选自the Verge
作者:James Vincent
机器之心编译
参与:Ellen Han、黄小天
威廉·吉布森(William Gibson)写于 2010 年的小说《零历史(Zero History)》中有这样一个场景:一个角色穿着迄今为止「最丑陋的 T-shirt」展开了危险的突袭,T-shirt 可使其对闭路电视(CCTV)隐身。在尼尔·斯蒂芬森(Neal Stephenson)的小说《雪崩(Snow Crash)》中,一个位图图像被用来传递可扰乱黑客大脑频率的病毒,借助计算机增强的视觉神经以腐蚀目标者的心智。诸如此类的故事形成了一种循环往复的科幻比喻:一张普通的图像具有摧毁计算机的能力。
不管怎样,这个概念并非完全虚构。去年,研究者仅仅带上花式眼镜(patterned glasses),一个商用面部识别系统就做出了错误识别。花式眼镜就是在镜框上贴上迷幻色彩的贴纸,花式的扭曲和曲线在人看来是随机的,但计算机却要在带有花式眼镜的人脸上分辨出五官,而且这些人脸的轮廓很相似。花式眼镜不会像吉布森「最丑陋的 T-shirt」那般将其从闭环电视中抹去,但是它可使人工智能错认为你是教皇,或者其他人。

带有花式眼镜的研究者以及人脸识别系统的对应识别结果。
这些类型的袭击包含在被称为「对抗机器学习(adversarial machine learning)」(之所以如此称呼是由于对手之类的存在,在该情况中,对手是黑客)大量网络安全类别中。在这一领域,「最丑陋的 T-shirt」以及腐蚀大脑的位图的科幻比喻表现为「对抗性图像」或者「愚弄式图像」,但是对抗性袭击具有形式,如音频甚至是文本。2010 年早期,大量的团队各自独立发现了这一现象的存在,他们通常把可对数据进行分类的机器学习系统「分类器」作为目标,比如谷歌图片中的算法可为你的照片打上食物、假期和宠物等标签。
对于人而言,愚弄式图像就像是一个随机的扎染图案或者突发的电视噪点;但是对图像分类器而言,它却可以自信的说出:「看,那是一只长臂猿」或者「一个如此亮眼的红色摩托车」。就像花边眼镜使人脸识别系统发生了错误识别,分类器处理了混乱到人类永远无法识别的图像视觉特征。
这些图案可以各种方式绕过人工智能系统,并对未来的安全系统、工业机器人和自动驾驶汽车等需要人工智能识别物体的领域有重大意义。2015 年有关愚弄式图像论文的联合作者 Jeff Clune 告诉 The Verge:「想象一下你身处军队,正在使用一个自动锁定目标的武器系统,你绝不希望敌人把一张对抗性图像放在了医院的楼顶,系统锁定并攻击了医院;或者你正在使用同一个系统追踪敌人,你也绝不喜欢被愚弄式图像骗了,[并] 开始用你的无人机紧盯着错误的目标车辆。」
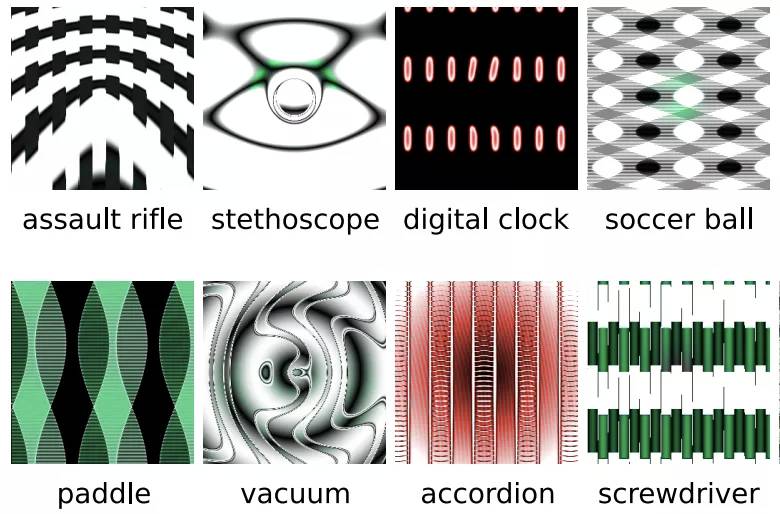
愚弄式图像以及人工智能识别的对应结果。
这些情节是假设的,但却非常具有可行性,如果继续沿着当前的人工智能路径发展。Clune 说:「没错,这是一个研究社区需要共同面对的大问题。」防御对抗性攻击的挑战有两方面:我们不仅不确定如何有效地反击现有攻击,而且更多高效的攻击变体在持续增长。Clune 及其联合作者 Jason Yosinski 和 Anh Nguyen 描述的愚弄式图像容易被人类发现,它们就像是视觉幻觉或者早期的网络艺术,满是斑驳的色彩与图案重叠,但是有更为微妙的方法运用它们。
摄动可像 Instagram 滤镜一般被用于图像
有一类被研究者称为「摄动(perturbation)」的对抗性图像几乎对人眼不可见,它作为照片表面上的像素涟漪(ripple of pixels)而存在,并可像 Instagram 滤镜一般被用于图像。这些摄动发现于 2013 年,在 2014 年一篇名为「解释和利用对抗性实例(Explaining and Harnessing Adversarial Examples)(链接:https://arxiv.org/abs/1412.6572)」的论文中,研究者演示了摄动的灵活性。摄动有能力愚弄一整套不同的分类器,即使没有被训练来攻击的分类器。一项名为「通用对抗性摄动(Universal Adversarial Perturbations)(链接:https://arxiv.org/pdf/1610.08401v1.pdf)」改进研究通过成功地在大量不同的神经网络上测试摄动,使得这一特征明确起来,上个月引起了众多研究者们的关注。
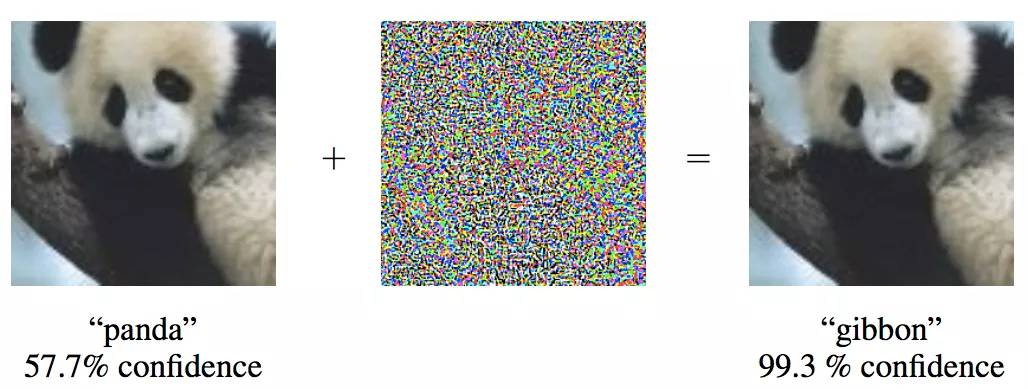
左边是原始图像,中间是摄动,右边被摄动的图像。
使用愚弄式图像黑进人工智能系统有其局限性:第一,需要花费更多时间制作加扰的图像,使得人工智能系统认为其看到的是一张特殊的图像而不是产生了随机错误。第二,为了在起初生成摄动,你经常——但不总是——需要获取你要操控的系统的内部代码。第三,攻击并不是一贯高效。就像论文「通用对抗性摄动」所述,在一个网络中成功率为 90% 的摄动也许在另外一个网络之中只有 50-60% 的成功率。(也就是说,如果一个存在问题的分类器正在指引一辆自动驾驶半式卡车,甚至 50% 的错误率都是灾难性的。)








