拿到一个数据集,你先检查了数据源的质量,然后通过数据清洗提升了数据集的质量,再通过平均数的计算了解了数据集大小的一般水平,接着又通过方差和标准差了解了波动变化。经过这一系列的操作,你对数据有了一定的认知。但这就够了吗?答案是否定的。在数据的快速认知中,我们还需要对数据分布进行探索。这部分工作比较难理解,但若能掌握,往往能帮助你快速做出决策。
要认知一个数据序列的分布如何,首先我们要计算最大值、最小值、中位数、算术平均数、75%分位数和25%分位数。如下图,我们沿用了上一小节的例子,计算了川术公司7月份和8月份每日业绩数据的相关指标。从表格中,我们可以看到,8月份的最大值明显高于7月份,而最小值明显低于7月份,说明8月份的数据相比7月份更为“分散”。我们将最大值减去最小值所算得的数字称为“全距”。全距部分反映了数据点的分散情况。为什么说是部分反映呢?若一个数据序列的最大值特别大,最小值特别小,而其他数值却非常接近,那么全距就不能真实反映这个数据序列的离散情况了。那么这个时候需要怎么衡量?我们需要百分位数。
所谓的百分位数,即将数据升序排列后,具体数据值的序号除以数据值的总数,所得出的百分比,即该数据值所对应的百分位数。比如,有一个数据序列(1,2,2,3,4,4,5,6,8,10),按升序排列后,数字6排在这个序列的第8位,那么这个数据序列的80%分位数就是6。我们最为常用的是25%分位数和75%分位数,称为四分卫数。而两个四分位数的差(四分卫差),与全距一起使用,就能比较准确的判断数据序列的离散情况。中位数即50%分位数。你可以用PERCENTILE()函数试着计算一下下图中的两个四分卫差,看看结论如何?
数据序列的离散度与波动性是存在关系的,往往序列的离散度高,标准差也会更大。另外,查看算术平均数与中位数的差距,也具有现实意义。若一个数据序列,数据点均匀的分布在最大值到最小值之间,那么算术平均数会几乎等于中位数;若一个数据序列,数据点的分布不均匀,那么算术平均数与中位数的偏差就会比较大。往往算术平均数与中位数差距大的数据序列,我们需要格外用心地去分析。
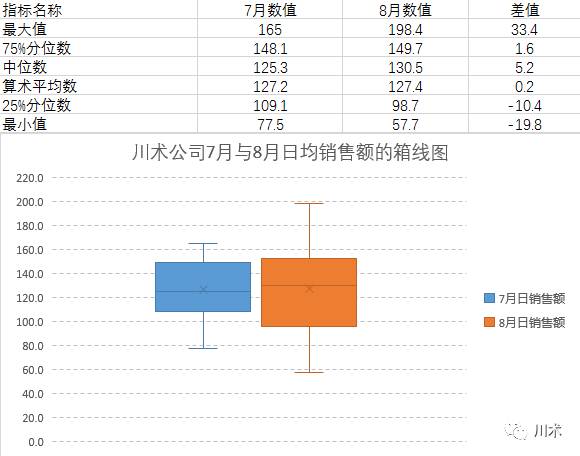
上图中的图形大家也许会陌生。在第二章中我们没有讲解这种箱线图的用法。但此时此刻,相信大家都已经发现了,箱线图就是用来观察数据的离散情况的。有顶部到底端,箱线图由6个数字构成:最大值、75%分位数、中位数、25%分位数、最小值及用“×”标出的算术平均数。箱线图整体越长,说明数据序列的全距越大;内部的矩形(箱子)越长,说明四分位距越大。
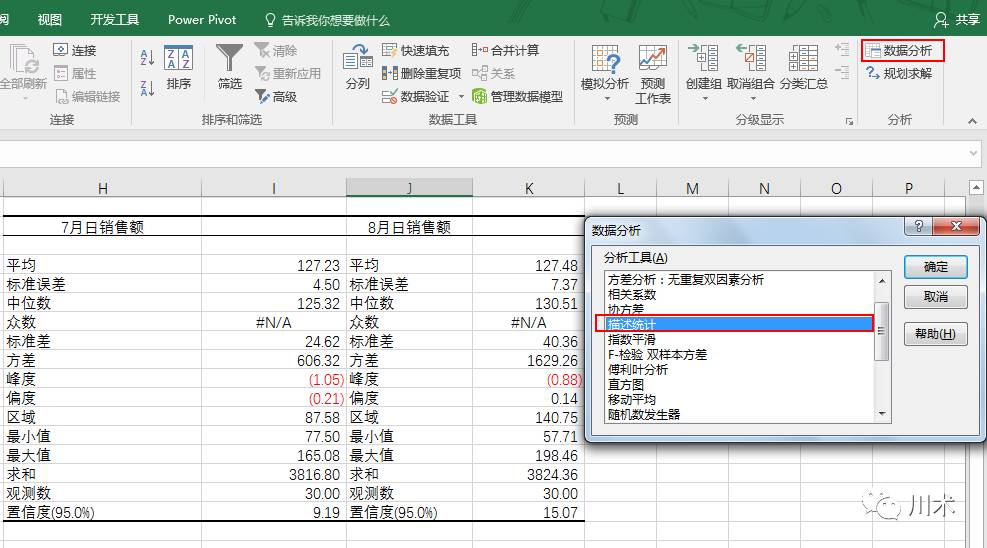
对于快速计算描述统计量,Excel的“数据分析模块”提供了一种便捷的方式。在“数据”选项卡中点击“数据分析”模块,选择“描述统计”,就会弹出一个设置框。如下图所示,在设置框中选择好数据输入区域,然后勾选“汇总统计”,点击确定后,就能出现结果。如下图中,7月份和8月份的日度的销售业绩数据已经工整地计算出来了。我个人是习惯于使用这个“描述统计”功能的。在数据清洗好后,先对自己关注的数据使用,查看一下各个描述统计量的情况,我就对数据集有了快速的了解。唯一的遗憾是它没有提供四分卫数的计算结果。
对本小节提到的统计量的计算方式做一个罗列:最大值MAX();最小值MIN();中位数MEDIAN();分位数PERCENTILE();算术平均数AVERAGE()。
在最大最小值和分位数里绕了半天,认识数据分布特征还没结束?是的,好戏开始了。我们将第二章中欲言又止的“频率分布图”搬出来。频率分布图实在是观察数据分布的第一神器。在Excel中的制作方式依然非常方便,只要选择需要做图的数据列,点击“插入图表”,再点击“频率分布图”,就能制作完成。略微调整参数后,频率分布图会展现神奇的魔力。
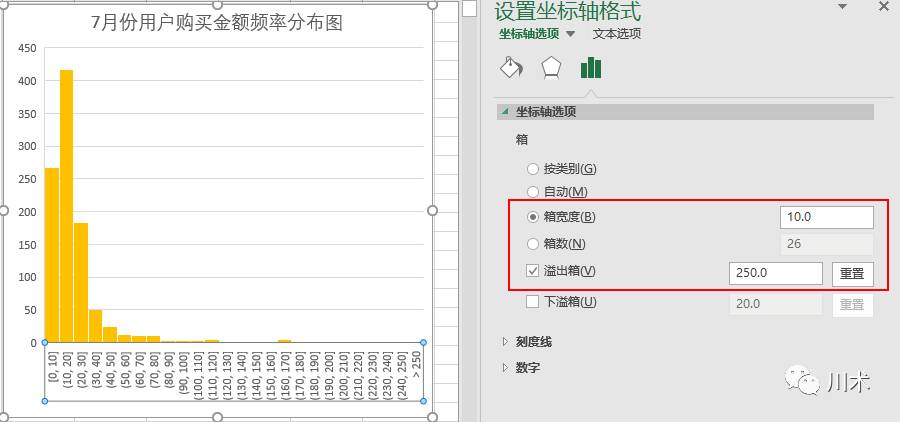
何为频率分布图呢?这里的分布,意思是将数据序列的全距进行切割,分为数据间隔一致的若干个小块,称为“箱”;然后按每个数据点的大小,将其放进所属的箱当中,每个箱里的数据点的数量,即是频率,最后把每个箱里的数值个数用柱形图表现出来,就是频率分布图。在频率分布图的制作过程中,最关键的就是“坐标轴选项”当中的“箱宽度”、“箱数”、“溢出箱”和“下溢箱”四个参数。如下图,展示了制作频率分布图中箱参数的设置的过程。以我的经验,制作频率分布图,关键是将箱的数量控制在合理的数字。箱数太少,你观察不出数据的分布特征,箱数太多亦然;箱数最好控制在20-50个之间。
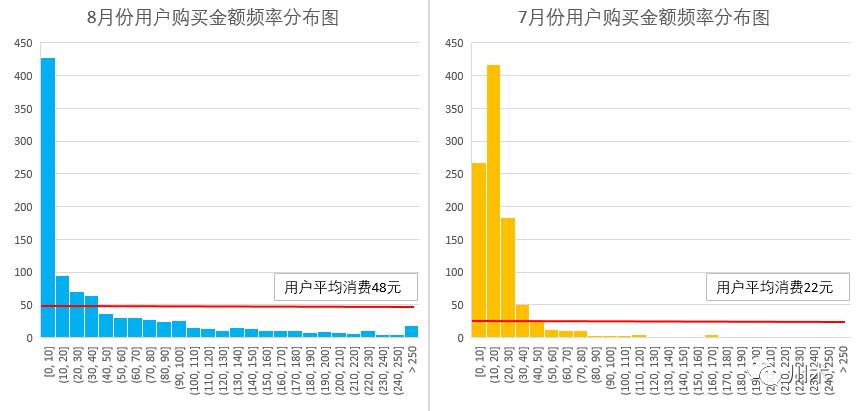
我们再以一个具体的模拟案例来阐释频率分布图的功能。我又把你放到川术公司CEO的位置上了。假设你英明神武地在你的SAAS产品中开发了一个C2C的零售平台,让你的用户们可以互相兜售自己的产品。有了这个产品,作为数据分析师出身的你,对用户的消费行为产生了好奇。那么如何去观察用户消费行为的变化呢?在计算了均值、标准差、全距、箱线图后,你都觉得不够满意,总觉得没有得到真正的信息。于是你随机在7月和8月的用户中各抽取了1000个人作为样本,画出了两个月用户购买金额的频率分布图。如下图,你大吃一惊,再用辅助线将人均购买均值标注之后,你觉得这里面大有文章。
7月份的分布图是先增长后快速衰减,进而衰减到0;而8月份是先快速衰减,但之后衰减缓慢并形成拖尾,在大于250元的区间还出现了翘尾。这是截然不同的两种分布形态,在实际业务中几乎不会出现。为什么会出现如此巨大的变化呢?你从市场的产品结构,卖家特征和产品价格上进行分析后,得出了大致的原因:原先的市场类似跳蚤市场,用户只是上来兜售一些二手的小东西,产品品类少且卖家没有成型的销售体系;随着市场流量的增加,一些专业的卖家开始进驻,产品品类快速扩充,销售能力提升,单价也随之提高;于是形成了两种结果,一是用户的消费金额提高,二是原先在10-30区段的用户,一部分转移到了10元以下,即购买次数减少了,另有相当一部分的购物欲望被激发,渐渐成为了剁手族,于是在消费金额的分布中形成了拖尾群体。
频率分布图的应用其实非常广泛,最为典型的一种应用是确定某种阀值。在阀值的确定这种分析场景中,我们经常会用到一种称为“肘”的方法。使用该方法的前提是在频率分布图中画出累加频率曲线。什么是累加频率曲线呢?如下图,累加频率曲线就是从左到右,将每个箱里面的数值个数累加,累加值除以数据序列的总数字个数,得出的百分比。累加频率曲线越平缓,说明数据的分布越分散,即每个箱中都有相当多的数据。下图中8月份的累加频率曲线就比7月份要平缓得多,毕竟8月份的分布有明显的长尾效应。
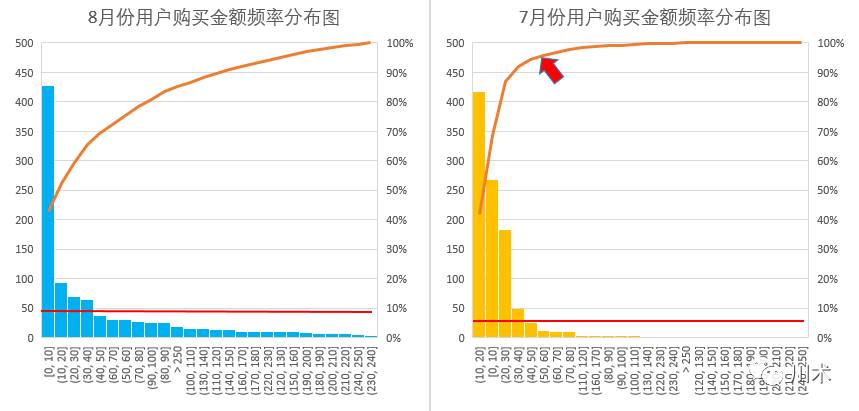
那么“肘方法”怎么用呢?往往是用在我们需要付出某些额外的代价,来使数据分布向右平移时,需要使用肘方法来确定一个施予额外代价的起始点。目的在于实际投入少,却能有效拉动分布右移。我们以上图7月份的频率分布图为例。假设我们需要做一次促销满送活动,希望提高平台中整体用户的消费额,即在频率分布图中,购买金额较低的用户要向高的箱子去移动。那么我们满送的起点制定在哪里?是满30就送还是满70再送?答案是寻找累加频率曲线的“肘部”,即箭头标出的部分。在肘部之后,其实整体的用户量已经只有5%左右了,但消费额却还非常靠近横坐标的起点,为50左右,在30以内的消费者看来,离50的距离很近,因此他就会有意愿多买一点去达到50,而对于平台来说,满50才送礼品,钱只花在了少部分人身上。从经验上说,累加频率曲线的肘部拐得角度越大,由肘方法确定阀值所带来投入产出比越高。
那么如8月份的数据,没有“肘”怎么办呢?凉拌!对于已经是长尾的分布形态,增加成本去让长尾更厚往往是不划算的。这个时候建议还是选择拉新,让分布里总的数据个数增加。









