
我们经常有这样的经历:花了很长时间编写和调试一个特定功能的函数,却发现Python已经有类似的内置函数。我们常常在重复造轮子。Python包含了许多强大的内置函数,使用这些函数来简化代码可以为我们节省宝贵的时间。
接下来,我们将介绍一些我们经常忽略的强大Python内置函数。
ZIP_Longest
合并不同大小的可迭代对象。Python中的
zip_longest()
函数来自
itertools
模块,允许你将多个长度不同的可迭代对象进行合并。与
zip()
不同,后者会在最短的可迭代对象处停止,
zip_longest()
会一直合并,直到最长的可迭代对象耗尽,缺失的值会用指定的
fillvalue
填充(默认为
None
)。
zip_longest()
函数可以用于:
-
合并来自多个来源的数据,尤其是长度不均匀的数据。
-
比较没有直接关联的数据点。
-
处理不等维度的矩阵或网格。
from itertools import zip_longest
list1 = [1, 2, 3]list2 = ['a', 'b']list3 = ['X', 'Y', 'Z', 'W']
result = list(zip_longest(list1, list2, list3))print(result)
result = list(zip_longest(list1, list2, list3, fillvalue='-'))print(result)

Divmod
divmod(a, b)
函数返回一个包含商和余数的元组,当将
a
除以
b
时。它是
a // b
(商)和
a % b
(余数)的组合形式。
这个函数在需要同时得到商和余数的情况下非常实用。它通过一步操作代替了两个独立的操作(整数除法和取模),从而减少了开销。
divmod()
在以下场景中非常有用:
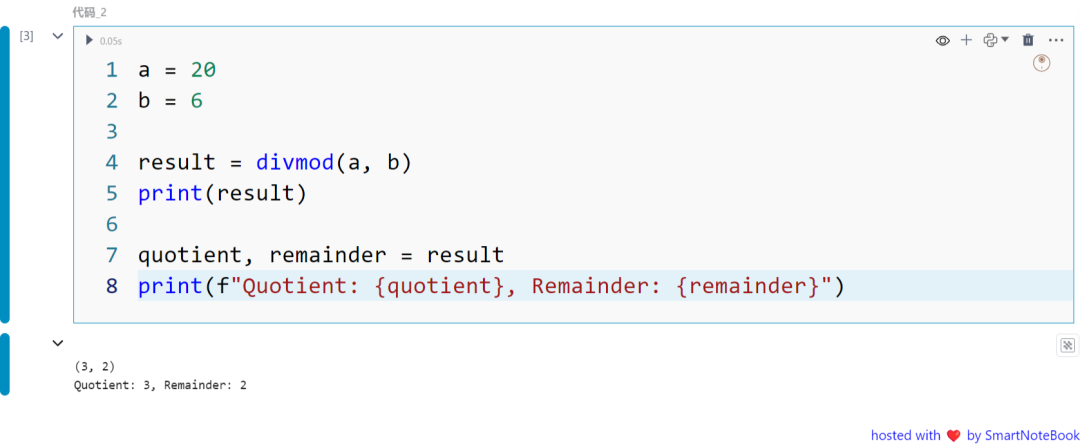
a = 20b = 6
result = divmod(a, b)print(result)
quotient, remainder = resultprint(f"Quotient: {quotient}, Remainder: {remainder}")
Compile
将代码编译为字节码,快速而简洁。Python中的
compile()
函数将源代码编译为可以稍后执行的代码对象。它允许你将一段Python代码字符串转换为代码对象,然后可以将其传递给
exec()
或
eval()
进行执行。
compile()
函数允许你动态执行存储在字符串中的Python代码,这在一些高级用例中非常有用,例如模板引擎、REPL系统或动态生成代码时。
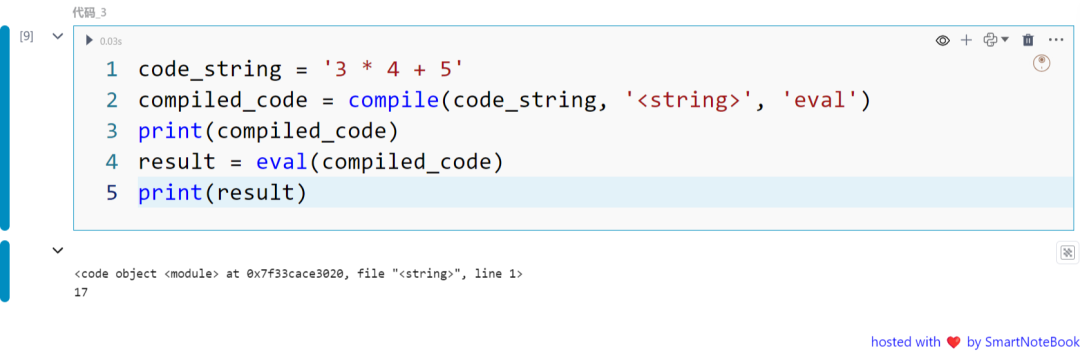
code_string = '3 * 4 + 5'compiled_code = compile(code_string, '', 'eval')print(compiled_code)result = eval(compiled_code)print(result)
Bytearray
创建和修改字节序列。
bytearray()
函数创建一个可变的字节序列,它是字节数据的灵活表示形式。与不可变的
bytes
不同,
bytearray
允许修改,适用于需要操作或更新字节数据的场景。

bytearray
允许修改,适用于需要动态构建或更改字节数据的场景。在处理文件、网络协议或流中的二进制数据时,它非常有用,尤其是在需要频繁修改的情况下。
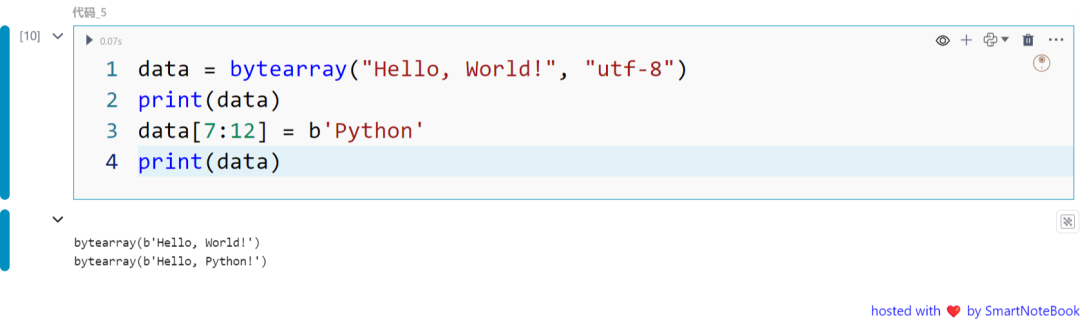
data = bytearray("Hello, World!", "utf-8")print(data) data[7:12] = b'Python'print(data)
Repr
查看对象背后的代码。Python中的
repr()
函数返回对象的字符串表示形式,理想情况下可以使用
eval()
函数重新创建该对象。它提供对象的正式字符串表示,适用于调试和日志记录。
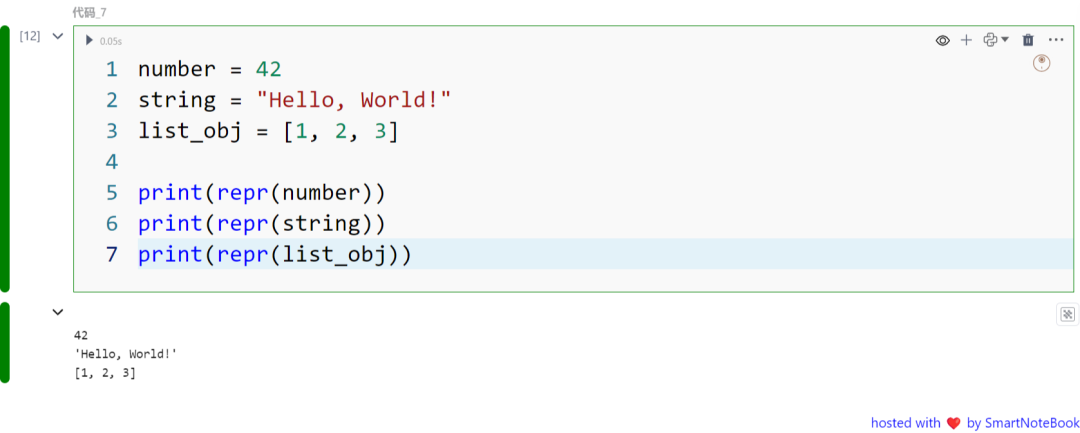
number = 42string = "Hello, World!"list_obj = [1, 2, 3]
print(repr(number))print(repr(string))print(repr(list_obj))
Memoryview
轻松实现直接内存访问。Python中的
memoryview()
函数创建一个内存视图对象,允许你访问支持缓冲区协议的对象的内部数据,而无需复制数据。这在高效处理大数据集时特别有用,因为它允许对数据的切片进行操作。
memoryview()
通过允许直接访问对象的底层内存,避免了复制数据的开销。在科学计算或数据分析中,处理大型数组或缓冲区非常常见,
memoryview()
可以通过减少内存使用大大提升性能。
data = bytearray(b"Hello, World!"










