
2017年是ImageNet挑战赛举办的最后一年,当地时间7月26日,谷歌云首席科学家李飞飞在CVPR的舞台上最后一次谈论了ImageNet挑战赛的年度成果。创办至今的7年时间内,该挑战赛中胜出的算法对物体进行识别的准确率从
71.8%上升到97.3%
,
这已经超过了人类的能力
。
尽管挑战赛已经结束,但它已经对人工智能的诸多领域产生了深远的影响。自2009年以来,在计算机视觉、自然语言处理和语音识别等领域,研究者们先后引入了数十个新的数据集。
李飞飞说,
ImageNet让我们的思维模式发生了转变,当很多人都只在关注模型时,我们却在关注数据,
数据将重新定义我们对模型的看法。而该比赛也有效地证明了,更大的数据可以带来更好的决策。
回顾
ImageNet
这8年的历程,我们可以看到数据是如何成为这个时代的新石油。

图丨李飞飞
ImageNet诞生记
2006年,李飞飞就开始酝酿一个想法。
当时,她还是伊利诺伊大学香槟分校的一名刚刚毕业的计算机科学教授,她看到她的在学术界和人工智能行业的同事们都在遵循同样的理念:不管数据如何,更好的算法总能做出更好的决策。
但是她意识到这种方法的局限性——即使是最好的算法,如果它没有反映真实世界的数据,也不会很好地发挥作用。
她的解决方案是:
构建一个更好的数据集
。
“我们决定要做一件完全史无前例的事情,”李说,“我们要绘制出整个物体世界的数据”(“我们”指的是一个最初和她一起工作的小团队)。

她们最终生成的数据集被称为ImageNet。该数据集最初于2009年在迈阿密海滩会议中心里公开发表,但很快它就引发了一场年度竞赛——ImageNet挑战赛,该比赛致力于裁决出哪种算法能以最低的错误率识别出数据集中的图像。许多人把这场比赛看作是当今世界正在经历的人工智能热潮的催化剂。
ImageNet挑战赛的获胜者遍布科技界的各个角落
。2010年,该竞赛的第一个获胜者相继去了百度、谷歌和华为担任高级职务。Matthew Zeiler在2013年ImageNet挑战赛获胜的基础上,创立了人工智能初创公司Clarifai,现在该公司已经获得了4000万美元的风险投资。2014年,谷歌与两位牛津大学的研究人员分享了该比赛的冠军头衔。随后,牛津大学的两位研究人员很快就被谷歌高薪聘任,并进入了最近被谷歌收购的DeepMind实验室工作。

图丨李飞飞
李飞飞本人现在是谷歌云首席科学家、斯坦福大学的教授,同时也是该大学人工智能实验室的主任。
那ImageNet究竟是什么呢?
上世纪80年代末,普林斯顿大学心理学家乔治米勒开始了一项名为WordNet的项目,目的是为英语构建一个等级结构。它有点像字典,但单词是依据和其它单词的关系而显示出来而不是字母顺序。例如,在WordNet中,“狗”一词将被嵌套在“犬”中,而“犬”将嵌套在“哺乳动物”中,以此类推。它是一种组织语言的方式,它依赖于机器可读的逻辑,并且积累了超过155,000个索引词。
李飞飞在美国伊利诺伊大学香槟分校的第一份教学工作中,一直在努力解决机器学习中的一个核心问题:过拟合和泛化。当一个算法只能处理接近于它之前所见的数据时,这个模型被认为是对数据的过拟合;在这样的例子中,我们无法理解任何更普遍的东西。另一方面,如果一个模型没有在数据之间找到正确的模式,那么它就会过度泛化。
李飞飞说,找到完美的算法似乎很遥远。她发现以前的数据集并不能捕捉和体现世界的变化——即使只是识别猫的照片也是无限复杂的。但是通过给算法更多的例子来说明这个世界是多么的复杂,就能让它在数学层次上更行得通。比方说,如果你只看到5张猫的照片,你的大脑就只会有5个关于猫的视角角度和光照条件的概念,这就可能会导致你的大脑会把很多东西认为是猫。但如果你看过500张猫的照片,你的大脑就会有更多的例子来说明猫的共性,这就把对猫的概念“缩小”了。
就在那时,李飞飞开始阅读文献,看看其他人是如何试图用数据来对世界进行一个公正的描述。在那次搜寻中,她找到了
WordNet
。
在阅读了WordNet的方法后,李在2006年访问普林斯顿大学时,与Christiane Fellbaum教授进行了接触,他是一位对WordNet进行持续研究工作的有影响力的人物。 Fellbaum认为,WordNet可以有一个与每一个词相关的图像,这些图像是作为与单词相关联的参考的,而不是另外开辟的计算机视觉数据集。在那次会晤后,李飞飞设想了一个比WordNet更加庞大的数据集——在这个数据集里,每个单词都有很多与之相关的实例图像。
几个月后,李飞飞回到了她的母校普林斯顿大学,并于2007年初开始了“ImageNet”项目。随后,她开始组建一个团队来共同研究这一项目挑战。首先她聘请了一位教授,李凯,后来李凯说服了博士生李佳也进入了李飞飞的实验室。李佳在2017年帮助完成了“ImageNet”项目。现在也是业界大牛。
李佳说:“我很清楚,这与当时的人们所做的事情有很大的不同,当时我们的注意力都集中在另外一点上。我很清楚,这将改变人工智能在视觉研究领域的规则,但我不知道它将如何改变。”
数据集里的物体对象包括了从具体的物体,如熊猫或教堂,到如爱情等的抽象概念。
李飞飞首先以每小时10美元的价格雇佣大学本科生,手工找到图像,并将其添加到数据集中。但是,粗略地计算后,李飞飞很快就意识到,以本科生收集图片的这个速度,要花上90年的时间才能完成收集工作。
在解散那些本科生劳动力后,李飞飞和他的团队重新回到了黑板上讨论这个问题的解决方案。他们想,如果计算机视觉算法能够从互联网上筛选图片,然后人类就只需要把这些图像整理一番,那会怎么样呢?但是,在对算法进行了几个月的修改之后,研究小组得出结论,这种方法也是不可持续的——算法将随着时间的推移而被限制,只能在数据集被编译时才能知道哪些算法具有识别能力。
手工添加是耗时的,算法是有缺陷的,团队又没有钱。李飞飞说那时她的项目未能得到任何联邦拨款申请。并且有人嘲讽她道,这个项目很令人遗憾,让她交给普林斯顿大学的其他团队去研究,因为她毕竟是个女性。
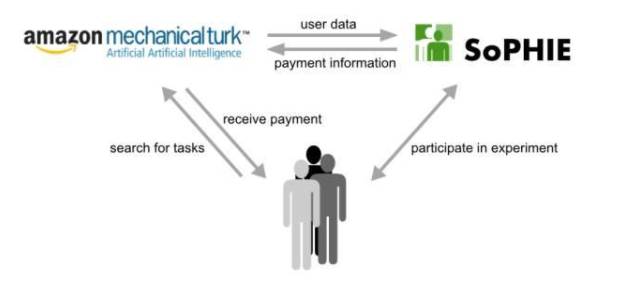
图丨
亚马逊“土耳其机器人(Amazon Mechanical Turk)”项目
最终,一个解决方案终于浮出水面。在她与一名研究生在走廊里的一次闲聊时,她问李是否听说过亚马逊的“
土耳其机器人
(Amazon Mechanical Turk)”项目,这是一个让坐在世界各地计算机面前的人们通过完成平台上的小任务来赚钱的网络平台服务。
“他给我看了这个网站,我可以告诉你,那天我就知道ImageNet项目将会如何进行下去,”李飞飞激动地说。“突然间,我们找到了一个可以扩大数据搜集规模的工具,我们不可能只通过雇佣普林斯顿大学的本科生来实现我们的这个项目的梦想。”
但是,随着李飞飞的两名博士生,李佳和Olga Russakovsky,利用“土耳其机器人”进行的工作越来越多,“土耳其机器人”也暴露出一系列的问题来。例如,每张图像要多少个土耳其机器人鉴定?也许两个人可以确定一只猫,但是一张迷你赫斯基犬的照片可能需要10轮验证。何况万一“土耳其机器人”上的雇员玩弄或者欺骗了系统怎么办?李飞飞的团队最终终止了利用“土耳其机器人”来建立一批统计模型的计划,以确保他们的数据集只包含正确的图像。
即使在找到Mechanical Turk之后,数据集也花了两年半的时间才完成。它包含了320万个被标记的图像,分为5247个类别,分为12个子树,如哺乳动物、汽车和家具。
2009年,李飞飞和她的团队发布了带有数据集的ImageNet论文,当时他们几乎没有对它做任何宣传。李飞飞回忆说,在那次的计算机视觉研究领域的顶级会议CVPR上,只允许团队用一个海报来演示研究成果,而不能口头演示,因此她们的团队给公众分发了带有ImageNet标签的笔来吸引他人的兴趣。但是当时人们还是怀疑仅通过给算法提供更多的数据,就能产生更好的结果的基本思想。
李佳说,总是有人问我们,如果你连一个物体都识别不好,你怎么能识别出成千上万的物体呢?
现在来看,数据正成为新的“石油”,但是在2009年,它仍然是恐龙化石。
ImageNet挑战赛的辉煌
在2009年晚些时候,在京都召开的计算机视觉会议上,一位名叫Alex Berg的研究人员向李飞飞提出建议,要在ImageNet挑战赛中加入一个额外的要求,在这个比赛中,算法还需要定位图像对象的位置,而不仅仅是它的存在。随后,李飞飞对他说:和我一起工作吧。
李飞飞、Berg和李佳在数据集的基础上共同撰写了五篇论文,探讨了算法如何解释如此庞大的数据。
第一篇论文成为了算法如何对成千上万的图像类别进行反应的基准,这也是ImageNet比赛规则的前身
。
李飞飞在第一篇论文中说:“我们意识到,要实现这一想法,我们需要进一步做更深入的工作。”这也就产生了ImageNet挑战赛。
随后,李飞飞联系了欧洲著名的图像识别竞赛组委会,PASCAL VOC。她随后与该组委会达成合作。PASCAL挑战赛是一个备受尊敬的竞赛,其数据集同样具有一定的影响力,但它代表了之前的那些研究方法。与ImageNet数据集的1000个类相比,它只有20个类。

随ImageNet挑战赛在2011年和2012年持续举办,
它很快成为了评判解决当时最复杂的视觉数据集的良好图像识别算法的基准
。
不过,研究人员也开始注意到,除了比赛,他们的算法在使用ImageNet数据集进行训练时,效果更好。
“令人惊喜的是,那些在ImageNet上训练自己的模型的人可以用它们来启动其他识别任务的模型。你可以从ImageNet模型开始,然后对另一项任务进行微调,”Berg说。“这对于神经网络和一般来说都是一个突破。”
在距第一次ImageNet挑战赛两年后的2012年,该赛事产生了重大的成果。事实上,如果我们今天看到的人工智能热潮可以归因于一个单一事件的话,那就是2012年的ImageNet挑战赛的结果。
来自多伦多大学的Geoffrey Hinton、Ilya Sutskever和Alex Krizhevsky提交了一种称为“AlexNet"的深度卷积神经网络体系结构,这一体系结构在今天的研究中仍被使用,这一体系结构的领先优势达到了10.8%,比下一个最好的体系结构要高41%。说明一下,现在Hinton已经被业界尊为大神了。
对于Hinton和他的两个学生来说,
ImageNet的出现真是再及时不过了!
自20世纪80年代以来,Hinton一直致力于研究人工神经网络。但他不像和他同样研究神经网络的另一位人工智能大神Yann LeCun 一样,借助在贝尔实验室的影响,把这项技术广泛应用到ATM机中。
那时,
Hinton运气欠佳,他的研究成果并没能很好地落地。虽然几年前,显卡制造商Nvidia的芯片能使这种早期神经网络的处理速度更快,但其速度仍不如其他技术。
Hinton和他的团队先前已经证明,他们的卷积神经网络可以在更小的数据集上完成更小的任务,比如笔迹检测,但他们需要更多的数据才能在现实世界中发挥作用。直到他们遇到了ImageNet。
Sutskever说:“
很明显,如果你在ImageNet上做得很好,你就可以解决其他图像识别问题
。”
如今,这些卷积神经网络的应用到处都是。在facebook,Yann LeCun是人工智能研究的主管,他用它们来标记人们的照片;自动驾驶汽车用它们来检测物体;基本上任何要识别图像或视频中的东西的功能都在使用它们。他们可以通过在抽象层上发现像素之间的模式,在每个层次上使用成千上万个微小的计算来分辨出图像中的内容。新的图像通过这个过程来匹配它们的模式并且把这个模式学习下来。几十年来,Hinton一直在敦促他的同事们认真检查证实他的这项研究成果,但现在他有证据表明,他的这项成果足可以击败其他的人工智能技术。
“更令人惊讶的是,人们可以通过深度学习来改善它,”Sutskever说,他指的是一种层次神经网络,允许更复杂的模式被处理,现在是人工智能最受欢迎的方式。“深度学习就是正确的东西。”
2012年ImageNet挑战赛的结果让计算机视觉研究人员争相复制这一业界辉煌。Matthew Zeiler是纽约大学的博士生,他曾在Hinton门下做研究,知道ImageNet的结果后,通过在多伦多大学的关系,他获得了这种卷积神经网络早期的论文和代码。他开始与纽约大学的教授Rob Fergus合作,此人也在神经网络上颇有成就。两人开始对2013年的挑战赛进行论文提交,Zeiler也最终在几周后离开了谷歌的实习,以专注于论文提交。









