近些年“猜你喜欢”、“个性化推荐”这类的算法很是流行,无论是新闻界还是电商行业、无论是国内还是国外的产品,多数都会采用这个算法。
本公众号之前也有多篇文章(如
YouTube
等)提到过这个技术,欢迎翻阅~
当你通过智能排序的方式浏览新浪微博时、当你在今日头条上阅读被大数据精选出的新闻时、当你在淘宝上“随便看看”时,都会于不知不觉间接触到这个算法。当然,如果你是网易云音乐的发烧友、如果你是腾讯新闻的忠实读者、如果你是知乎的重度用户,想必也一定会对“猜你喜欢”深有感触。
在基于算法和兴趣的阅读模式中,我们看到的所有信息,其实都是被“精心调整”过的。
计算机算法依据我们鼠标点击过、键盘输入过内容,记录下我们的浏览、搜索、下单和喜好,有选择地推荐一些我们“可能会喜欢”的内容。
这样一来,“喜欢”的内容就会源源不断地出现在我们眼前,算法就像是一个泡泡,把我们与这个世界的另一面隔绝起来。

表面上看,各个产品推崇的“猜你喜欢”,可以根据用户风格个性化地推荐内容,戳中他们的痛点,甚至能因此为商家带来更大的利益。但实际中,“猜你喜欢”真的就是用户喜欢的?这个算法真的有传说中的辣么厉害?以下,我就来说说自己讨厌“猜你喜欢”的6个理由+5个建议。

尴尬!
为何让我想遮掩的“羞羞”往事
大白于天下?
其实“猜你喜欢”推荐的并不是用户真正喜欢的内容,它推荐的只是用户经常浏览的那些事儿。
但...谁没有些个“难以启齿”的小爱好呢
 想必大家都会有这样尴尬的瞬间:
想必大家都会有这样尴尬的瞬间:
老板让你买一些物料,当你在老板面前打开淘宝时,赫然映入眼帘的,是一堆大数据为你推荐的性感女仆装,其实,你只是3天前给女朋友买过一件cosplay衣服而已。
又或者,你曾在刷微博时无意间点开了几张“波涛汹涌”的照片,此后你的微博中就会时不时冒出几条内容类似的推文,如果不小心手滑又点开看了看,那么恭喜你...就像滚雪球似的,你的微博在未来几天会变成“黄色重灾区”。
相信我,此时的你一定不想再跟朋友们一起刷微博了。

“猜你喜欢”不智能
推荐的内容并不是我感兴趣的
网易云音乐的“每日歌曲推荐”算是它的一大亮点。
最初始的时候,网易云音乐会让用户设置喜欢的歌曲类型。但当app被使用了一段时间后,后台就会根据用户平时听歌的类型、红心数量、下载量等元素来推荐的你“喜欢”的歌曲。
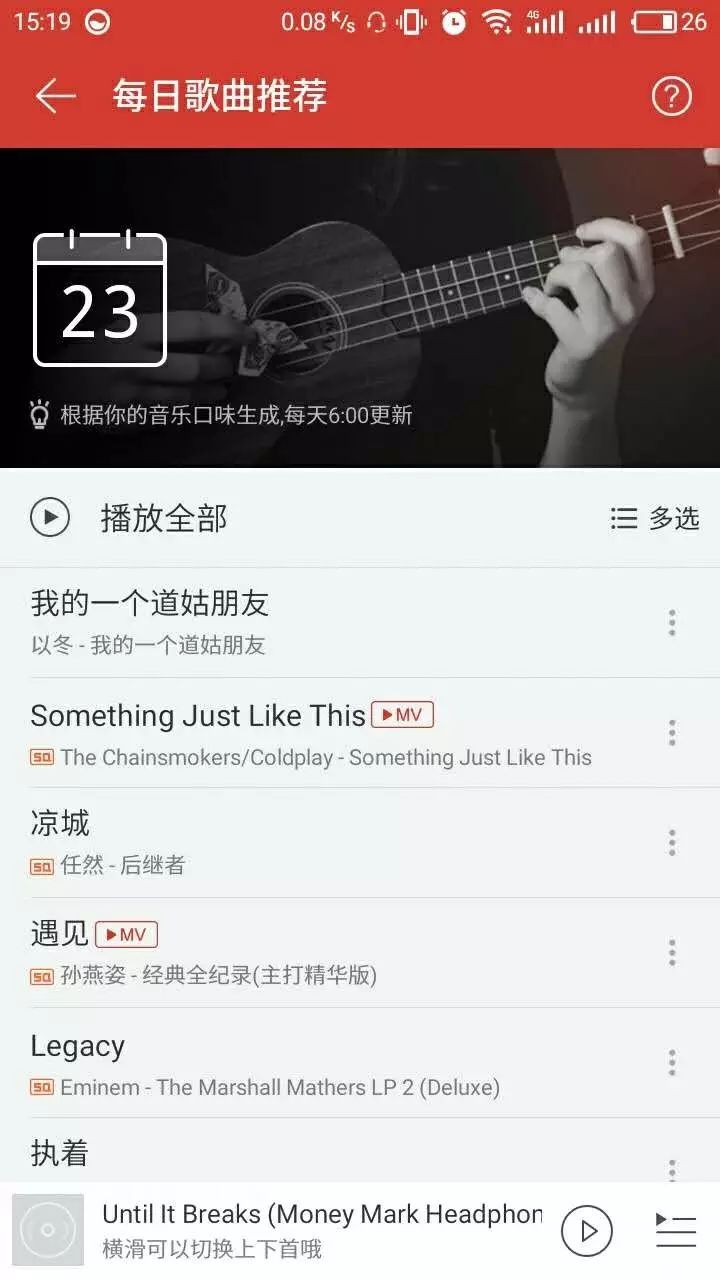
但大多数用户表示,这类推荐其实并不太准确。甚至有时候会
搞错用户喜欢的歌曲风格
,每当这时,那些有强迫症的用户都要花上好久来调教“每日歌曲推荐”

除此以外,微博也会出现此类问题。
比如前段时间某位当红小花旦又在搞事情,我本来不是她的粉丝,但由于微博上本来就有很多关于她的信息
(想不看都躲不开)
,而且我本身也想了解一下事情的具体进展
(八卦)
,就多看了几条相关推文。
没成想,此后我的微博便会不时出现跟这个小花旦有关的内容,一条接一条...不知道的人还以为我是她的忠实粉丝...

被“精选”出的信息包围
我无法做到“兼听则明”
信息流通越成熟,人们就变得越偏执,如果我们不倾听各方面的意见,我们就永远无法正视问题。
今日头条作为一种新型的新闻阅读方式,已经将传统的新浪、腾讯、网易、搜狐这些新闻媒体以一种
大数据+新闻内容
的方式呈现给用户。今日头条在实现个性化推荐上,重点引入了几个机制:
算法排序、人工运营、A/B test+投票机制。
虽然说可以给自己不感兴趣的内容打上标签,但这样做未免有些麻烦,而且有时候用户需要对某
条内容“不感兴趣”好几次,才能真正屏蔽它。
另外,使用过今日头条的用户也可以感受到,它推荐的内容有些少,且都是你经常阅读的那几类,
想看些其他维度的新闻还要靠自己主动搜索
。而且推荐的新闻大多即时性很高,阅后即焚,没有太多的精选文章,
冗杂的信息依旧很多。
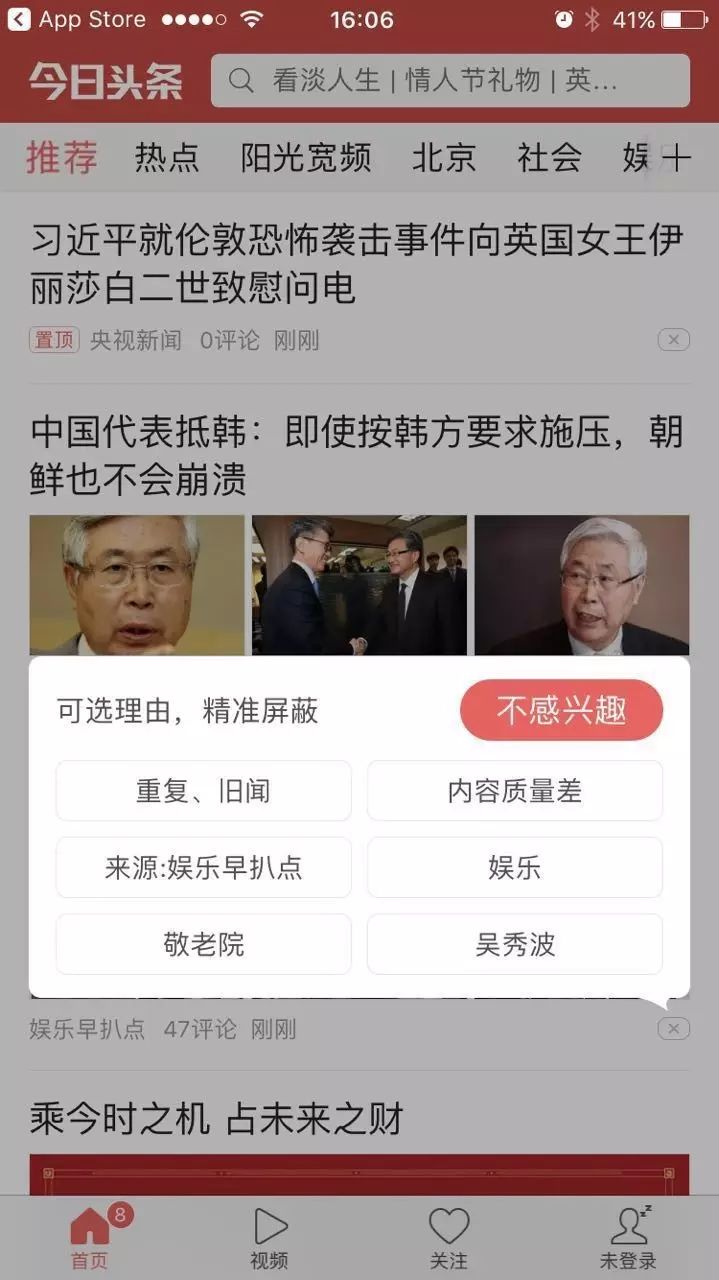
如果用户只接受那些他认同的意见,长此以往他的信息流里就会只剩这些东西了。
经过包装的营销内容泛滥成灾
某种程度上,“猜你喜欢”也变成了商家营销的一种手段。
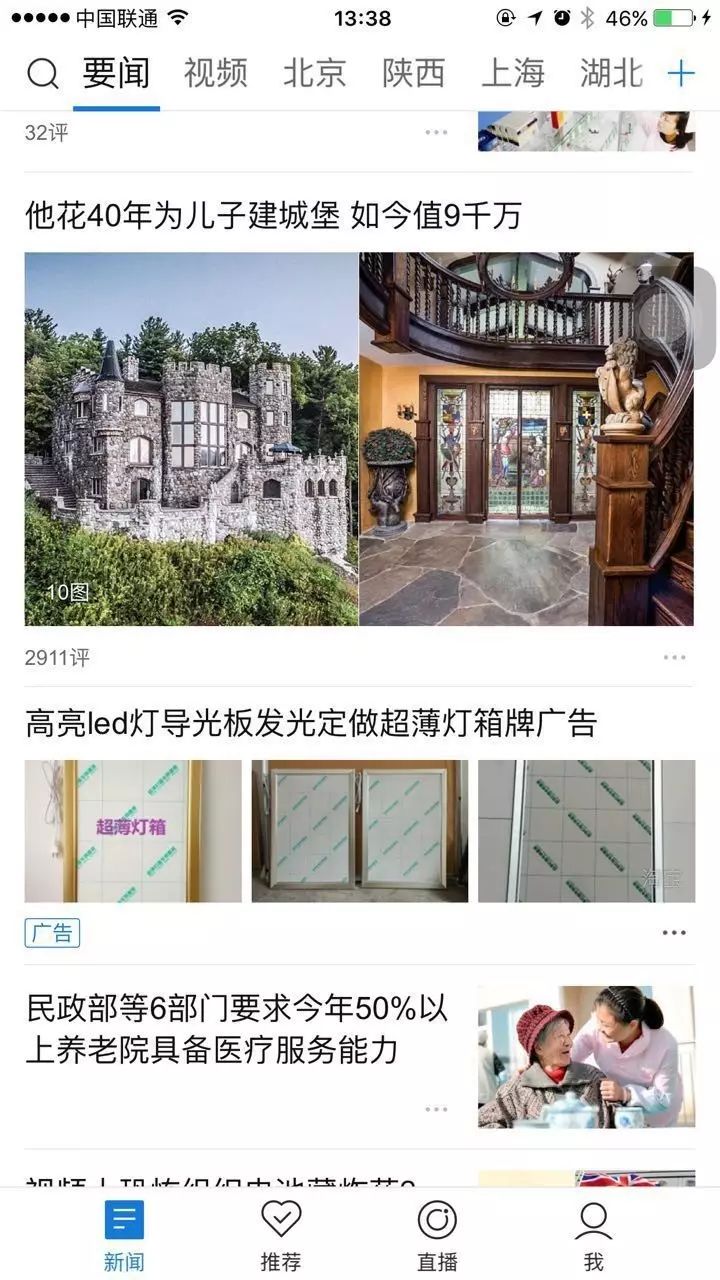
不知从何时起,腾讯新闻似乎与淘宝展开了友好的“交流互动”。上午我刚在淘宝购买了LED广告灯箱,下午竟然在腾讯新闻里看到了这个广告,搞siao
的是,广告还跟某些时政要闻一起被放在了“要闻”版块。
与之类似的还有闲鱼。
如果你在闲鱼上开了提醒,每当你在淘宝上搜过什么东西,闲鱼上就会跳出来一条消息——“这里有你喜欢的xxxxx”。
可是...我跟本不想要二手的避孕套啊喂!!!
差别对待?
我“喜欢”的竟是“最贵的”?
其实,在浏览网站信息时,你的cookie等某些信息都会被某些商家收集起来。他们都会查看和记录这些数据,以此来追踪你消费者买了些什么、曾考虑过、浏览过和决定不买哪些商品。
在 2000 年 9 月,亚马逊曾在这上吃过一次苦头:
有一部分顾客发现他们收到的商品报价更高,因为网站将他们识别为老顾客,而不是匿名进入或是从某个比价网站转接进来的顾客。亚马逊声称这只是一项随机的价格测试,其呈现出来的结果与老顾客身份之间的关联纯属巧合。话虽这样说,但它还是叫停了这项操作。









