
大数据挖掘DT数据分析 公众号: datadw
项目背景
拍拍贷“魔镜风控系统”基于400多个数据维度来对当前用户的信用状态进行评估,通过历史数据每个借款人的性别、年龄、籍贯、学历信息、通讯方式、网站登录信息、第三方时间信息等用户信息以及对应的分类标签,在此基础上结合新发标的用户信息,得到用户六个月内逾期率的预测,为金融平台提供关键的决策支持。
数据格式
数据下载–点这里
这里面包含三期数据,每期数据内容和格式相同,这里面包括两部分信息:
一部分是Master
PPD_dat_1.csv
PPD_dat_2.csv
PPD_dat_3.csv

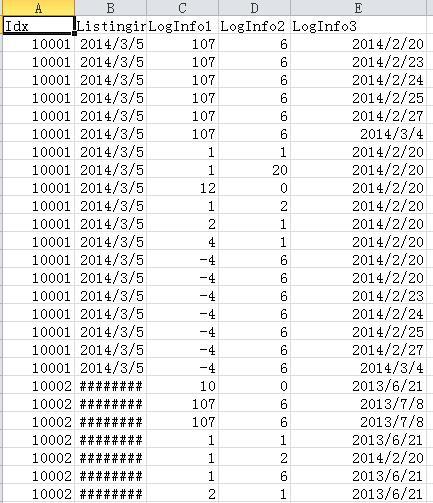
一部分是Log info
PPD_daht_1_LogInfo.csv
PPD_daht_2_LogInfo.csv
PPD_daht_3_LogInfo.csv
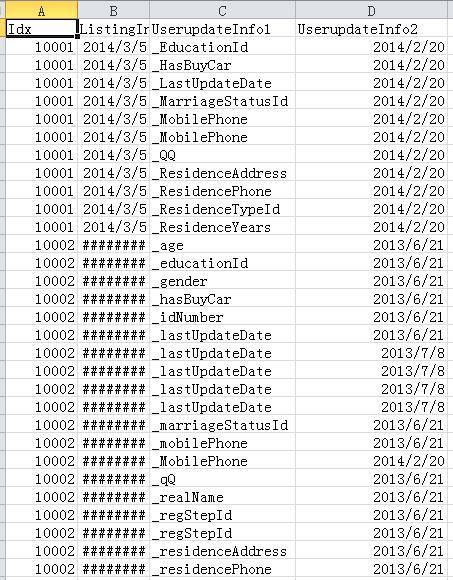
一部分是Update info
PPD_daht_1_Userupdate.csv
PPD_daht_2_Userupdate.csv
PPD_daht_3_Userupdate.csv
3. 问题思路
数据清洗
数据摘要
特征工程
数值特征的保留与非数值特征的转换:有额外信息的非数值变量转化为对应的数值:时间–>年月日周、相对天数,地名–>经纬度和城市等级,定序变量–>序数;其他非数值变量全部0-1哑变量处理。
选取统计量概况一系列相似变量:取中位数、方差、求和、最值、空值树等概况各时期第三方信息、几个城市变量信息等,统计量尽量要相互独立
删除稀疏特征:空值/同一值占绝大比例的列
删除共线特征:相关矩阵的严格下三角阵有接近正负1的列
使用中位数填充空值,通常数据分布不对称时,中位数比平均数更能保持排序关系
最后正态标准化:rank与正态分布的百分位函数复合。之所以考虑正态标准化,是为了应对实际数据的大量有偏分布和极端值,在正态标准化的情况下,数据只保留排序关系,彻底去除了有偏分布和极端值,在大样本下能满足众多模型假设,在本次数据集下能明显提高逻辑回归和神经网络的效果。
模型选择
Logistic Regression
简单、快捷、稳健、可解释性强,工业界最常用的模型之一。虽然LR模型对变量关系的线性限制,使得其难以达到最优,但可以在建模时通过增加L2罚函数
来减少过拟合;此外,作为基准,能够对数据清洗效果和模型表现作出快速评估。最后,与树模型、神经网络模型等模型差异度较大,适合进行模型的加权组合,补充模型精度。
XGBoost 适合处理非线性、变量成分多元化、样本和变量间无固定模式关联(图像、语音),在KDDCup等竞赛中表现优秀的模型之一。如果以精度为目标,综合稳健性、速度、通用性等因素可以首选XGBoost
Keras
,深度学习框架,分为线性模型和泛化模型,其中里面各层独立,灵活性高。深度学习的出发点是各变量充满复杂的非线性关系,通过不断优化网络权值向真实关联趋近;而XGBoost
的出发点是认为各变量独立,从决策树的二分关联叠加向真实关联趋近。所以两者各有特点,有较高的互补性。
交叉检验
变量评估和处理
XGBoost 在建模过程中同时可以得到模型中各个特征的重要程度,可以作为特征重要性的判断标准
LR 模型训练完成后每个特征都有一个权值,权值的大小和正负反映了该特征的重要程度和方向、
通过以上方法可以得到判断出最重要的特征集合,进行可以对这些特征再进行一定的特征工程,实现信息挖掘最大化;同时也能判断出相对影响力极小的特征,需要情况下可以进行清除。
参数优化
在特征工程和模型选择之后,有一项重要且考验耐心的工作,那就是调参。通常情况下,要做以下步骤:
1. 调参之前,理解模型和参数的含义。(否则你很可能不知道调参的粒度和调参的方向)
2. 先用单数据集,从默认值开始,手工逐个调整,对于参数范围大的采取等比数列的方式增加/减少粒度,对于参数范围小的采取等差数列的方式增加/减少粒度。这样做的结果是对各个参数确定了一个合理的范围。
3. 然后可以采用交叉验证和组合搜索的方法来自动得到最优参数,这个过程可能较长,所以这里交叉验证的折数不要太大。另外折数小除了节约时间以外,同时也因为数据集的不同,避免在最后的结果上造成过拟合
模型融合
一种方法是加权融合,
一种方法是基于rank 融合。
4 算法实现过程及其代码细节
4.1 数据清理
引入的包
"""
Created on Sat Jun 18 10:06:28 2016
@author: Yes,boy!
"""import pandas as pdimport numpy as np
path = "D:/InAction/PPDS/data"title = "PPD"
第一部分是处理主表:
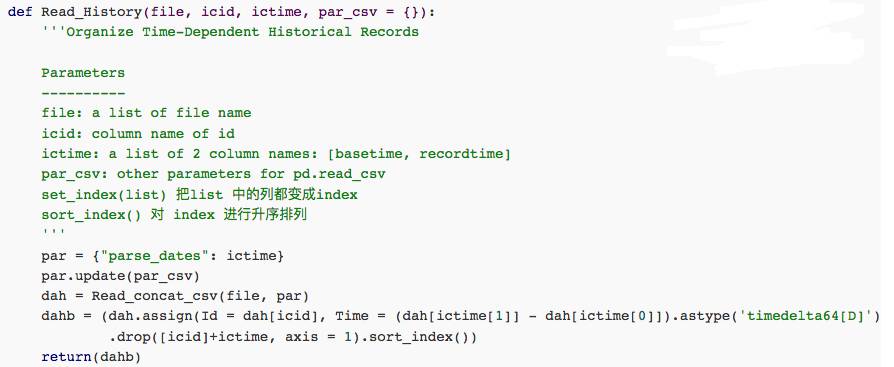
我们首先构造一个函数Read_concat_csv,来实现几份数据的合并,通过pandas.concat 来实现。
def Read_concat_csv(file,par_csv={}):da = pd.concat(map(lambda x:pd.read_csv(x,**par_csv),file))
return da
这里面有三处语法细节:
1. pd.read_csv()
2. map()
3. concat
接着构造一个对数据不统一情况的处理,比如北京和北京市,河南和河南省,以及多余的空格
def Del_string(xstr):
xstrc = xstr.strip().strip(u"市").strip(u"省")
if xstrc=="":
xstrc = np.nan
return xstrc
这里面有一个语法细节:strip()
接下来是对主表开始处理:
第二部分是处理Log 和 Update 表
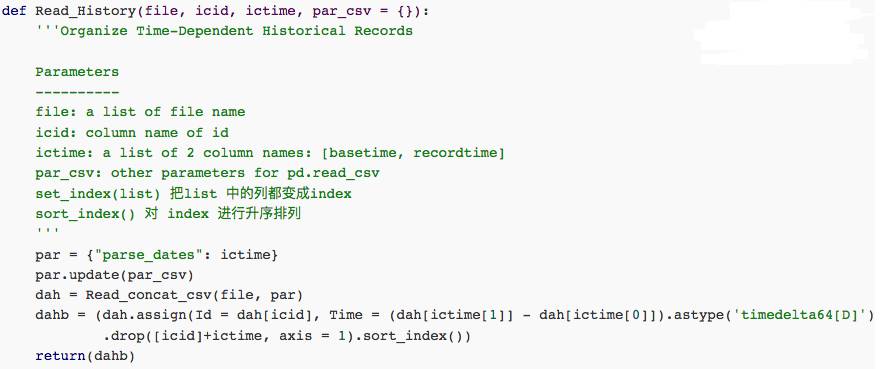
接下来对两个表调用函数进行处理
““
dah1 = Read_History(file = [“{}/{}_dah{}_LogInfo.csv”.format(path, title, x) for x in [“t_1”, “t_2”, “t_3”, “v”]],
icid = ‘Idx’, ictime = [‘Listinginfo1’, ‘LogInfo3’])
dah2 = Read_History(file = [“{}/{}_dah{}_Userupdate.csv”.format(path, title, x) for x in [“t_1”, “t_2”, “t_3”, “v”]],
icid = ‘Idx’, ictime = [‘ListingInfo1’, ‘UserupdateInfo2’],
par_csv = {“converters”: {“UserupdateInfo1”: lambda x: x.lower()}})
“`
人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注










