原创:
读芯术
众所周知,神经网络擅长于解决一个特定的任务,但却不擅长解决多个任务。这与人脑不同——人脑能够在完全不同的任务中使用相同的概念。例如,下图展示了一个分形图像:
看过分形图像后,你就能够处理与之相关的多个任务:
· 在一组图像中,将分形图像与猫区分开来。
· 在一张纸上,粗略地画出分形的形状(虽不会完美,但也不会是信手涂鸦)。
· 对分形图像与非分形图像进行分类(你能够自动地对图像从最相似到最不相似进行排序)。
· 闭上眼睛,想象分形的样子(即使没有视觉输入,即使仅看过一眼,你仍可以想象到分形的样子。
你是如何完成所有这些任务的?你的大脑中有专门执行所有这些任务的神经网络吗?
现代神经科学给出的答案是:你大脑中的信息是通过不同的部分共享和交流的。虽然这是个复杂的研究领域,但是我们可以找到一些线索来说明这种多任务性能是如何发生的。答案就在于神经网络中数据的存储方式和解释。

奇妙的表示世界
顾名思义,表示是指信息在网络中是如何编码的。当向一个经过训练的神经网络里输入一个单词、一个句子或一张图像(或其他任何东西)时,它会在连续的层上被转换,因为权重乘以输入并使用了激活函数。最后,在输出层中,我们得到数字,我们可以将其解释为类标签、股票价格或者网络被训练用于的任何其他任务。
这种输入输出的神奇转换是由于连续层中的输入转换而发生的。这些输入数据的转换称为表示。一个关键的概念是,每一层都使下一层很容易完成它的工作。简化连续层阶段的过程会使激活变得有意义(在特定层转换输入数据)。
“有意义
”
是什么意思?让我们来看一个激活图像分类器不同层的示例。

图像分类网络所做的就是将像素空间中的图像转换为越来越高层次的概念空间。因此,以RGB值表示的汽车图像开始时在第一层被表示在边缘空间,然后在第二层是在圆形和形状空间,在最后一层之前,它将开始在车轮、车门等高级对象中进行表示。
这种日益丰富的表示(由于深层网络的层次性而自动出现)使得图像分类的任务变得平常。最后一层所要做的就是权衡车轮和车门的概念,使其更像汽车;权衡耳朵和眼睛,使其更像人。
如何处理表示?
因为这些中间层会存储有意义的输入数据的编码,所以我们可以为多个任务使用相同的信息。例如,你可以采用一个语言模型(一个为预测下一个单词而训练的循环神经网络)并解释特定神经元的激活来预测句子的感情。
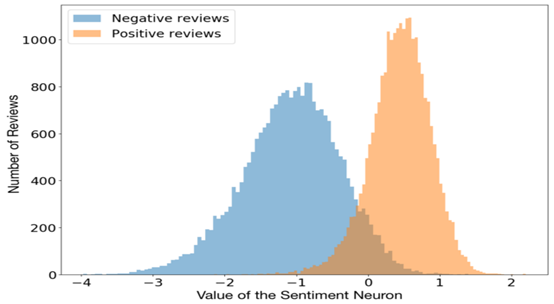
图片来源:Unsupervised Sentiment Neuron
令人惊讶的是,情感神经元在语言建模的无监督任务中自然产生。网络被训练来预测下一项工作,我们在任务中没有要求网络预测情绪。也许情感是一个非常有用的概念,网络产生它是为了更好地进行语言建模。
一旦你了解了表示的概念,你将开始在一个完全不同的角度看深层神经网络。你会感觉到表示是一种可转换的语言,这使得不同的网络(或同一网络的不同部分)可以相互交流。
通过构建四合一网络来探索表示
为了充分理解表示是什么,让我们构建自己的深层神经网络,其功能有以下四种:
· 图像字幕生成器:给定图像,为其生成字幕。
· 相似词生成器:给定一个词,查找与之相似的其他词。
· 视觉相似的图像搜索:给定图像,查找与其最相似的图像。
· 通过描述图像内容进行搜索:根据文本描述搜索包含内容的图像。
每个任务本身就是一个项目,传统上需要好几个模型。但我们将使用一个模型来完成所有这些工作。
代码将用Pytorch写在JupyterNotebook上。
Github存储库:https://github.com/paraschopra/one-network-many-uses
第一部分-图像字幕
网络上有很多很好的教程来讲解如何制作图像字幕,所以本文不打算深入探讨。
模型
图像字幕一般有两个组成部分:a)一个图像编码器,它接收输入图像并以对字幕有意义的格式表示;b)一个字幕解码器,它接收图像表示并输出图像的文本描述。
图像编码器是一种深度卷积网络,字幕解码器是一种传统的LSTM/GRU循环神经网络。当然,我们可以从头开始训练编码器和解码器。但是这样做需要的数据非常多,而且需要大量的训练时间。因此,我们将采用一个预先存在的图像分类器,并使用它最后一层的前一层的激活,而不是从头开始训练图像编码器。
这是你将在本文众多神奇的表示示例中看到的首个表示。我们将使用Pytorch modelzoo中提供的初始网络,它在ImageNet上接受过训练,可以对100个类别的图像进行分类,能为我们提供一个可以输入到循环神经网络中的表示。

图片来源:https://daniel.lasiman.com/post/image-captioning/
请注意,初始网络从未接受过图像字幕任务的训练。然而,它是有效的!
完整的模型体系结构如下所示:
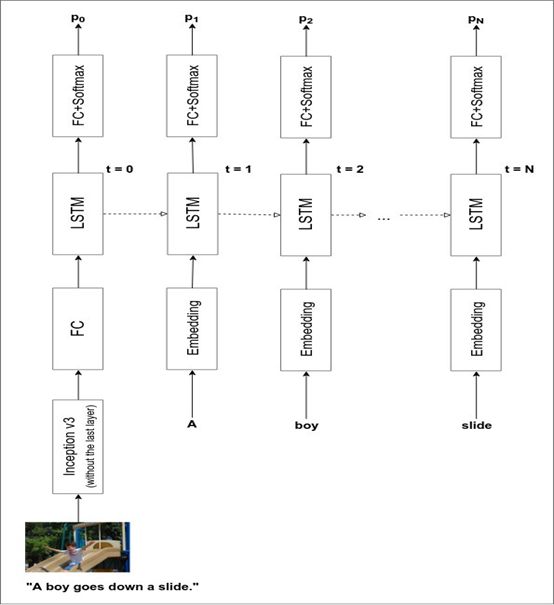
图片来源:https://daniel.lasiman.com/post/image-captioning/
你可以从头开始训练这个模型,但在CPU上需要几天时间。
性能
我们已经实现了定向搜索方法,它有很好的性能。以下是网络为测试集(以前从未见过)中的图像生成字幕的示例。
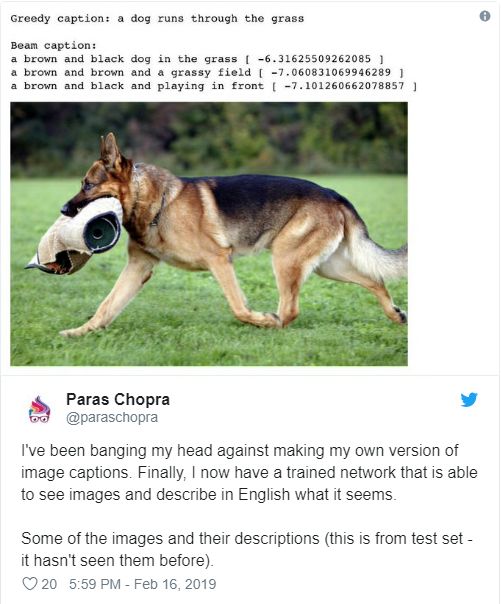
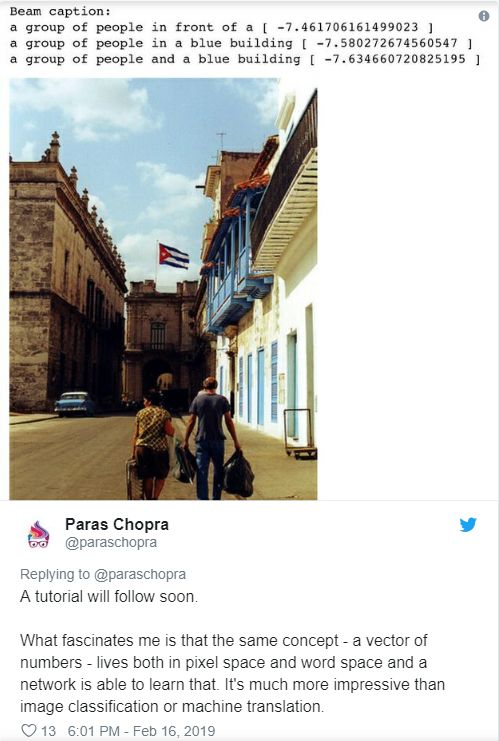
让我们看看下面照片中的网络字幕:

不错!令人印象深刻的是,网络知道图片中有一个穿着白色T恤的男人。语法有点不对劲(不过更多的训练可以解决),但基本要点还不错。
如果输入图像中包含了网络以前从未见过的内容,那么它往往会失败。例如,网络会给iPhoneX的图像贴上什么标签呢?
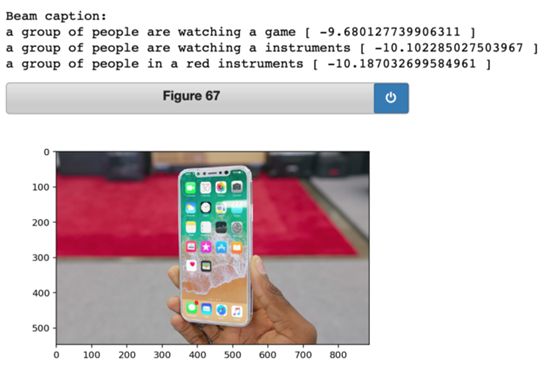
它做得不太好。但总的来说,对性能还算满意,在学习图像字幕时,为我们利用网络提供的表示构建其他功能提供了良好的基础。
第二部分-相似词语
回想一下我们如何从图像表示中解码字幕。我们将表示输入LSTM/GRU网络,生成一个输出,将其解释为第一个单词,然后获取第一个单词并将其反馈到网络中以生成第二个单词。这将一直持续,直到网络生成一个表示句子结尾的特殊标记。
为了将单词反馈到网络中,我们需要将单词转换为表示形式,从而成为网络的输入。这意味着,如果输入层由300个神经元组成,那么对于所有标题的8000多个每个不同单词,我们需要有一个100个唯一指定该单词的相关数字。将单词字典转换成数字表示的过程称为单词嵌入(或单词表示)。
我们可以下载和使用诸如word2vec或GLoVE之类的预先存在的单词嵌入。但在本例中,我们从零开始学习如何嵌入一个单词。从随机生成的单词嵌入开始,探索在训练完成之前我们的网络对单词的了解。
因为无法想象100维的数字空间,所以我们将使用一种称为t-SNE的奇妙技术来可视化二维中所学的单词嵌入。t-SNE是一种降维技术,它试图使高维空间中的邻域也在低维空间中保持邻域。
单词嵌入的可视化
让我们看看标题解码器学习到的单词嵌入空间(与其他语言任务不同,这里有数百万个单词和句子,我们的解码器在训练数据集中只看到大约30K个句子)。
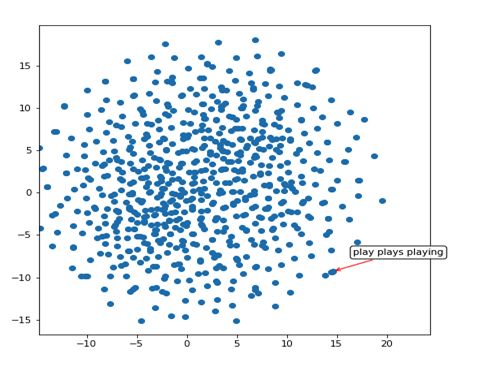
因此,我们的网络已经学习到类似于“play”、“plays”和“playing”的词非常相似(它们具有类似的表示,从带有红色箭头指出的紧簇中可以明显看出)。让我们来探索这个二维空间中的另一个区域:
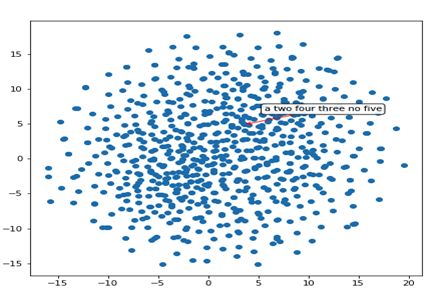
这个地区似乎有成簇的数字-'2'、'3'、'4'、'5'等。另一个地区:
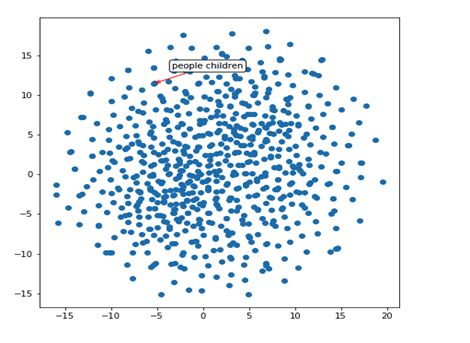
它知道人和孩子很相似,而且还隐式地推断了物体的形状。

相似词
我们可以使用100维表示来构建一个函数,该函数表示与输入词最相似的词。它的工作原理很简单:取100维表示,并找出它与数据库中所有其他单词的余弦相似性。
让我们看看与“boy”这个词最相似的词:

不错。“Rider”是一个例外,但“kids”、“kid”和“toddler”都是不错的选择。网络认为什么与“chasing”这个词类似:
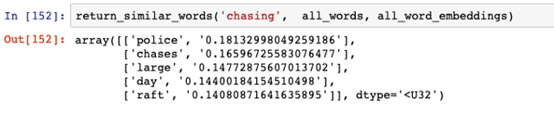
“Chases”很好,但我们不知道为什么它认为“police”和“chasing”相似。
词语类比
关于单词嵌入的一个令人兴奋的事实是你可以对他们进行计算。你可以用两个词(如“king”和“queen”)减去它们的表示,得到一个方向。当你将这个方向应用于另一个词的表示(比如“man”)时,你会得到一个接近于实际的类似词的表示(比如“woman”)。这就是Word2vec在推出时如此出名的原因:

图片来源:https://www.tensorflow.org/images/linearrelationships.png
字幕解码器所学的表示是否具有类似的特性呢?我们可以尝试一下。
网络学习的类比并不完美(有些单词字面上出现的次数少于10次,所以网络没有足够的信息来学习)。
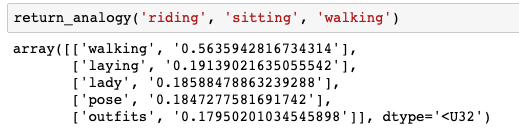
如果骑行对应着坐,走路对应的是什么?我们的网络认为可能是“laying”(这还不错!)。
同样,如果“man”的复数是“们”,那么“woman”的复数是什么?
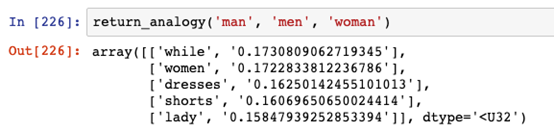
第二个结果是“women”,这是相当正确的。
最后,如果草是绿色的,天空会是什么颜色:

网络认为它是银色或灰色的,没有蓝色,但两者都是颜色。令人惊讶的是,网络能够推断出颜色的方向。
第三部分-相似图像
如果单词表示将相似的单词聚集在一起,那么图像表示(即初始的图像编码器输出)又如何呢?我们将同样的t-SNE技术应用于图像表示(在字幕解码器的第一步中作为输入的300维张量)。
可视化
这些点代表不同的图像(我们没有取整个8K图像集,但它是大约100个图像的样本)。红色箭头指向附近的一组表示。
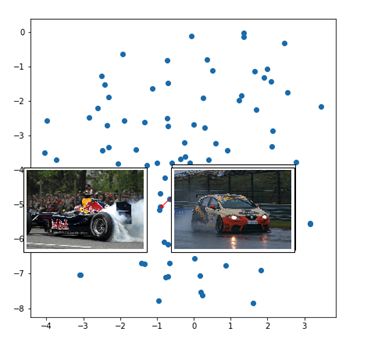
所以赛车聚集在一起。
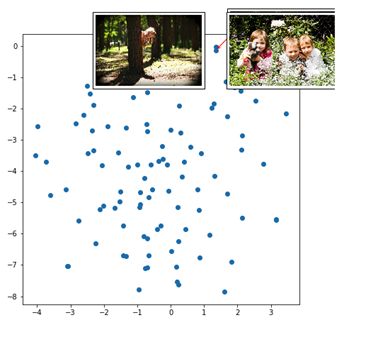
孩子们也在森林、草地上玩耍。
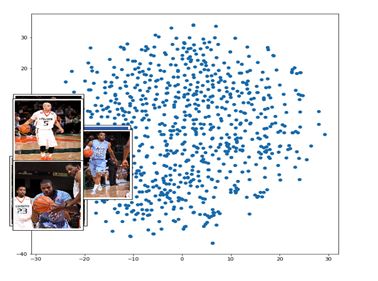
篮球运动员聚集在一起。
查找与输入图像相似的图像
对于类似的单词任务,我们被限制在测试集词汇表中查找类似的单词(如果测试集中没有某个单词,则字幕解码器将无法学习其嵌入)。但是,对于类似的图像任务,我们有一个图像表示生成器,它将获取任何输入图像并生成其编码。
这意味着我们可以使用余弦相似法来构建按图像搜索功能,如下所示:
· 步骤1:获取数据库或目标文件夹中的所有图像并存储其表示(由图像编码器给出)。
· 步骤2:当用户想要搜索与他已经拥有的图像最相似的图像时,获取新图像的表示并在数据库中查找最近的图像(由余弦相似性给出)。
Google Images很可能使用这种(或非常类似的)方法来增强他们的反向图像搜索功能。
让我们看看我们的网络是如何运作的。
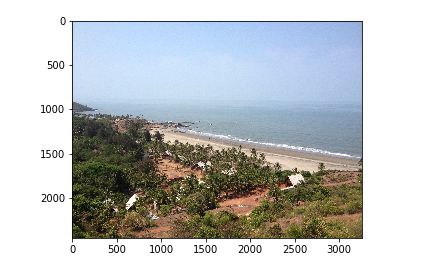
请注意,我们使用的模型以前从未见过这张图。当我们查询类似的图像时,网络从FlickR8K数据集输出以下图像:

是不是大开眼界?深度神经网络绝对很靠谱!
第四部分-通过描述来搜索图像









