
科研经验 | 文献 | 实验 | 工具 | SCI写作 | 国自然

作者:麦子(转载请注:解螺旋·医生科研助手)
统计方法辣么多,怎么知道自己要用哪一个?要是有个导航就好啦~这里就给大家找了两表一图,妈麻再也不用担心我在统计的世界里迷路了~
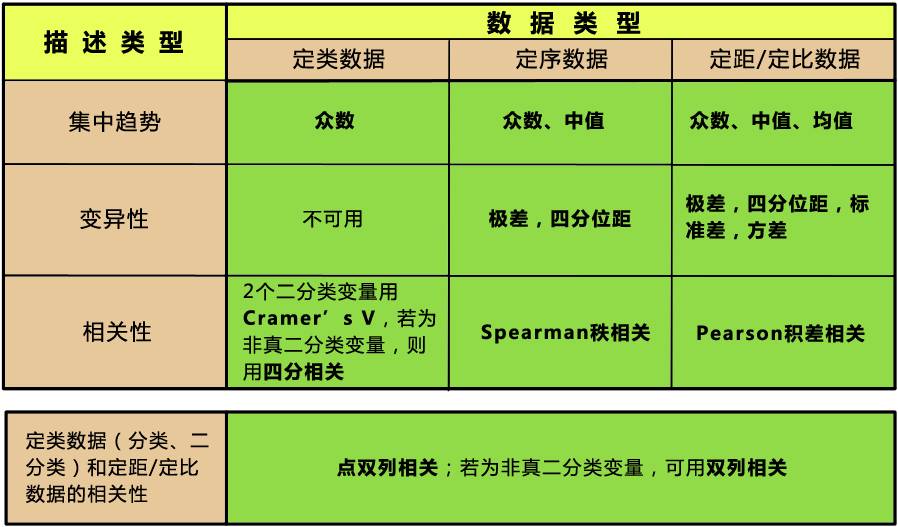
选择统计方法,是从了解自己的数据特征开始的。先要决定做什么类型的分析,是描述还是推论;其次判断数据类型;再次看变量多少,以及各变量的设计特征,就可以做出决策了。
在进入导航之前,咱们先复习一下数据类型。统计学中的数据分为4类:
定类数据(Nominal):最低级数据,表示个体的分类或属性,没有大小次序关系,例如对性别、民族等进行编号。
定序数据(Ordinal):中间级数据,表示个体在某个有序排列中所处的状态,例如按受试者入组时的TNM肿瘤分期(I~IV)分为四个组,编码1~4。
定距数据(Internal):数据具有间距特征,有单位,但没有绝对零点,如体温。
定比数据(Ratio):最高级数据,有单位,也有绝对零点,比如身高。
不过后两者在一般的统计决策选择中区分不大,知道就好了~
(点击看大图)
注:二分类变量是指,只有2个值的变量,例如性别只有男、女(听说Facebook的性别选项有50+个呃~。~);非真二分类变量是指,本来是连续变量,但被人为划分成二分类,比如血压本来是连续值,但可能在特定的实验设计中只划分为高、正常两个分类。
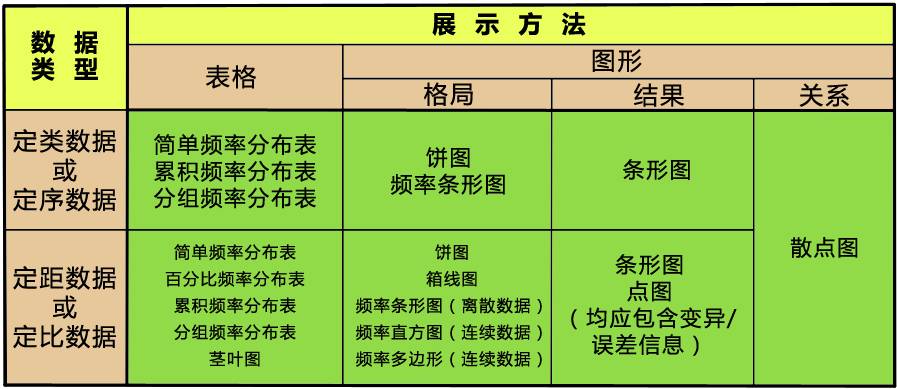
得到了结果,在论文中用什么形式来表现更合适呢?用哪种图、哪种表?
(点击看大图)
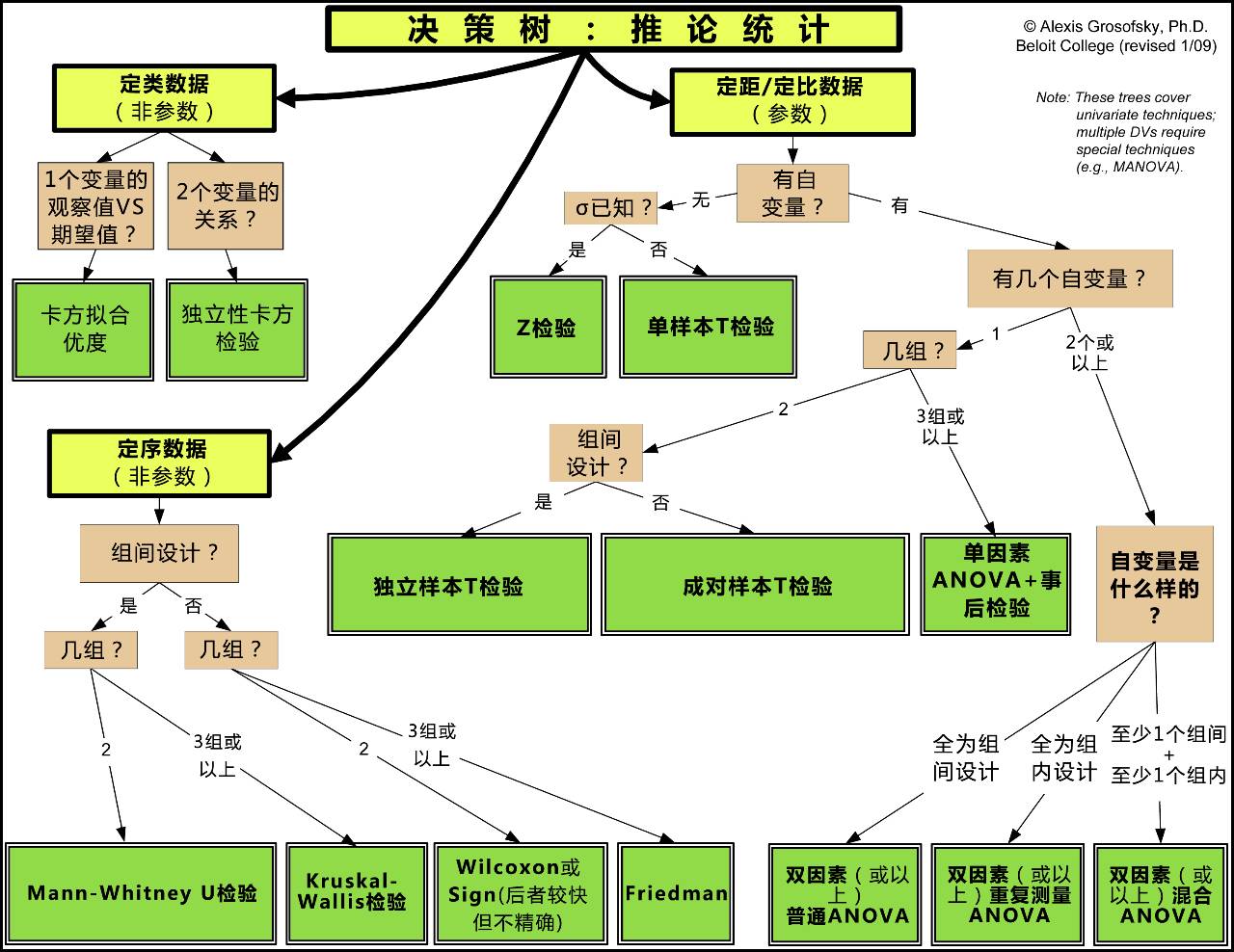
注:原图来自美国心理学会的教学讲义(详见参考资料1),跟据实际应用情况略有调整。(点击看大图)
就解释下图中的组间设计吧,它可以理解为独立样本,即同一个变量下不同水平的数据来自不同个体,与其相对的是组内设计,同一个变量下不同水平的数据来同一个体。
举个例子,治疗措施是一个变量,其下有治疗和未治疗2个水平,如果治疗和未治疗的数据分别来自不同的受试者,就是组间设计(这时我们常常会把两组分别命名为“治疗组”和“对照组”),如果治疗和未治疗的数据来自同一批受试者,就是组内设计(我们常常命名为“治疗前”和“治疗后”)。
最后那些花样繁复的统计学方法名称,已经不用管了,顺着这条路走,就能在各种统计软件的菜单中找到它们了。
参考资料:
1.http://teachpsych.org/resources/Documents/otrp/resources/grosofsky09.pdf
2.Comparing groups for statistical differences: how to choose the right statistical test? | Biochemia Medica










