
豌豆贴心提醒,本文阅读时间7分钟
今天主要讲述的内容是关于决策树的知识,主要包括以下内容:
1.分类及决策树算法介绍
2.鸢尾花卉数据集介绍
3.决策树实现鸢尾数据集分析
希望这篇文章对你有所帮助,尤其是刚刚接触数据挖掘以及大数据的同学,同时准备尝试以案例为主的方式进行讲解。如果文章中存在不足或错误的地方,还请海涵~
一. 分类及决策树介绍
1.分类
分类其实是从特定的数据中挖掘模式,作出判断的过程。比如Gmail邮箱里有垃圾邮件分类器,一开始的时候可能什么都不过滤,在日常使用过程中,我人工对于每一封邮件点选“垃圾”或“不是垃圾”,过一段时间,Gmail就体现出一定的智能,能够自动过滤掉一些垃圾邮件了。
这是因为在点选的过程中,其实是给每一条邮件打了一个“标签”,这个标签只有两个值,要么是“垃圾”,要么“不是垃圾”,Gmail就会不断研究哪些特点的邮件是垃圾,哪些特点的不是垃圾,形成一些判别的模式,这样当一封信的邮件到来,就可以自动把邮件分到“垃圾”和“不是垃圾”这两个我们人工设定的分类的其中一个。
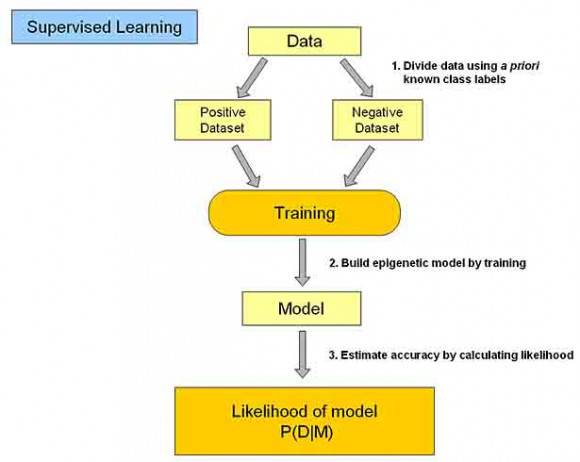
分类学习主要过程如下:
(1)训练数据集存在一个类标记号,判断它是正向数据集(起积极作用,不垃圾邮件),还是负向数据集(起抑制作用,垃圾邮件);
(2)然后需要对数据集进行学习训练,并构建一个训练的模型;
(3)通过该模型对预测数据集进预测,并计算其结果的性能。
2.决策树(decision tree)
决策树是用于分类和预测的主要技术之一,决策树学习是以实例为基础的归纳学习算法,它着眼于从一组无次序、无规则的实例中推理出以决策树表示的分类规则。构造决策树的目的是找出属性和类别间的关系,用它来预测将来未知类别的记录的类别。它采用自顶向下的递归方式,在决策树的内部节点进行属性的比较,并根据不同属性值判断从该节点向下的分支,在决策树的叶节点得到结论。
决策树算法根据数据的属性采用树状结构建立决策模型, 决策树模型常用来解决分类和回归问题。常见的算法包括:分类及回归树(Classification And Regression Tree, CART), ID3 (Iterative Dichotomiser 3), C4.5, Chi-squared Automatic Interaction Detection(CHAID), Decision Stump, 随机森林(Random Forest), 多元自适应回归样条(MARS)以及梯度推进机(Gradient Boosting Machine, GBM)。
决策树有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析;2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
下面举几个例子。
示例1:
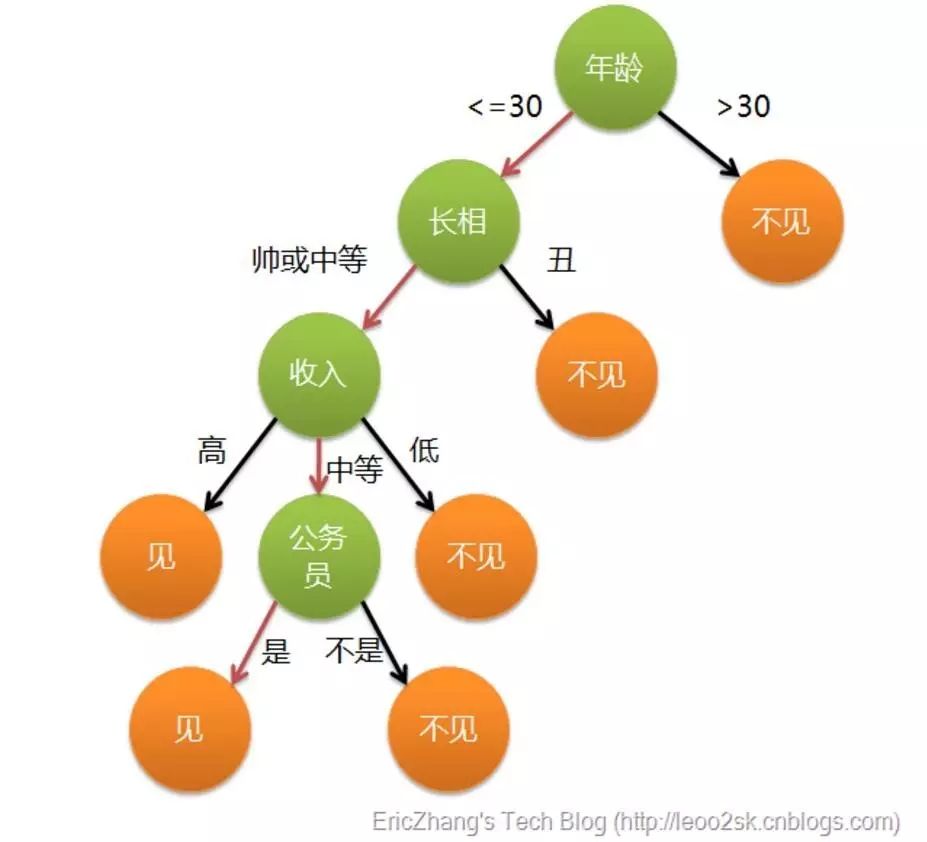
通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑。
示例2:
假设要构建这么一个自动选好苹果的决策树,简单起见,我只让他学习下面这4个样本:
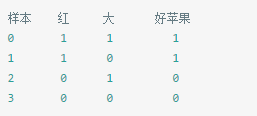
样本中有2个属性,A0表示是否红苹果。A1表示是否大苹果。
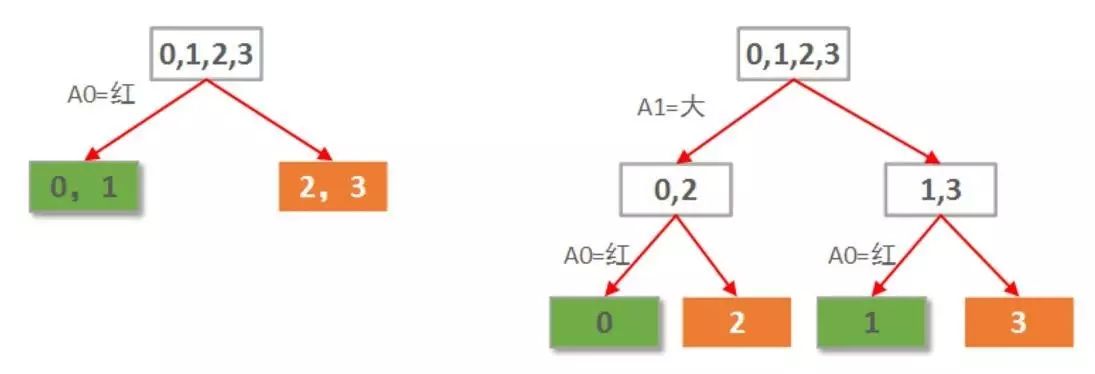
本例仅2个属性。那么很自然一共就只可能有2棵决策树,如下图所示:
示例3:
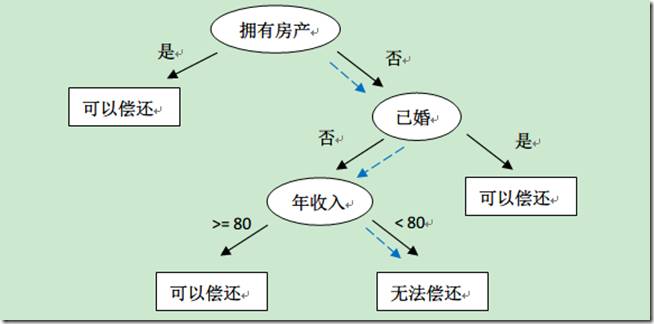
决策树构建的基本步骤如下:
a.开始,所有记录看作一个节点;
b.遍历每个变量的每一种分割方式,找到最好的分割点;
c.分割成两个节点N1和N2;
d.对N1和N2分别继续执行2-3步,直到每个节点足够“纯”为止。
二. 鸢尾花卉Iris数据集
在Sklearn机器学习包中,集成了各种各样的数据集,上一节讲述Kmeans使用的是一个NBA篮球运动员数据集,需要定义X多维矩阵或读取文件导入,而这节课使用的是鸢尾花卉Iris数据集,它是很常用的一个数据集。
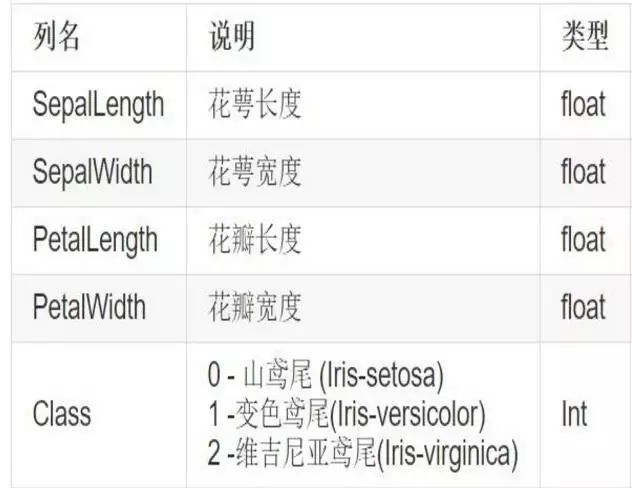
该数据集一共包含4个特征变量,1个类别变量。共有150个样本,鸢尾有三个亚属,分别是山鸢尾 (Iris-setosa),变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。
iris是鸢尾植物,这里存储了其萼片和花瓣的长宽,共4个属性,鸢尾植物分三类。
iris里有两个属性iris.data,iris.target。
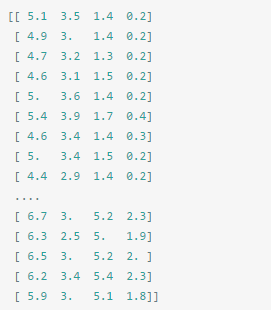
data里是一个矩阵,每一列代表了萼片或花瓣的长宽,一共4列,每一列代表某个被测量的鸢尾植物,一共采样了150条记录。代码如下:
输出如下所示:
target是一个数组,存储了data中每条记录属于哪一类鸢尾植物,所以数组的长度是150,数组元素的值因为共有3类鸢尾植物,所以不同值只有3个。种类:
Iris Setosa(山鸢尾)
Iris Versicolour(杂色鸢尾)
Iris Virginica(维吉尼亚鸢尾)

输出结果如下:

可以看到,类标共分为三类,前面50个类标位0,中间50个类标位1,后面为2。
下面给详细介绍使用决策树进行对这个数据集进行测试的代码。
三. 决策树实现鸢尾数据集分析
1. DecisionTreeClassifier
Sklearn机器学习包中,决策树实现类是DecisionTreeClassifier,能够执行数据集的多类分类。
输入参数为两个数组X[n_samples,n_features]和y[n_samples],X为训练数据,y为训练数据的标记数据。
DecisionTreeClassifier构造方法为:





