加入雷锋网,分享AI时代的信息红利,与智能未来同行。听说牛人都
点了这里
。
今年的互联网大会现场,搜狗 CEO 王小川将自己的演讲内容用搜狗语音实时翻译成中英对照的形式,“技惊四座”的同时,也让各位看官们觉得代替同传的工具要来了。虽然搜狗语音实时翻译将王小川说的“搜索的未来就是人工智能时代的皇冠”准确翻译成了“In the future, search will be the Crown of the AI Era”,但王小川坦言,在演示之前没做预先的试验,对效果并没有把握,就连他也是捏着一把冷汗,也不认为机器可以把人干掉。
然而,新技术的突破总会让人感到兴奋。谷歌和讯飞对机器翻译与语音翻译新进展的披露也是如此。
近日,搜狗语音交互中心开了一场媒体沟通会,向大家对搜狗语音翻译技术进行了解析。据搜狗语音交互中心技术负责人陈伟介绍,搜狗实时翻译技术是搜狗知音引擎技术框架的新能力,按照量化的指标,准确率可以达到90%。此外,搜狗语音识别请求规模现在达到了1.84 亿次左右,语料达到了16万小时,在使用场景方面,主要集中在车载、智能家居和可穿戴设备。
以下是陈伟对搜狗实时翻译技术的讲解,在不改变原意的情况下对原文有删减。
●
●
●
先判断
8月3日发布搜狗知音引擎时,我们提出了一个口号,“更自然的语音交互”,包括从说到听到理解三个过程,其中就涵盖了语音识别。但现在三个月的时间过去了,知音引擎又具备了新的能力以及新进展。今年下半年,基于已有的深度学习平台和技术,搭建了我们自己语音翻译技术,这是无到有的技术。在谷歌神经网络翻译技术刷屏之前,我们就已经把这个技术用运用在我们的后台了,从口语来看,我们的技术比 Google 要强一些。
与以前语音识别相比,实时翻译技术框包括了语音识别、机器翻译两个大的方向,其次是一些细节的优化与系统的调优。
从系统框架来看,第一步就是如何断句。我们需要支持长时间的语音识别,另外,还要做到实时。语音识别的反映时间是2秒,翻译要尽量做到实时同步,要先根据听停顿一集其他的信息分成短的语音片段进行识别断句。
语音的时间概念是按帧来划分的,一帧是 20-30 毫秒左右的一个小片段。人在发音的时候,小片段之间有协同发音的现象,帧与帧之间有重叠,我们称之为帧移。
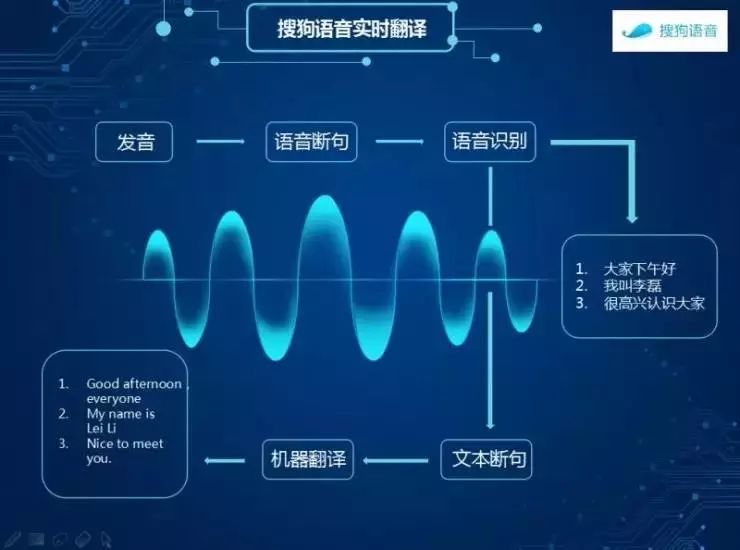
当有一个特别长的语音信号的时候,系统要判断什么时候是静音,什么时候是有效的语音,通常用 0(非语音)、1(语音)来标记。一般来说,判断的方法有两种:第一是基于能量检测的方式,能量小就是静音,能量大就是语音;第二是基于深度学习模型的判断,通过大量的数据进行建模,建模之后可以通过模型自动检测,根据非语音概率的高低来判定是否为语音。根据以上判断,我们就会得到一些语音序列。
对于判断不准的地方,我们要做平滑处理。按照规则,我们把出现一些比较奇异、不太正常的点去掉,生成一个看上去比较规整的结构。
做语音断句主要有两个好处:省去静音片段的语音识别,可提升整体识别效率;语音判断可以区分成很多句送到框架下面,大大提高了语音识别的次数。
●
●
●
再识别
接下来是对判断进行语音识别。语音和文本之间的影射通过一种概率的目标来描述,这个概率目标希望给定当前的语音信号,最大化输出W的概率,输出对应的W区别就是我祯正想要的最优语音识别结果,在语音识别框架下面,涉及到两个非常重要的模型,一个是声学模型,就是人在发音每个单元的时候这个模型和声音信号之间的相似形,另一个是语言模型,描述的就是识别结果中词和词之间连接的可能性,从而更好地规范整个的输出结果,更加通顺、流畅。
两种模型,共通输出一个文本结果,叫做搜狗语音。
从2012年开始,我们逐步开始用这种系统框架后,做了非常多的思考和探索,目前比较稳定的线上系统是 CLDNN 系统。集合了三种不同的机构 CNN(卷积神经网络层)、5LSTM(长短记忆模型) 与 DNN。CNN 可以对变换祈祷不变性的作用,5LSTM 能够将非常长的上下文以及历史或将来的信息融入到当前的识别中来,DNN 可以提出非常深层的抽象特征。三层结构融合在一起,形成了线上主流的机构。但这只是线上的结构,除此之外,我们也在探索一些新的结构。
除了刚才说的两种模型,加上深度学习的整合,也就是神经网络技术。可以让非常复杂的流程变换成一个非常清爽、单一的端到端的影射。我们认为,端到端的技术可能是将来人工智能基于学习非常重要的发展趋势。
语音信号处理的机构是 CTC ,所以综上,我们驻留在用的机构就是 CTC+ CLDNN。
●
●
●
做断句
第三部分就是文本断句,如何切分比较细的断句呢?第一是内容平滑,我想找你去吃饭,不知道你有没有空?有几个问题,里面出现了很多的语气词,对后面的翻译和用户理解没有太多的作用,我们需要把这种语气词去掉。还有一些重复词也要去掉,内容平滑以后,就会变成比较通顺的话。
怎么切分成比较独立的单句呢?解决方法是进行词序划分、加标点。方式有两种,一种是基于规则的方式,即用户在说话时,一旦出现停顿,就判断为前面比较完整的语音句子已经说完了;另一种是基于模型的方式,人在讲话时,停顿点可能会是在句中,不一定是在句尾,这就需要用基于词序模型进行划分。
在识别和翻译之间最为关键的一个桥梁就是文本断句,这个模块是可以让语音实时翻译放到实际场景中进行使用的重要原因。
●
●
●
要对齐
另外就是输出判断,用户一直在说话,我们是实时出结果,我怎么知道用户这句话说没说完?不知道你有没有空、来找我吃饭?下一个语音过来的时候,可能是接着这个空来说的,所以我们需要判定,在什么时候需要把这句话送给翻译去翻译,所以输出判定决定输出结果哪部分送给翻译,哪一部分留下来再做决策之后送到翻译模块里,所以这块也是我们在今后需要着重优化和改善的功能。
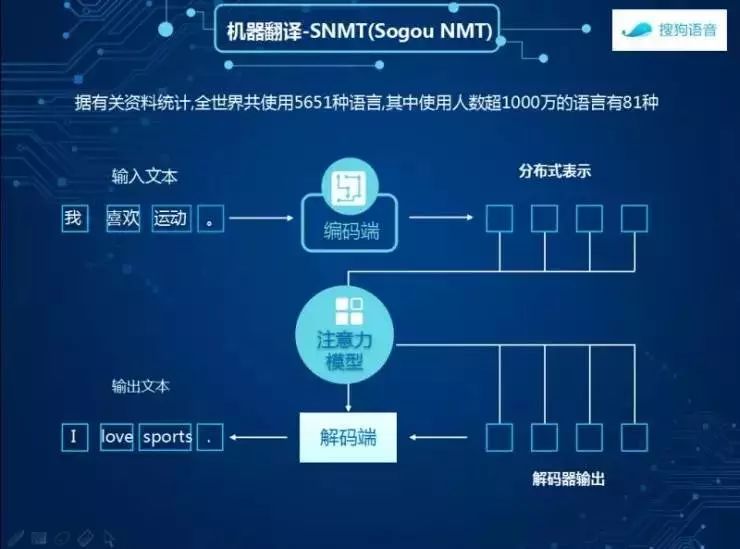
以前的方法更多是把整个的翻译切分成单词、短语,把中文、英文短语之间的影射关系建立起来,解决的是对齐的问题,会有一些对应的关系,对应的关系建立起来以后,使用语言模型把中文翻译成英文以后的各种小短语,就是机器翻译的技术。
最近机器翻译逐渐迁移到了基于神经网络的技术,这个技术是非常清爽的结构,是一个端到端的影射,我喜欢运动,进入到一个编码器,这个编码器会把我喜欢运动进行整句上面的翻译,或者每一个单词建立一个词向量,这个已经具备了语译的能力,进行进一步的特征提取,就会得到编码器的解释。
之后是进入对齐,现在完成交给模型去做,模型告诉你哪些词和哪些词可以对应在一起,是自己学习出来的。当把这些词语的特征贡献到解码端以后就会出来文本,起到一个端到端的影射作用。
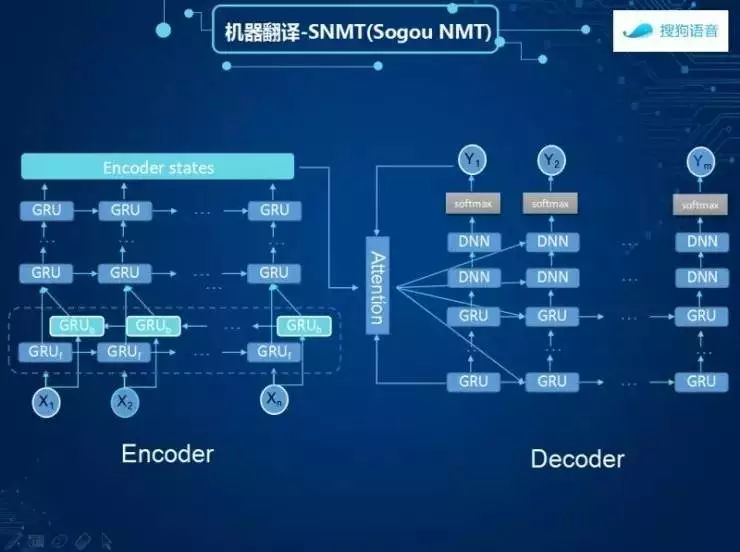
这个结构是这样的,这是更加详细的结构,第一部是编码端的技术,最后是Decoder。准确率上我们实际评测来看,GRU的结构会更轻便,而且运算的速度更快,目前的同传技术里面,我们用到的是GRU结构,使用双向的GRU技术,共同构建编码端的结构。解码端共同抽象以后接入到Softmax里面输出结果。
真正的模型是需要跟数据结合非常紧密,你只有有了大的数据才能学习出复杂的模型,刚才的模型结构非常的复杂,我会觉得对目前机器翻译而言,搜索公司在语料上面的积累,非常有助于我们在很多领域完全机器翻译比较好的产品。
●
●
●
后记
王小川在互联网大会上说,搜狗现在的语音识别准确率在95%-97%之间,取决于语音环境。陈伟告诉雷锋网,搜狗语音识别加机器翻译的准确率在90%,技术的研发只用了三个月左右的时间,语音翻译的终极梦想是能输入一个语音后,可以直接出对应的结果,中间所有的事情都交给模型去做。毫无疑问,神经网络给翻译行业带来了一个新的质变。










