说。
数据对比
性能 :
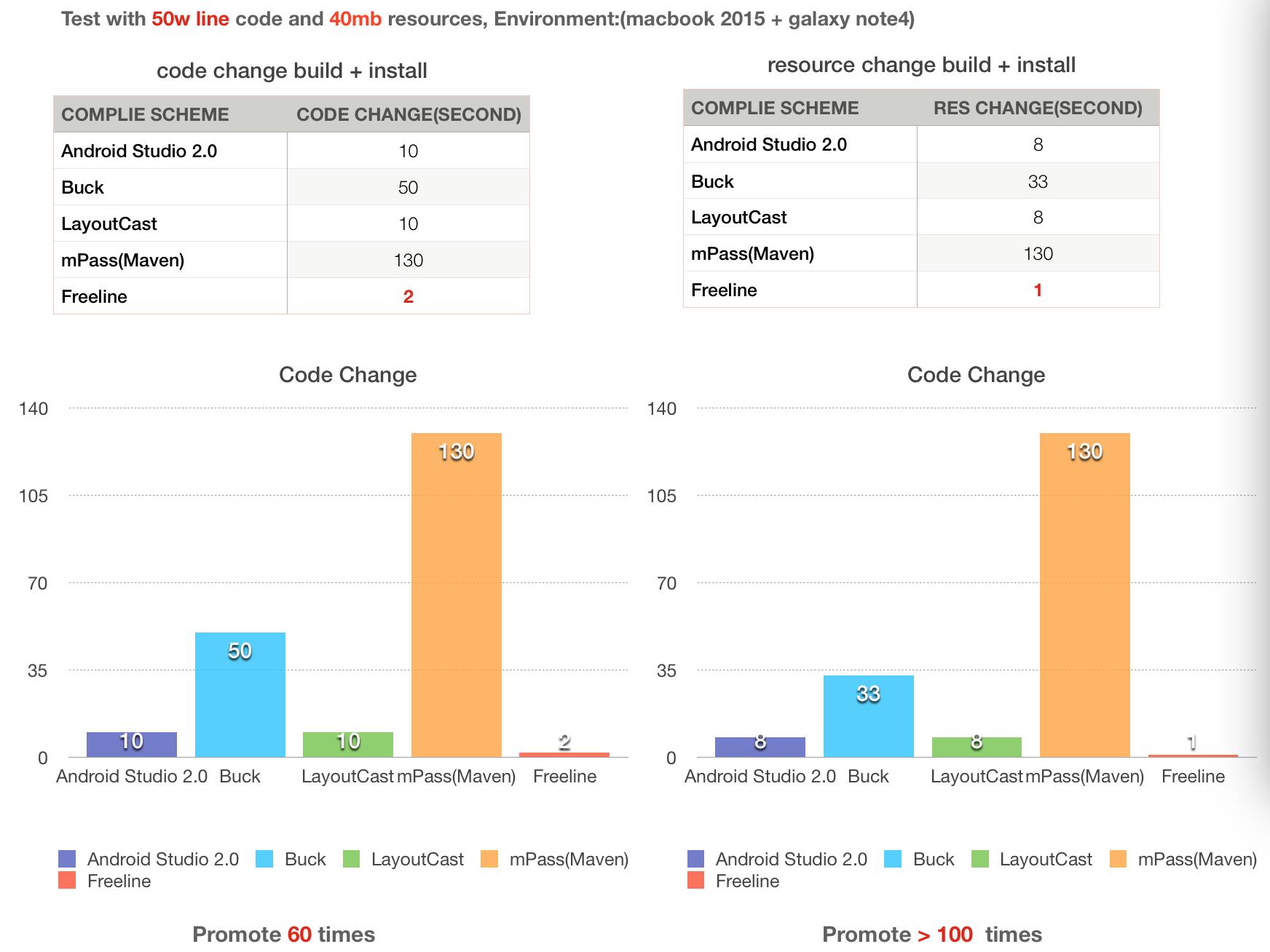
可见:较传统的maven构建方式,在增量模式下Freeline可提升数十倍的性能,与业内主流几个先进的构建方式比, Freeline仍然有数倍的速度领先。
兼容性 :
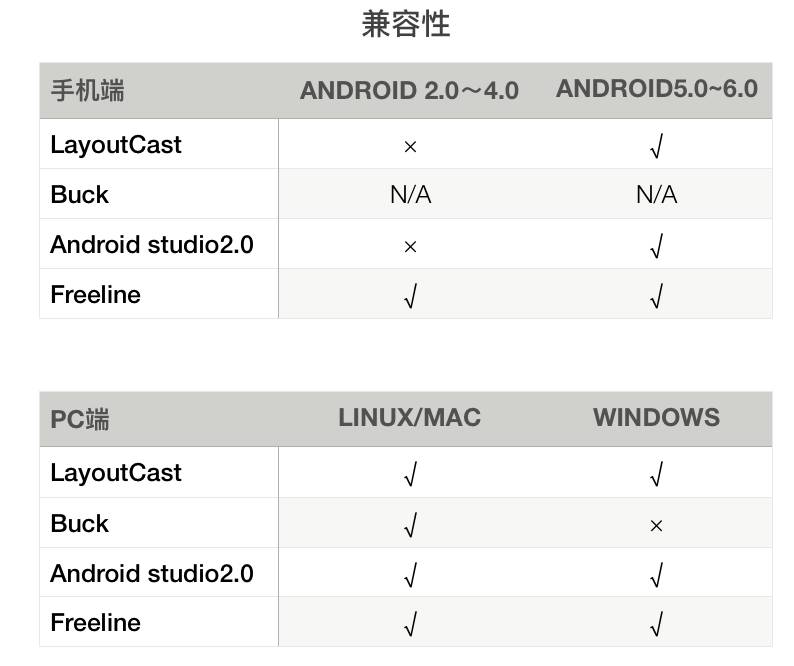
可见,Freeline相对于LayoutCast及AS2.0(手机端不支持Android5.0以下),Buck(pc端不支持windows)等构建方式,在 平台覆盖上更广。

福利君来啦!小伙伴们快奔走相告呐~
全开放免费注册,2天夜间技术交流、每场1.5小时深度分享、长时间互动 答疑、素材第一时间公开、用户组同步搭建。更有8位技术大牛线上与你 零距离!
[ 08月30日 ] 阿里技术架构演变,及基于EDAS的敏捷服务开发与架构实践 [ 08月30日 ] 支付宝亿级APP的性能稳定性优化及运维实践 [ 08月30日 ] 蚂蚁开放平台技术路线及行业实践 [ 08月30日 ] 云数据库OceanBase的架构演进及在金融核心系统中的实践 [ 08月31日 ] 云数据库系统容灾架构设计和实战 [ 08月31日 ] 大规模机器学习在蚂蚁+阿里的应用 [ 08月31日 ] 万人低头时代,支付宝APP无线网络性能该如何保障 [ 08月31日 ] 蚂蚁金服大数据开放式创新实践










