
作者:哈工大SCIR 聂润泽
1.摘要
现今神经机器翻译系统已取得很好的效果,基于 Transformer 的翻译模型在各种翻译任务中均取得了先进的表现,但如何使用文档级上下文处理语篇现象仍然是一个挑战。现有的机器翻译系统普遍基于独立性和局部性假设,即要么逐词翻译,要么逐短语翻译(由 SMT 完成),或者单独翻译句子(由 NMT 完成)。相反,文本不是由孤立的、无关的元素组成,而是由并置(collocated)且结构化的句子组组成,这些句子由复杂的语言元素绑定在一起,被称为语篇(discourse)。忽略这些语篇元素之间的相互关系,会导致翻译在句子层次上可能是完美的,但缺乏帮助理解文本的关键属性。解决此问题的一种方法是通过在更广泛的语境中使用上下文信息来学习到文本的底层语篇结构。因此,逐句翻译容易忽略语句之间的逻辑性和流畅性,文档级翻译通过引入上下文信息改进这一点。
本文介绍目前在文档级机器翻译领域的主要工作。通过文档级机器翻译,我们的意图是利用句子间上下文信息进一步提升性能,这些信息包括文档的语篇方面或文档中源语句的周围句子。除此之外,我们还将介绍为评估该领域的改进而引入的评估策略。
2.任务
神经翻译时代的篇章级机器翻译致力于在神经网络中引入并利用上下文相关信息,使得神经网络能够捕获到相关信息并在翻译过程中保留语义现象从而使得翻译结果通顺且流畅。我们的目标是使 Transformer 模型能够利用文档级上下文。3.数据集
在 WMT19 和 WNGT19 中有对应篇章级机器翻译的公共任务,领域内也有常用的例如 TED, News 和 Europarl 等篇章级数据集,但整体上数据集较少,且缺乏特定领域的大规模篇章级平行语料。
常用于训练的数据集有(见表一):
表1: 常用数据集
| 数据类型 | 语言 | 数据集 | 句子/文档量 |
|---|
| TED (演讲字幕) | 中文 -> 英语 | IWSLT 2015 | 205K/1.7K |
| 英语 -> 德语 | IWSLT 2017 | 206K/1.7K |
| News (新闻报道) | 英语 -> 德语 | News Commentary v11 | 236K/6.1K |
| 西班牙语 -> 英语 | News Commentary v14 | 355K/9.2K |
| 法语 -> 英语 | News Commentary v14 | 303K/7.8K |
| 俄语 -> 英语 | News Commentary v14 | 226K/6.0K |
| Europarl | 英语 -> 德语 | Europarl v7 | 1.67M/118K |
4.现有方法
4.1 使用额外的上下文编码器
Wang 等[1]提出了第一个上下文相关的基于 RNN 的 NMT 模型,与上下文无关的基于句子的 NMT 模型相比有显着的改进。
之后 Bawden 等[2]使用多编码器 NMT 模型来利用前一个源语句的上下文,从而使用连接,门控或分层注意力机制将来自上下文和当前源语句的信息进行组合。此外,他们引入了一种方法,该方法将多个编码器与先前句子和当前句子的解码结合在一起。他们强调了目标方上下文的重要性,但在使用 BLEU 评价时得分降低。
Voita 等[3]将 Transformer 体系结构中的编码器更改为上下文感知编码器(见图1),该上下文感知编码器具有两组编码器,即源编码器和上下文编码器。他们对英语 → 俄语字幕数据进行的实验以及对上下文信息对代词翻译的影响的分析表明,他们的模型隐式学习了指代消解。他们还尝试使用源语句下文作为上下文,并发现其表现不及使用 Transformer 的基准线。

图1:上下文感知编码器
Zhang 等[4]进一步在 Transformer 中使用上下文感知编码器(见图2),使用基于句子的预训练嵌入作为上下文编码器的输入。在训练的第二阶段,他们只学习文档级参数,而不微调其模型的句子级参数。他们进行了 NIST 中文 → 英语和 IWSLT 法语 → 英语翻译任务的实验,并报告了 BLEU 分数相对于基线的明显提高。

图2:Zhang 等[4]提出的上下文编码器
Ma 等[5]随后提出了一种同样基于 Transformer 单一编码器的篇章级翻译模型(见图3),利用单一编码器捕获上下文信息并考虑了源语句在文本中的位置,在化简模型的同时在英德任务上取得了更好的效果。

图3:基于 Transformer 的单一编码器
4.2 上下文扩展翻译单元
在通过上下文扩展翻译单元的工作中,Rios 等[6]专注于神经机器翻译中的词义消歧(WSD)问题。他们解决此问题的方法之一是将文档中语义相似的单词的词法链作为 NMT 模型的特征输入。尽管这种方法并没有相对于通用测试集的基线产生实质性的改进,但是针对同一工作中引入的目标测试集有一定改进。他们还发现了证据,没有文档级的上下文,即使是人类,也无法消除他们所使用的目标测试集中的某些歧义。
4.3 使用 Document-level Token
Maće 和 Servan [7]通过在源句子的开头添加文档标签作为附加标记,并在训练模型时使用文档级嵌入。文档级嵌入是训练句子级模型时学习到的词嵌入的平均值。此外,在训练文档级模型以保持词嵌入与文档级嵌入之间的关系时,固定词嵌入。在编码器输入的这种微小变化对于英语-法语语言对的两个翻译方向都产生了好的结果,对于英语 → 德语也有显著改善。
4.4 应用缓存存储上下文信息
使用缓存来存储文档中的相关信息,然后使用此外部存储器来提高翻译质量。Tu 等[8]使用缓存来存储双语上下文中的隐藏表示(见图4),为了帮助将查询(通过注意力产生的当前上下文向量)与源端上下文进行匹配而设计了键,而将值设计为有助于找到相关的目标方信息以生成下一个目标词。然后,通过门控机制将来自缓存的最终上下文向量与解码器隐藏状态进行组合。缓存具有有限的长度,并在生成完整的翻译语句后进行更新。他们在多域汉语 → 英语数据集上进行的实验表明,该方法的有效性对计算成本的影响可忽略不计。
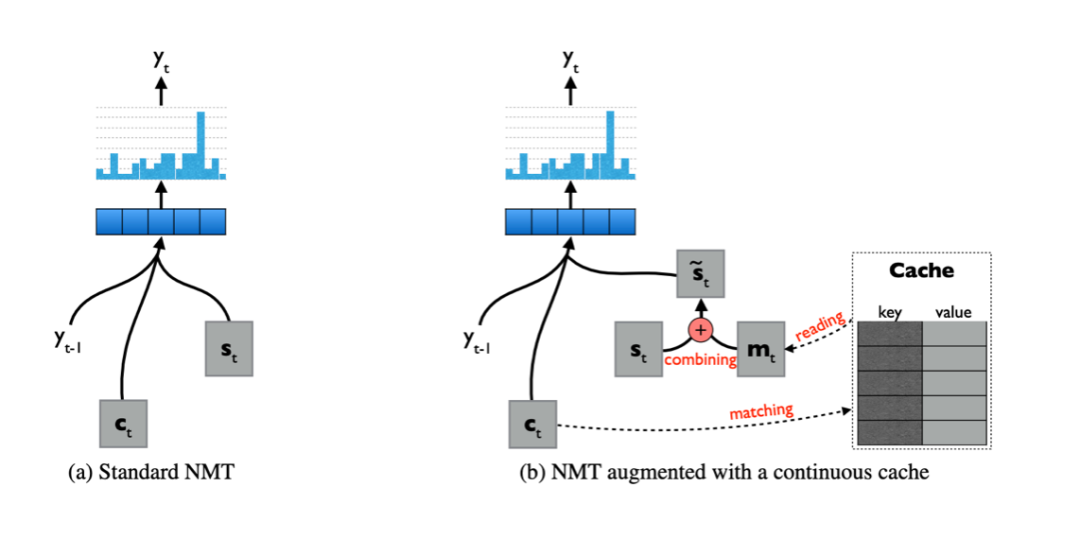
图4:应用缓存存储上下文信息
4.5 使用针对上下文敏感的解码器 (Context-aware Decoder)
Voita 等[9]提出了一种上下文感知解码器(见图5)。他们通过修改 Transformer 体系结构中的解码器,允许多头注意力子层在当前源句子之外还参与先前的上下文句子。他们还添加了一个附加的多头注意力子层,该子层涉及先前的目标上下文句子和当前目标句。他们的模型在引入的有针对性的测试集上表现很好,但是就 BLEU 而言,它的效果与句子级翻译模型相当。他们继续提出了一个上下文感知模型,该模型对一系列句子级别的翻译执行自动编辑,并在彼此的上下文中纠正各个翻译之间的不一致。这项工作的新颖之处在于,该模型仅使用目标语言中的单语文档级数据进行训练,因此学会了将不一致的句子组映射到一致的对应句。他们报告了他们的模型在针对几种语篇现象时对比人类评估上的重大改进。

图5:针对上下文敏感的解码器
4.6 上下文自适应建模
到目前为止,所有提到的工作都用到了神经体系结构,在基本句子级别的 NMT 模型中通过修改结构以合并上下文信息。但是,并非所有上下文信息都有用,同时为了更好的性能,必须忽略其中的一些信息。Zheng 等[10]引入了一个通用框架,该框架利用鉴别符来使 NMT 模型忽略无关信息。
Jean 和 Cho [11]从学习的角度研究了这个问题,并设计了一个正则化关系使 NMT 模型以一种有效的方式来利用上下文信息。该方法适用于 token、句子和语料库级别,他们提出的方法会使模型对其他上下文变得更加敏感,并且在 BLEU 得分方面优于上下文无关的 Transformer 模型。
5.评估方法
机器翻译的输出几乎总是使用 BLEU 和 METEOR 等指标进行评估,这些指标使用翻译和参考之间的 n-gram overlap 来判断翻译质量。但是,这些度量标准不会在翻译中寻找特定的语义现象,因此在评估较长的生成文本的质量时可能会失败。L̈aubli 等[12]发现,在评估翻译的充分性和流畅性时,评估者更喜欢人工翻译。因此,随着翻译质量的提高,迫切需要文档级评估,因为与语篇现象有关的错误在句子级评估中仍然是不可见的。
对于篇章级机器翻译任务所要解决的问题(语义现象),已经有一些工作提出了用于评估特定语篇现象的自动评估指标。
Hardmeier 和 Federico [13], Jwalapuram 等[14] 和 Werlen 等[15]都分别提出了不同思路的针对代词翻译的自动评价方法,依据文本间对齐方式以及代词列表等。Wong 和 Kit [16]和 Gong 等[17]提出关于词汇衔接问题的评价方法,依据主题模型和词法链,他们的工作都针对 BLEU 有了显著改进,而对于 METEOR 则影响不大。Hajlaoui 和 Popescu-Belis [18],Smith 和 Specia [19]提出了针对语篇连接词的评价方法,依据对齐方式以及字典等判断语篇连接词的翻译质量。
6.总结
本文介绍了篇章级机器翻译的重要性以及目前的发展,同时介绍了现有针对篇章级机器翻译的工作以及相关评估方法。
参考资料
[1]Longyue Wang, Zhaopeng Tu, Andy Way, and Qun Liu. Exploiting cross-sentence context for neural machine translation. In EMNLP 2017.
[2]Rachel Bawden, Rico Sennrich, Alexandra Birch, and Barry Haddow. Evaluating discourse phenomena in neural machine translation. In NAACL 2018.
[3]Elena Voita, Pavel Serdyukov, Rico Sennrich, and Ivan Titov. Context-aware neural machine translation learns anaphora resolution. In ACL 2018.
[4]Jiacheng Zhang, Huanbo Luan, Maosong Sun, Feifei Zhai, Jingfang Xu, Min Zhang, and Yang Liu. Improving the transformer translation model with document-level context. In EMNLP 2018.
[5]Ma, Shuming, Dongdong Zhang, and Ming Zhou. A Simple and Effective Unified Encoder for Document-Level Machine Translation. In ACL 2020.
[6]Annette Rios Gonzales, Laura Mascarell, and Rico Sennrich. Improving word sense disam- biguation in neural machine translation with sense embeddings. In WMT 2017.
[7]Valentin Mac ́e and Christophe Servan. Using whole document context in neural machine trans- lation. In IWSLT 2019.
[8]Zhaopeng Tu, Yang Liu, Shuming Shi, and Tong Zhang. Learning to remember translation his- tory with a continuous cache. In TACL 2018.
[9]Elena Voita, Rico Sennrich, and Ivan Titov. When a good translation is wrong in context: Context-aware machine translation improves on deixis, ellipsis, and lexical cohesion. In ACL 2019.
[10]Zaixiang Zheng, Shujian Huang, Zewei Sun, Rongxiang Weng, Xin-Yu Dai, and Jiajun Chen. Learning to discriminate noises for incorporating external information in neural machine translation. CoRR, abs/1810.10317, 2018.
[11]S ́ebastien Jean and Kyunghyun Cho. Context-aware learning for neural machine translation. CoRR, abs/1903.04715, 2019.
[12]Samuel L ̈aubli, Rico Sennrich, and Martin Volk. Has machine translation achieved human parity? A case for document-level evaluation. In EMNLP 2018.
[13]Christian Hardmeier and Marcello Federico. Modelling pronominal anaphora in statistical ma- chine translation. In IWSLT 2010.
[14]Prathyusha Jwalapuram, Shafiq Joty, Irina Temnikova, and Preslav Nakov. Evaluating pronominal anaphora in machine translation: An evaluation measure and a test suite. In EMNLP 2019 and IJCNLP 2019.
[15]Lesly Miculicich Werlen and Andrei Popescu-Belis. Validation of an automatic metric for the accuracy of pronoun translation (APT). In the Third Workshop on Discourse in Machine Translation 2017.
[16]Billy T. M. Wong and Chunyu Kit. Extending machine translation evaluation metrics with lexical cohesion to document level. In EMNLP-CoNLL 2012.
[17]Zhengxian Gong, Min Zhang, and Guodong Zhou. Document-level machine translation eval- uation with gist consistency and text cohesion. In the Second Workshop on Discourse in Machine Translation 2015.
[18]Najeh Hajlaoui and Andrei Popescu-Belis. Assessing the accuracy of discourse connective translations: Validation of an automatic metric. In CICLING 2013.
[19]Karin Sim Smith and Lucia Specia. Assessing crosslingual discourse relations in machine translation. CoRR, abs/1810.03148, 2018.
下载1:四件套
在机器学习算法与自然语言处理公众号后台回复“四件套”,
即可获取学习TensorFlow,Pytorch,机器学习,深度学习四件套!

下载2:仓库地址共享
在机器学习算法与自然语言处理公众号后台回复“代码”,
即可获取195篇NAACL+295篇ACL2019有代码开源的论文。开源地址如下:https://github.com/yizhen20133868/NLP-Conferences-Code
重磅!机器学习算法与自然语言处理交流群已正式成立!
群内有大量资源,欢迎大家进群学习!
额外赠送福利资源!深度学习与神经网络,pytorch官方中文教程,利用Python进行数据分析,机器学习学习笔记,pandas官方文档中文版,effective java(中文版)等20项福利资源
获取方式:进入群后点开群公告即可领取下载链接
注意:请大家添加时修改备注为 [学校/公司 + 姓名 + 方向]
例如 —— 哈工大+张三+对话系统。
号主,微商请自觉绕道。谢谢!

推荐阅读:
Tensorflow 的 NCE-Loss 的实现和 word2vec
多模态深度学习综述:网络结构设计和模态融合方法汇总
awesome-adversarial-machine-learning资源列表











