什么是Swan
▼

一句话介绍Swan——针对Long Running类型的Docker,实现Mesos调度框架及周边。
概述三个要点:
为什么不用Marathon
▼

Swan和Marathon类似,但是为什么不用Marathon?之前用了两年Marathon,有以下几点感受:
Swan具体功能
▼

应用调度是最重要的一部分,Mesos只管资源调度,不做应用调度,应用调度由Mesos上层的Framework做。应用调度重点参考了Marathon的概念,特别指出,如果之前应用是部署在Marathon上,那么任务可以无缝迁移到Swan上。Application Spec基本是一样的,除了极小部分如Health Check,Marathon的Health Check实际上支持数组形式,Swan用的是Mesos Native Health Check,所以这个地方略有不同。

Swan的功能:
应用发布、应用扩缩、版本升级、版本回滚这些重中之重的功能都完美支持。把Swan集成到产品对应的一些功能,比如基于CPU、访问量做的自动扩缩,或一些定时扩缩。客户的新版本可以添加进来,自动通过打包CI/CD机制放在调度里自动触发版本升级。版本回滚不再赘述,如出现问题可及时回滚。
Swan的健康检查和Marathon的健康检查基准不同,Marathon是自己做的健康检查,因当时Mesos的健康检查还未出现,之前看过一篇文章说Marathon的健康检查是在Master节点上,在可扩展的方向存在一些问题。
健康检查的三个特点:
调度策略:
在调度任务时,希望有一些倾向性,如想把对磁盘要求比较高的调度到SSD硬盘上,或是把一些应用调度到CPU比较好的机器上,这部分需要比较灵活的调度策略。Marathon的做法是字符串比对,但不够智能。所以把这部分的策略重写了一下,支持了几个关键字,如AND、OR、UNIQUE、LIKE等可以自由组合,这个功能尚有优化的空间。
容错策略:
做一个Framework很简单,但想将一整套都做好,如应用的生命周期、容错、健康策略、高可用都合在一起非常麻烦。做数据中心,个人理解的调度器是数据中心类似于单机的init system。比如Systemd护着Upstart的一个工具,Systemd和Upstart其实做了很多容错,比如说Crash,做了很多容错机制。怎么处理与记录,在数据中心级别调度上同样有问题,此时容错的策略比较关键,选择什么样的策略重启错误应用,什么样的错误信号是真正的错误,什么样的错误能够记录下来,记录的历史多久,怎样重写等都需要考虑进来。
Swan现在的做法,允许客户指定一些错误标准,重试次数、错误记录的长度、以及最终出错了之后的行为。
用Marathon的都知道,它只负责调度,下一步服务发现的机制以及对外客户应用,对外服务这部分不涉及。它还提供了比较标准的接口,选择第三方的组件或代理功能能拿出来。常用的Bamboo+HAProxy,Marathon LB或者其他HA的方案,又或是Nginx的扩展均可。

起初选择一些方案进行尝试,发现了一些问题,也各有优缺点。比较麻烦的一点是:为了做服务代理和负载均衡以及服务发现往往要引入其他部分的组件。
这些组件要运维和监控,所以把调度以及HTTP代理以及负载均衡、服务发现都放在一个产品里,能节省很多维护成本。于是做了一套HTTP代理和负载均衡,相当于离客户应用最近的一层上又做了一层代理。目前做了HTTP反向代理,更高级的协议正在准备当中。
进入了HTTP代理和负载均衡这一层,可以做更多有意思的事,以前用HAProxy和Nginx作反向代理,都有一些问题,它自成体系,而且在HA和Nginx出现之前,服务发现并不好做,以前的服务发现基本上固定好IP和端口,服务就在上面。现在因为频繁的变化HA和Nginx的配置已不再适用。

在该层做了一些基于权重的流量控制,它和Nginx的Weight略有区别,更能灵活地控制。如把一个流量导到某一个实例上,或者增大某一个实例的流量,都可以做到。

对一些流量做更精准的统计,这种统计更偏向于客户的业务,在使用Marathon+Mesos服务时,经常会引入一些DNS的服务。DNS的好处是真正把服务发现的机制标准化,比如说Nginx在之前不知道Mesos的存在,只知道SRV实例的存在。把DNS引入到框架的原因主要是减少服务数量、减少维护成本,DNS记录的格式能让我们对业务更好的理解。
调度事件和Marathon基本类似,除了格式不同,同样用SSE方式。好处是可以把一些应用基本的事件或者实例的事件,健康检查事件放出来,更好的和其他组件相结合。

灰度发布的功能,之前讲了流量可以在实例级别做流量的控制,如此灰度发布就可以做了。流程是先把流量减下来再把服务断掉,当有版本发布时通过流量和控制重启的范围来达到灰度发布。系统要求高可用,这一点可以通过Mesos和Marathon实现,Marathon可以配多个节点,基于Zookeeper做一些数据同步,Swan这个点和Marathon类似。第一步用Zookeeper,这时起三个节点,比如A节点能够对外服务,当A节点出现问题时,Zookeeper可以帮助选出另外一个节点,服务也就可以切到另外一个上面去。所有的存储,包括源数据都放在Zookeeper里。
通过这种策略,单点的故障不会影响到整个服务。高可用的策略,最开始Swan是有两个版本迭代的。第一个版本用Raft协议,通过Log replication达到高可用但自行维护一套Raft还是略显复杂的,出BUG的点比较多,索性就把这个包丢给Zookeeper了。
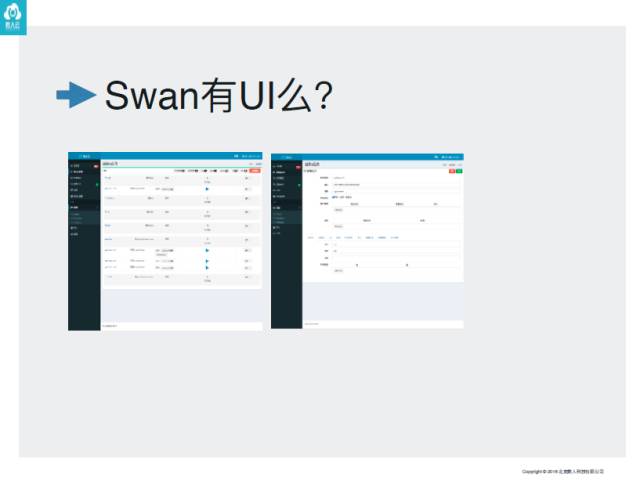
Marathon的UI做的非常漂亮以及直观,迭代过很多版,个人觉得越来越好用,但也有一些问题:只针对Marathon相关。如果客户在使用时发现又要引入一个Marathon解决别的事情,比如部一个Harbor,监控需要去别的地方看,这样很麻烦。
所以Swan自己搞了一套UI,集成了很多功能。相当于把一些与容器化周边的功能:调度功能、镜像管控功能、日志功能等,整套的分享给大家。
未来
▼

UI会继续做下去,上面提到HTTP代理,功能虽有,但仍有许多问题:负载能力、支持协议的多样性如HTTPS的支持、公钥私钥管理这些都将逐步加上来。










