本刊官方网站:
http://cjjc.ruc.edu.cn/
人工智能技术的发展推动了社交机器人在社会科学研究中的应用。本文从计算传播学的视角出发,探讨社交机器人田野实验的概念界定、方法建构、实验设计及其实际应用,认为社交机器人田野实验结合了大数据分析与仿真方法的优势,已发展为一种高度可控的实验法。社交机器人田野实验为观察、分析与理解数字媒体环境中的传播现象提供了新思路,将助力于新闻传播学理论的验证、探索与拓展。在实证研究部分,本文通过社交机器人田野实验对过滤气泡的成因进行了初步探索。研究发现,即使控制了社交机器人账号的阅读行为偏好,其在随机阅读实验后仍可能陷入过滤气泡。
吴晔,北京师范大学新闻传播学院教授,计算传播学研究中心主任。
黎樟浩,北京师范大学新闻传播学院博士研究生。
闵勇(通讯作者),北京师范大学计算传播学研究中心教授。
本文系北京市社会科学基金项目“全媒体语境下信息流行病学的理论、方法与应用研究”(项目编号:21DTR040);教育部人文社会科学研究规划基金项目“基于社交机器人的跨平台信息茧房形成机制与治理策略研究”(项目编号:23YJA860011)的阶段性成果。
实验法根植于自然科学的实证主义范式,旨在高度控制无关变量的前提下,对研究对象进行不同的实验刺激,以探究自变量与因变量之间的关系,检验理论假设或因果命题。实验法对于建立和评估理论至关重要,成为社会科学的主流研究方法(罗俊,2020)。在传播学中,媒体效果相关研究大量运用了实验法。从20世纪20年代起,在佩恩基金会的资助下研究者们采用实验法开展了“电影对青少年的影响”系列研究。卢因(Kurt Lewin)等人将自然实验运用到群体动力学研究中。第二次世界大战期间,霍夫兰(Carl Hovland)等人通过控制实验进行了说服研究。移动互联网的发展,尤其是社交媒体的普及,让大规模线上实验成为可能(Watts,2007),并推动了一系列突破性成果(Bond et al.,2012;Kramer,Guillory & Hancock,2014)。
社交机器人作为一项日趋成熟的技术,能够模拟真实用户的行为。学者们逐渐开始在社交媒体平台中部署社交机器人并开展田野实验(Chen,Pacheco,Yang & Menczer,2021;Ledford,2020;刘河庆,梁玉成,2023)。该方法能够在真实环境中精确控制实验变量,并为研究者提供日志数据,具有检验及拓展新闻传播理论的潜力。本文将系统地梳理社交机器人田野实验相关概念和研究,分析其在计算传播学研究中的发展脉络、优势、应用以及未来展望。
(一)机器行为范式下的社交机器人
机器行为范式强调所谓的“机器”并不仅局限于技术或具体的机械实体,而应该广泛地考察包括所有人工制造的物体及其引发的现象(Rahwan et al.,2019)。在传播学领域,人机传播理论从上世纪90年代开始兴起。纳斯(Clifford Nass)等人在斯坦福大学开展一系列人机互动实验并总结了“计算机为社会行动者”范式(the Computers are Social Actors Paradigm,CASA),在《媒体等同》中进一步阐释了“媒体等同于人”的观点(Reeves & Nass,1996:305)。研究发现人们像对待人一样对待媒体,并根据计算机等媒体表现出来的社会化线索形成一定的社会规则,并上升为无意识行为(Nass & Moon,2000)。学者们在此基础上将交互对象拓展到更多的技术载体中,提出“媒介是社会行动者”(the media are social actors paradigm,MASA)(Lombard & Xu,2021)。张洪忠和王兢一(2023)将机器行为范式引入新闻传播学实证研究中,并将机器行为定义为“人工智能技术参与的信息传播活动”,如通过社交机器人账号设置公众议程。
在机器行为范式下,本文将社交机器人(social bot)定义为一套能自动生产内容并在社交媒体上与用户互动的、试图模仿并可能改变人类行为的算法系统;在实践中,社交机器人账号是被研究者控制的,能通过仿真模拟人类用户以完成曝光、阅读、点赞、评论、转发等行为的虚拟账号。大量证据表明,社交机器人和算法已经成为影响信息传播的关键因素(Lazer,2015;Ferrara,Varol,Davis,Menczer & Flammini,2016)。在计算宣传的背景下,社交机器人常以发布争议性话题(韩娜,孙颖,2022)、干预信息扩散(师文,陈昌凤,2020)和设置特定议程(赵蓓,张洪忠,2023)等负面形象被认知。因此,社交机器人检测一直是计算机科学领域关注的焦点。其中针对Twitter的社交机器人账号识别方法Botometer(Davis,Varol,Ferrara,Flammini & Menczer,2016)被广泛关注和应用。然而该方法的判断结果并非绝对的,以ChatGPT为代表的大模型将使得社交机器人账号更加接近于人类用户的表达方式,进一步模糊二者的界限,以至于人类用户和识别算法都难以区分账号类型(Ferrara,2023)。据此,社交机器人在人机传播中正逐渐扮演传播主体的角色(张洪忠,王競一,2023),成为活跃的社会行动者(Ferrara,Varol,Davis,Menczer & Flammini,2016),并影响着社会规则(申琦,王璐瑜,2021)。学者们认为,如今的社交机器人可以被看成是和人类一样的主体,从“媒介是人的延伸”延伸到“媒介是人”(高山冰,汪婧,2020),甚至成为智能新物种(宋美杰,刘云,2023)。这些研究暗示着搭载人工智能技术的社交机器人在定位和功能上越来越逼近人类,为社交机器人田野实验奠定了理论和实践基础。
(二)作为“第四象限”的社交机器人田野实验
本文认为,在人工智能技术的加持下,社交机器人田野实验(social bot field experiment)已成为一种可控的,能在真实媒体环境进行因果检验的实验方法。此方法遵循实验法的核心逻辑,通过在真实媒体环境中部署社交机器人账号,分析实验组与对照组之间差异,以评估实验刺激或干预措施所产生的影响,揭示变量间的因果关系。如图1所示,以实验环境和实验被试为划分依据,可以将实验研究归为四类(Salganik,2018),其中横坐标表示实验室环境或田野环境,纵坐标表示真人或非人。第一象限为自然实验,第二象限是实验室实验,第三象限为仿真实验,第四象限为社交机器人田野实验(见图1)。
根据罗俊(2020)对不同实验方法的比较,可以从样本代表性、环境仿真度、实验可控性、主试偏差、受试偏差、可重复性、可证伪性、内部效度和外部效度等方面评估上述四种实验(见表1)。社交机器人田野实验在提供真实环境中的随机分组和控制方面具有明显优势,同时相较于自然实验,它还能够降低伦理风险。例如,在2010年美国国会选举期间,研究者改变了Facebook用户的社交媒体信息环境,直接影响了数百万人的政治表达、信息获取以及现实世界中的投票行为(Bond et al.,2012)。若以社交机器人田野实验开展类似研究则能在较大程度上规避风险。然而,社交机器人田野实验也存在外部效度较低等弊端,得到的结论未必能推广到人类用户中。与仿真实验相比,社交机器人田野实验能够获得真实的田野反馈,但也提高了实验成本,例如难以在短期内测试多个不同参数对实验结果产生的影响。
(三)社交机器人田野实验的特点与优势
田野实验结合了田野调查和实验研究的优势,在社会科学中被广泛使用,其主要特点是能够让研究者在真实世界中直接观察和分析自然状态下的现象和行为,从而使得结论更具解释力。社交机器人田野实验承袭了田野实验的特点,同时具备以下四个方面的优势。
1. 日志数据
社交机器人田野实验允许研究者在保护用户隐私的前提下收集社交机器人账号的日志数据。通过分析日志数据,研究者可以重塑信息环境——了解社交机器人在实验过程中被哪些信息曝光,如何参与信息传播过程,如何与其他实体(如人类用户、平台算法)进行交互等。通过识别和分析日志数据中的信源特征、文本特征、社交网络特征、信息消费偏好以及注意力周期序列等,研究者可以挖掘信息传播模式及其潜在影响因素。此外,日志数据可被用于还原社交机器人账号的完整活动轨迹。研究者可以通过追踪社交机器人账号的历时演变,探究产生组间差异的因果机制。
2. 高度控制
当解除实验室环境的限制后,田野实验常难以对无关变量进行高度控制,使得随机误差对研究结果产生干扰。社交机器人田野实验则能满足这一实验设计要求。研究者能够根据实验设计对社交机器人账号的行为进行高度控制。例如,研究者严格控制社交机器人账号的阅读内容,以探究YouTube平台对特定阅读行为的反馈机制(师文,陈昌凤,2023)。除此之外,由于社交机器人账号的每步行为都是可被记录和可解释的,这也为评估和排除无关变量对实验结果造成的干扰提供了可能。
3. 开源复现
可重复性和可证伪性构成了理论建构的两大核心标准。社交机器人田野实验允许研究者预先注册实验流程并公开其源代码。这提高了研究过程的透明度,也便于伦理风险的评估和审查。通过在不同时间内反复对同一媒体平台上进行社交机器人田野实验,研究者能够细致观察并系统记录该平台随时间推移所经历的动态变化,这也为系统地进行荟萃分析提供数据支持。
4. 技术枢纽
相较于脚本程序,社交机器人具有更高的可拓展性。具体而言,研究者能够通过API(Application Programming Interface)接口,为社交机器人账号集成人工智能技术,包括大模型(Large Language Model)、情感分析、主题识别和文本生成等。这使得社交机器人账号能够更准确地对真实用户进行仿真。例如,社交机器人账号可以分析其他用户的发布内容,根据是否符合自身偏好来选择订阅或关注;基于新闻标题的类型快速判断是否点击阅读;利用上下文信息来判断是否转发或生成相关评论等(Min,Jiang,Jin,Li & Jin,2019)。这为社交机器人田野实验的研究设计提供了更多可能。
本节首先对社交机器人田野实验的一般设计流程进行了梳理,进而总结了以算法、平台和社群为研究对象的设计方案,以探索社交机器人田野实验的可行性与理论潜力。研究者依据不同的研究对象和问题,可以通过控制社交机器人不同程度的仿真程度和介入方式开展田野实验。
(一)社交机器人田野实验的实施流程
社交机器人田野实验的实施流程主要分为三个阶段(见图2)。在准备阶段,研究者主要负责提取平台用户特征并构建社交机器人的运行环境。通过大数据爬虫、问卷调查等方法,获取用户群体的行为特征、社交关系特征、信息消费特征与人口属性特征等,以完成社交机器人对人类行为的模拟及账号设定。同时,为适应不同的实验平台,研究者需要建构社交机器人账号基本操作API。例如,当YouTube的推荐算法如何影响党派信息的曝光时,研究者需要设计特定的API接
口,使得社交机器人账号能够进行“点击侧栏推荐页视频”、“返回首页点击视频”等操作(Hosseinmardi,Ghasemian,Rivera-Lanas,Horta Ribeiro,West & Watts,2024)。
据此基础,研究者可根据实验目的,按社交机器人的仿真策略的差异或账号设定的不同进行实验分组。
在实施阶段,研究者对社交机器人账号进行初始化设置后,将其部署至田野环境中并执行实验任务。
根据实验任务的不同,研究者采集相应的数据,如社交机器人行为数据、与平台互动产生的数据、以及信息曝光数据等。
此外,研究者需定期维护社交机器人的活跃状态和运行环境,以保证实验的可行性。
在分析阶段中,研究者根据社交机器人账号的分组情况,对收集的各类数据进行数据挖掘与分析,通过组内变化、组间差异等分析结果回应诸如传播效果评估、人机交互影响、网络社群分析等研究问题。
(二)针对不同研究对象的社交机器人田野实验设计
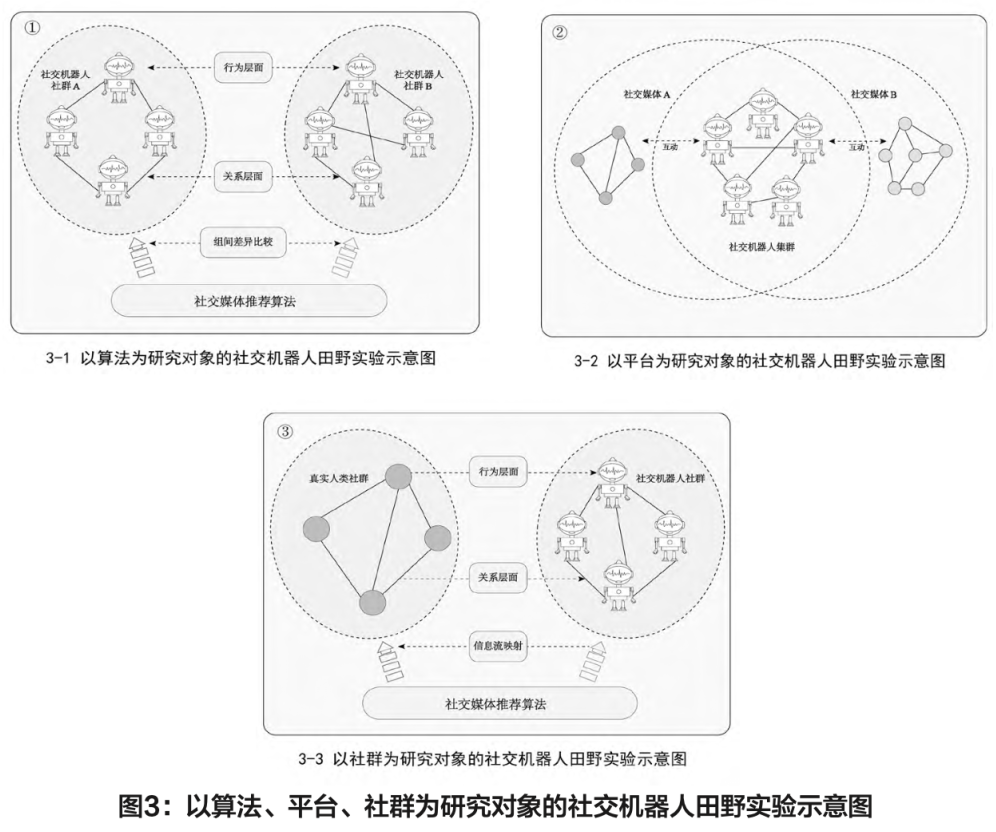
研究者可以以算法、平台和社群为不同的研究对象,从关系和行为层面对社交机器人账号进行实验设计(见图3)。关系层面主要涉及社交机器人账号与其他账号之间的互动,如关注与被关注、转发与被转发等;行为层面则包括阅读、点赞和评论等活动行为。通过控制“机器—机器”“人—机器”之间关系和行为层面的差异,为实验设计提供了较大自由度。
1.以算法为研究对象
算法已经融入到信息的生产流动过程中,在提高效率的同时也出现了歧视偏见等诸多问题。“算法透明”通常是指要求使用者公开源代码并解释基本原理、运行机制和意图等,被视为是算法规制的首要原则。然而算法透明在实践层面却困难重重。算法与用户发生真实互动之后已经变得十分复杂,具有智能性、黑箱性等特征(Pasquale,2016),甚至算法设计者也无法完全控制算法运行(Lazer,2015),公开算法代码也难以评估实际产生的社会影响(徐明华,魏子瑶,2023)。相较于以算法透明为代表的事前规制,以算法问责为代表的事后规制更为得当(沈伟伟,2019),也由此推动了算法审计研究的发展。
算法审计(algorithm audit)是指研究者以不同的输入模拟算法运行场景,通过对照输入与输出的关系,推演算法可能产生的社会影响(Sandvig,Hamilton,Karahalios & Langbort,2014)。近年来,学者们开始通过自动化脚本或马甲(sock puppet)登录等方式,对搜索引擎自动补全(塔娜,林聪,2023)、视频平台主流化(师文,陈昌凤,2023)等问题展开研究。然而,这些研究大多为横截面研究,忽略了用户与平台的交互过程。社交机器人田野实验能开展长期的算法审计实验,其收集的日志数据能让研究者更细致地考察其与算法的互动演化过程。具体而言,研究者可以根据不同的实验设计,将社交机器人账号部署在同一个社交媒体平台中,通过操控行为层面和关系层面以进行实验分组,即调整社交机器人账号自身的关系网络及其与平台算法的互动策略,以获取不同的算法输出结果(见图3-1)。例如,Chen等人(2021)部署了中立的社交机器人账号,设计其关注不同的新闻来源并进行长期跟踪,研究发现它们接触到的新闻和信息在很大程度上取决于早期关注的新闻来源的政治倾向。
2. 以平台为研究对象
社会生活日益受到在线平台的生态系统所调节,平台社会相关研究随之兴起,成为学者们的关注焦点(范·迪克,孙少晶,陶禹舟,2021)。人们可以广泛地、随时随地从不同的平台进行信息消费,接触的内容也是“千人千面”的(Chaffee & Metzger,2001)。实证研究中,单一平台研究较多,而跨平台研究相对较少,其主要原因是跨平台研究面临两个困境:其一是仅通过媒体使用渠道和频次难以确定哪些内容被消费并产生影响;其二则是难以进行跨平台的用户对齐(de Vreese & Neijens,2016)。这些挑战限制了对跨平台差异进行因果检验的探索。
算法、意见领袖、普通用户和社交机器人账号之间的相互作用使得平台变得日益复杂。在不同的平台上,即使相同的用户行为也可能产生不同的结果。这为利用社交机器人田野实验研究平台差异提供了理论基础。研究者能够严格控制社交机器人在不同平台的行为模式,在一定程度上解决了用户对齐问题。在不同的社交媒体中,部署行为模式相同的社交机器人账号则可以观察平台间的差异(见图3-2)。换言之,由于研究者控制了社交机器人与平台的互动模式,因此田野实验所观察到的差异即反映了各平台自身的生态系统及其运行机制,能够尝试对跨平台差异进行因果解释。
3. 以社群为研究对象
以社群为对象的研究设计,其关键在于实现社交机器人集群对真实人类社群的模拟。最理想的模拟结果是能够将社交机器人集群的数据结果映射到真实人类社群中。已有研究发现,以大模型驱动的“硅样本”(silicon samples)能够在一定程度上反映人类样本在不同指标上的分布情况,这将可能对传统调查问卷方法进行革新(Argyle,Busby,Fulda,Gubler,Rytting & Wingate,2023)。在角色扮演过程中,大模型系统已经能够以非常接近人类的方式进行对话(Shanahan,McDonell & Reynolds,2023)。上述研究为社交机器人映射人类社群提供了理论和技术基础。
作为技术枢纽,社交机器人账号能够搭载以大模型为代表的各种人工智能技术从而更好地对人类进行仿真。具体来说,研究者可以利用大模型,为每个社交机器人账号创造人物画像。这些画像不仅包括基本的人口统计信息,如年龄、性别、职业等,还可以细化到个性特征、兴趣爱好、社交习惯等方面(见图3-3)。例如,研究者在微博部署了两类具有不同行为特征的社交机器人账号,一类主要关注科技信息,另一类主要关注娱乐信息,经过一段时间的跟踪后,研究发现后者更容易陷入到过滤气泡中。这意味着关注娱乐信息的账号在信息接收和互动上更容易趋向于同质化(Min,Jiang,Jin,Li & Jin,2019)。
近十多年来,计算传播学逐渐发展成为一种新的研究取向并形成了大数据分析(Atteveldt & Peng,2018)和仿真模拟(Sherry,2015)两种研究范式。大数据方法的数据来源主要为数字踪迹(digital trace)。数字踪迹具备数据量大(big)、实时在线(always-on)和非干预性(nonreactive)等特征,能够客观地测量传播行为(Salganik,2018)。数字踪迹为研究复杂的人类传播行为提供基础,更细颗粒度的日志数据意味着更细微的差异能够被察觉,同时,纵向日志数据能更客观地反映媒体使用带来的实际影响(Choi,2020;Parry,Davidson,Sewall,Fisher,Mieczkowski & Quintana,2021)。然而,数字踪迹的相关研究主要基于用户生成内容(Naab & Sehl,2017),以日志数据驱动的研究则可能因具有较高的隐私风险而相对鲜见。随着人们对数字踪迹暴露个人隐私风险的担忧与日俱增,如何有效获取数据成为计算传播学者无法绕开的难题(李晓静,付思琪,2020)。
仿真模拟方法则遵循实验法的思想,主张将新闻传播系统视为复杂系统,通过建构模型探究微观的传播行为和宏观涌现之间的关系,为信息扩散、舆论极化等现象提供机制性解释和预测,定量地表达和证明质化思想(王敏,张子柯,2022)。国内学者逐渐开始利用仿真方法对沉默的螺旋(王成军,党明辉,杜骏飞,2019)、舆论极化(葛岩,秦裕林,赵汗青,2020)等问题展开研究。然而仿真方法可能出现难以证伪的情况,即可通过调整模型参数以“得到任何想得到的结果”(杨敏,熊则见,2013)。
社交机器人田野实验能有效结合大数据研究和仿真研究的优势,为计算传播学研究提供新思路、新方法和新数据。一方面,研究者能够在不侵犯用户隐私且不需要依靠平台的情况下获取社交机器人账号的日志数据;另一方面,结合人类用户和社交机器人账号的数据,能够系统性地迭代仿真实验的设计思路——具体来说,研究者既能以人类用户的行为特征作为社交机器人的输入参考,使其更接近于人类用户;也能将人类用户产生的数据作为输出参考,以检验社交机器人产生的结果(Waldherr & Wettstein,2019)。在反复验证的过程中形成数据闭环,提高了社交机器人田野实验的可重复性、可解释性和可证伪性。因此,本文认为在当今多元复杂的社交媒体环境中,社交机器人田野实验方法能够为理论创新提供数据、重新检验传统理论以及探索理论的边界。
(一)认知之前:传播效果研究从“曝光”重新出发
传播效果研究大体上经历了“强—弱—强”三阶段变化。在“弱—强”的转变中,议程设置理论的提出是关键的一环。麦库姆斯(Maxwell McCombs)和肖(Donald Shaw)的“教堂山研究”(1972)将注意力放在了媒体对受众认知的影响上——即研究人们“想什么”而不是“怎么想”——而大获成功。然而,如今的媒体环境已然发生巨变,群体把关、过滤气泡、回声室效应等现象广泛地影响了信息流动的过程,使得学者们开始聚焦媒体曝光(media exposure)——在“想什么”之前,研究“看什么”成为重要议题——事实上,如果不在曝光层面考察数字媒体的传播效果,那么理论构建将变得举步维艰(Bennett & Iyengar,2008;Holbert,Garrett,& Gleason,2010)。
媒体曝光通常是指人们接触到的内容,如何在碎片化和高选择性的媒体环境中测量媒体曝光一直是备受关注的问题(de Vreese & Neijens,2016)。大多数媒体曝光研究是基于自我报告的问卷调查。研究者认为,尽管问卷调查随着媒介技术的革新不断迭代,但仍难以实现客观地测量媒体曝光(Prior,2013)。数字踪迹数据收集则是测量媒体曝光的另一条路径,包括平台API、以用户为中心的数据捐赠(data donation)和屏幕追踪等方式,但可能存在伦理风险(Guess,2015;Ohme et al.,2023)。
通过社交机器人田野实验,研究者可以在社交媒体中部署一定数量的社交机器人账号并形成集群,使它们在关系层面和行为层面对目标社群进行仿真,那么社交机器人集群即等价于一个小型模拟社会。通过测量社交机器人集群中的媒体曝光,研究者可以推测特定内容在目标社群中的曝光情况。一般而言,异常流量(如水军)会干扰点赞量和转发量等指标,影响数字踪迹的真实性。然而,基于社交机器人田野实验的方法进行曝光测量并不依赖于数字踪迹,从而规避了异常流量的影响。举例来说,假设存在一个由100个社交机器人组成集群活跃在微博平台上,现需要对微博内容A和B的曝光情况进行测量。对于A而言,在10个社交机器人的日志数据中出现A,那么曝光率为0.1;而在20个社交机器人的日志数据中出现B,那么曝光率为0.2。据此可知,B的曝光率高于A。而在这个过程中,研究结论并不会受到异常流量的影响。另外,由于社交机器人账号仅在群体层面对人类用户进行仿真,并非对某一个具体人类用户进行映射,因而该数字踪迹无法回溯到特定用户,从而降低了伦理风险。总而言之,社交机器人田野实验为媒体曝光的测量和曝光研究开辟了新视角。
(二)新瓶之后:经典理论的再验证与延展
“新瓶装旧酒”即运用新的研究方法重复检验旧的理论,使得研究者陷入精细化的测量中而忽略了问题意识。正如周葆华(2020)所言:“所谓方法,不仅是依附于问题的技术,还可以带来转换视角的新思路”。下文以议程设置理论、社团形成机制以及选择性接触为切入点,探讨社交机器人田野实验如何对传播学理论进行验证与延展。
1. 议程设置理论
议程设置理论关注媒体议程到公众议程的显著性转移。在网络议程设置的相关实证研究中,公众议程的数据收集方式较为复杂,主要包括问卷调查、思维导图、数字踪迹等,然而却可能存在自我汇报偏差、异常流量等问题(张伦,邓依林,2021)。社交机器人田野实验通过分析社交机器人账号的日志数据,可以构建基于曝光行为的和基于阅读行为的议程网络。此外,研究者还可以围绕算法、平台和社群,检验不同情境下的网络议程设置。
2. 社团形成机制
在社会网络分析中,实体属性往往表现为多面的、高维的、稀疏的。如何将语义信息、关系信息和交互信息等多种信息有效整合,以推断和预测社会网络结构,是当前研究中的重要问题(周丽华等,2022)。同样的,在社团结构的相关研究中,社团形成的历时动态数据及相关研究仍较稀缺(李永宁,吴晔,张伦,2021)。通过社交机器人田野实验,可以收集到每个社交机器人账号的信息曝光情况及相关社团形成的历时演变数据。这些数据的综合分析有助于深入探讨信息传播与社团形成的相互作用。










