大家好,由此篇文章起SDbioinfo将新开一个数据可视化专栏,为大家带来生物信息学各方向数据可视化教程,包括工具介绍,代码实现,应用案例等内容。第一篇为Circos图,读者如有期望的工具教程请告知我们,我们会按情况安排到之后的计划中。
一、Circos介绍
1.背景
- Circos 图是一种用于展示复杂数据关系的可视化工具,最初由 Krzywinski 等人开发,主要用于基因组数据的可视化。
- 它通过将数据以环形的方式展示,使得复杂的基因组结构和基因间的关系更加直观易懂。
2.应用领域
- 主要应用于生物信息学,用于展示基因组结构、基因表达数据、染色体相互作用等。
- 也可以用于其他领域,如网络分析、数据关系展示等,帮助研究人员更好地理解和分析复杂的数据集。
3.特点
直观的环形展示
- 将基因组的不同部分以环形的方式展示,每个环代表一个染色体或基因组区域。
- 通过颜色、大小等视觉元素,可以直观地展示基因组的结构特征和基因间的相互作用。
灵活的数据整合
- 可以整合多种类型的数据,如基因组序列数据、基因表达数据、表观遗传学数据等。
- 支持在同一个图中展示多个数据层,方便研究人员进行综合分析。
丰富的可视化选项
- 提供多种可视化选项,如基因组轨道、基因表达时间点、基因间的连接线等。
- 可以根据需要自定义颜色、大小、形状等视觉元素,以突出展示重点信息。
二、R实现Circos代码示例(以AP2基因为例)
library(tidyverse)library(IRanges)library(Biostrings) library(openxlsx)library(dplyr)library(data.table)library(rtracklayer)library(ComplexHeatmap)library(circlize)library(ggplot2)
####Step1: to get chromosome info(chr names + length)####第一步:获得染色体长度和名称信息作为circos plot圆盘极坐标Toxo.fasta_all readDNAStringSet("/Users/sidaye/Documents/R/AP2_all_analysis/Input/Toxo_ME49v62/ToxoDB-62_TgondiiME49_Genome.fasta") #names(Toxo.fasta_all)#rule out contigs/scaffolds and keep the chromosomeToxo.fasta c(1:14),]#head(Toxo.fasta)
Chr.len unlist(lapply(strsplit(names(Toxo.fasta), ' | '), '[[',7))Chr.len unlist(lapply(strsplit(Chr.len, '='), '[[',2))Chr.name unlist(lapply(strsplit(names(Toxo.fasta), ' | '), '[[',1))Chr.name unlist(lapply(strsplit(Chr.name, '_'), '[[',2))
Genome.len frame(Chr.name = Chr.name, Length = Chr.len)head(Genome.len) ###Datafrome contains info
## Chr.name Length
## 1 chrIa 1859933
## 2 chrIb 1955354
## 3 chrII 2347032
## 4 chrIII 2532871
## 5 chrIV 2686605
## 6 chrV 3331915
####第二步:把Genome.len作为refref
####3. Prepare the dataframe(bed file) for transcript track for genomicrectangular plot to show the transcript of whole genome####第三步:得到需要画的最外层圆轮的转录本/CDS区域的坐标储存在bed file##use the gtf file instead of gff file gtf_genome "/Users/sidaye/Documents/R/AP2_all_analysis/Input/Toxo_ME49v62/ToxoDB-62_TgondiiME49.gtf", sep = '\t')transcript_gtf % dplyr::filter(V3 == 'transcript')CDS_gtf% dplyr::filter(V3 == 'CDS')##transform gtf file into bed filefunction_gtf_to_bed x % dplyr::select(V1, V4, V5, V9, V3, V7) x % dplyr::rename(V1=V1, V2=V4, V3=V5, V4=V9, V5=V3, V6=V7) x$V5 '0' return(x)}transcript_bed transcript_names ' '), '[[',2))transcript_names ';'),'[[',1))transcript_bed$V4 #write.table(transcript_bed, '/Users/sidaye/Documents/R/AP2_all_analysis/Output/transcript_loci_Toxo_v62.bed', col.names = F, quote = F, row.names = F, sep = '\t')CDS_bed CDS_names ' '), '[[',4))CDS_names ';'), '[[',1))CDS_bed$V4 original_chr_names ' | '), '[[',1))original_chr_names 1:14]print(original_chr_names) ####这里是获取染色体的名称,需要注意染色体名称,因为后面到画图时染色体名称对应极坐标的x-axis
## [1] "TGME49_chrIa" "TGME49_chrIb" "TGME49_chrII" "TGME49_chrIII"
## [5] "TGME49_chrIV" "TGME49_chrV" "TGME49_chrVI" "TGME49_chrVIIa"
## [9] "TGME49_chrVIIb" "TGME49_chrVIII" "TGME49_chrIX" "TGME49_chrX"
## [13] "TGME49_chrXI" "TGME49_chrXII"
####Step4. To change the chromosomes names####第四步:确认和修改染色体名称,以免后面画图造成错误function_change_chr_names function(x){ for (i in 1:length(original_chr_names)){ x$V1 gsub(original_chr_names[i], Chr.name[i], x$V1) } return(x)}head(transcript_bed)
## V1 V2 V3 V4 V5 V6
## 1 TGME49_chrII 17422 22256 TGME49_220840-t26_1 0 -
## 2 TGME49_chrII 23771 24986 TGME49_220850-t26_1 0 -
## 3 TGME49_chrII 23771 30138 TGME49_220860-t26_1 0 +
## 4 TGME49_chrII 30196 34402 TGME49_220870-t26_1 0 -
## 5 TGME49_chrII 34473 38391 TGME49_220880-t26_1 0 +
## 6 TGME49_chrII 37902 41699 TGME49_220890-t26_1 0 -
transcript_bed_new transcript_bed_new %dplyr::filter(grepl('chr', V1)) #filter rows that contain a certain string 'chr'#####可以明显看到这里chromosome name 改过来了,例如TGME49_chrII 改成了chrII, chrII会作为后面画图的每一个染色体的x-axis名称head(transcript_bed_new )
## V1 V2 V3 V4 V5 V6
## 1 TGME49_chrII 17422 22256 TGME49_220840-t26_1 0 -
## 2 TGME49_chrII 23771 24986 TGME49_220850-t26_1 0 -
## 3 TGME49_chrII 23771 30138 TGME49_220860-t26_1 0 +
## 4 TGME49_chrII 30196 34402 TGME49_220870-t26_1 0 -
## 5 TGME49_chrII 34473 38391 TGME49_220880-t26_1 0 +
## 6 TGME49_chrII 37902 41699 TGME49_220890-t26_1 0 -
CDS_bed_new CDS_bed_new %dplyr::filter(grepl('chr', V1))
####5. Prepare the dataframe for the peaking time of all the AP2s and genomic loci of each AP2####5.第五步:这里需要准备dot plots(显示每一个AP2基因的转录本表达peak time)的表格AP2s_transcript_loci read.csv("/Users/sidaye/Documents/R/AP2_all_analysis/Input/ME49_AP2_genomicposition.csv")AP2s_list_source_id AP2s_transcript_loci$source_idAP2s_transcript_loci transcript_bed_new[(transcript_bed_new$V4 %in% AP2s_list_source_id),]max(AP2s_transcript_loci$V3-AP2s_transcript_loci$V2)
head(AP2s_transcript_loci) ######显示需要画的所有AP2基因的坐标轴
## [1] 21232
####6. Prepare the dataframe for y-axis of dots####6. 第六步:这里根据每一一副图希望描述的特征和对象不同来进行修改,也就是储存基因特征的表格,这个表格是最终画图的表格####主要包含信息是每个基因的表达时间(这个可以是用数字表示的任何特征,比如相关性等等)和每个基因的坐标AP2s_transcript_loci$V4 unlist(lapply(strsplit(AP2s_transcript_loci$V4, "-"), "[[", 1))AP2_loci data.frame(AP2 = AP2s_transcript_loci$V4, start = AP2s_transcript_loci$V2, end = AP2s_transcript_loci$V3, chr = AP2s_transcript_loci$V1)#####AP2_loci2 AP2_loci[c(53, 18:21, 63:67, 32:33, 42:44, 54:62, 22:24, 25:31, 45:52, 7:17, 1:6, 34:41),]AP2_Peak data.frame(chr = AP2s_transcript_loci$V4, start = AP2s_transcript_loci$V2, end = AP2s_transcript_loci$V3, time = rep(0, 67))AP2_Peak2AP2_Peak[c(53, 18:21, 63:67, 32:33, 42:44, 54:62, 22:24, 25:31, 45:52, 7:17, 1:6, 34:41),]#AP2_Peak2$time head(AP2_Peak2)
## chr start end time
## 53 TGME49_208020 517009 529250 0
## 18 TGME49_252370 516506 523610 0
## 19 TGME49_253380 904923 917480 0
## 20 TGME49_299150 2145570 2154749 0
## 21 TGME49_299020 2241912 2249335 0
## 63 TGME49_320700 130940 133193 0
AP2_microarray read.xlsx("/Users/sidaye/Documents/R/AP2_all_analysis/Input/microarray_cyclic_timing2.xlsx")AP2_microarray$GeneID gsub('-','_', AP2_microarray$GeneID)AP2_microarray AP2_microarray[AP2_microarray$GeneID %in% AP2_Peak2$chr, ]colnames(AP2_microarray)[1] "chr"#####since the order of AP2 in AP2_Peak2 has already been adjusted to corresponding to the order of chromosom, so it should be fixed in order to make nested zooming figureAP2_Peak_all left_join(AP2_Peak2, AP2_microarray, by="chr")AP2_Peak_constitutive AP2_Peak_all %>% dplyr::filter(constitutive == 1)AP2_Peak_constitutive_list AP2_Peak_constitutive$chrAP2_Peak_cyclic AP2_Peak_all %>% dplyr::filter(cyclic == 1)AP2_Peak_noexpressed AP2_Peak_all[is.na(AP2_Peak_all$expressed),]AP2_Peak_noexpressed_list AP2_Peak_noexpressed$chr ###########for those genes is constitutive, even though it has a peak time, just to make it as a line across the all cell cycleAP2_Peak2$time AP2_Peak_all$peak.time##########label all the constitutive genes as peaking time "1.11111"AP2_Peak2 AP2_Peak2 %>% dplyr::mutate(time=ifelse(chr %in% AP2_Peak_constitutive_list, 1.11111, time))######Because the cell cycle is cyclic, so those AP2s have peaking time at 0 or 6 should indicate at both 0 and 6 (C1->G)AP2_Peak_cyclic AP2_Peak2[AP2_Peak2$chr%in%AP2_Peak_cyclic$chr,]AP2_Peak_GtoC AP2_Peak_cyclic %>% dplyr::filter(time == 0)AP2_Peak_GtoC$time rep(6,nrow(AP2_Peak_GtoC))AP2_Peak_CtoG AP2_Peak_cyclic %>% dplyr::filter(time == 6)AP2_Peak_CtoG$time rep(0,nrow(AP2_Peak_CtoG))AP2_Peak3 rbind(AP2_Peak2,AP2_Peak_GtoC,AP2_Peak_CtoG)head(AP2_Peak3) ####准备好的最终画图表格格式
## chr start end time
## 53 TGME49_208020 517009 529250 1.11111
## 18 TGME49_252370 516506 523610 1.11111
## 19 TGME49_253380 904923 917480 5.50000
## 20 TGME49_299150 2145570 2154749 NA
## 21 TGME49_299020 2241912 2249335 NA
## 63 TGME49_320700 130940 133193 NA
####7.prepare the corresponding dataframe for nested zooming connection in the plot####第七步.因为我们需要花nested zoom in circos plot,需要做一个另外的table提供nested zoom in的坐标信息####前三列是最外层一轮的坐标,后三列是里面nested circos plot的坐标,因为nested circos plot外层和里层极坐标不一样####需要设置关系表格correspondance,来表明两套极坐标的关系correspondance data.frame(chr = AP2s_transcript_loci$V1, start = AP2s_transcript_loci$V2, end = AP2s_transcript_loci$V3, AP2 = AP2s_transcript_loci$V4, start.1 = AP2s_transcript_loci$V2, end.1 = AP2s_transcript_loci$V3)###调整顺序correspondance2 correspondance[c(53, 18:21, 63:67, 32:33, 42:44, 54:62, 22:24, 25:31, 45:52, 7:17, 1:6, 34:41),]head(correspondance2)
## chr start end AP2 start.1 end.1
## 53 chrIb 517009 529250 TGME49_208020 517009 529250
## 18 chrIII 516506 523610 TGME49_252370 516506 523610
## 19 chrIII 904923 917480 TGME49_253380 904923 917480
## 20 chrIII 2145570 2154749 TGME49_299150 2145570 2154749
## 21 chrIII 2241912 2249335 TGME49_299020 2241912 2249335
## 63 chrIV 130940 133193 TGME49_320700 130940 133193
3.绘图
初始化Circos图
########################################################Starting to plot circos########################################################Starting to plot circos########################################################Starting to plot circos#clear all the previous circos plotcircos.clear()#set color for text in the circos plotcol_text "black"#set up 12 random colors # chrIa chrIb chrII chrIII chrIV chrV chrVI chrVIIa chrVIIb chrVIII chrIX #"#AD2D0533" "#FFC78833" "#1018E833" "#C0670E33" "#6EFFC833" "#95387433" "#E4BF8D33" "#0992C633" "#7E30CB33" "#A1884333" "#3FC7F433" # chrX chrXI chrXII #"#34E28D33" "#363ED033" "#78ECDE33" #chr_bg_color = rand_color(14, transparency = 0.8)chr_bg_color =c("#AD2D0533" , "#FFC78833", "#1018E833", "#C0670E33", "#6EFFC833", "#95387433", "#E4BF8D33", "#0992C633", "#7E30CB33", "#A1884333","#3FC7F433", "#34E28D33", "#363ED033", "#78ECDE33")names(chr_bg_color) = ref$Chr.name
#Sectors in `f1()` and `f2()` should be in the same order, or else the connection lines may overlapf1 = function() { circos.par("track.height"=0.8,gap.degree=2,start.degree = 90,clock.wise = T, cell.padding=c(0,0,0,0)) #create circos object, 14=number of chromosome circos.initialize(factors=ref$Chr.name, xlim=matrix(c(rep(0,14),ref$Length),ncol=2) ) #cex,Specify the size of the title text with a numeric value of length 1 #######Track1 #set the chromosome name as track1, set the bg.col as white #change font by cex circos.track(ylim=c(0,1),panel.fun=function(x,y) { Genome=CELL_META$sector.index xlim=CELL_META$xlim ylim=CELL_META$ylim circos.text(mean(xlim),mean(ylim),Genome,cex=3,col=col_text, facing="outside",niceFacing=TRUE,font =2) },bg.col="white",bg.border=F,track.height=0.05) #set gap between tracks set_track_gap(mm_h(1)) # 0.5cm #set_track_gap(mm_h(2)) # 2mm #set track2 and add scale to the track circos.track(ylim=c(0,1),panel.fun=function(x,y) { Genome=CELL_META$sector.index xlim=CELL_META$xlim ylim=CELL_META$ylim circos.text(mean(xlim),mean(ylim),Genome,cex=0.03,col="#808080", facing="outside",niceFacing=TRUE) },bg.col=chr_bg_color,bg.border=F,track.height=0.02) #ref check the largest length of the chromosome #max(ref$Length) #7353086 #brk 0.0, 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0)*10^6 #line width=lwd #circos.track(track.index = get.current.track.index(), panel.fun = function(x, y) { #circos.axis(h="top",major.at=brk,labels=round(brk/10^6,1),labels.cex=1.2, #col=col_text,labels.col=col_text,lwd=0.8, labels.facing="clockwise") #},bg.border=F) set_track_gap(mm_h(0.5)) ##track3 shows the positions for all genes transcript circos.genomicTrackPlotRegion( transcript_bed_new, track.height = 0.05, stack = F, bg.border = NA, ylim = c(0,1), panel.fun = function(region, value, ...) { circos.genomicRect(region, value, col = 'black', border = NA, ...) } )}circos.yaxis.scale as.numeric(c(0, 3, 4.7, 5, 6))#sector.index for constitutive genessector.index.constitutive in%AP2_Peak_constitutive_list) sector.index.noexpressed in%AP2_Peak_noexpressed_list) ###################To change all the GeneID in input dataframe into AP2 namesAP2_geneID2name "/Users/sidaye/Documents/R/AP2_all_analysis/Input/AP2_geneID2name.xlsx")colnames(AP2_geneID2name)[1] "chr"AP2_Peak_all2 by="chr")AP2_Peak_all2$Ap2Name2 'P2'), '[[',2))#gap.after is a vector means the gap between each neighboring sectors#Total track.height =1#Input dataframe has standardized format:chr, start, end, timef2 = function() { #this track shows the position of each AP2s on the genome and the nested zooming track for the peaking time during CDC circos.par(cell.padding = c(0, 0, 0, 0), gap.after = c(rep(1, nrow(AP2_loci)-1), 10)) #To create new sectors for the second part circos.genomicInitialize(AP2_loci2, plotType = NULL) circos.track(ylim=c(0,1),bg.col="white",bg.border=F,track.height=0.18) AP2_Peak3_new AP2_Peak3_new % dplyr::mutate(x.center=round((start+end)/2)) sector_indices get.all.sector.index() for (i in 1:67){ circos.text(AP2_Peak3_new$x.center[i], 0.5, AP2_Peak_all2$Ap2Name2[i], sector.index = sector_indices[i], track.index = get.current.track.index(), cex=1.8, col=ifelse(i %in% sector.index.constitutive,"#d42729" ,ifelse(i %in% sector.index.noexpressed ,"grey16" ,"#0080ff")), font = 2, facing="reverse.clockwise",niceFacing=TRUE)} set_track_gap(cm_h(0.8)) #set_track_gap(mm_h(1.2)) #track.height here change the height of dot block circos.genomicTrack(AP2_Peak3, ylim = c(0, 6),track.height=0.4, #the panel.fun argument is used to specify a function that will be called for each sector of a circular plot panel.fun = function(region, value, ...) { #here, the sector.index is the name of each AP2 genes sector_indices get.all.sector.index() rec_colors "#f8c09b", "#e7db9f", "#bfc9a8", "#dea9f9") circos.rect(CELL_META$cell.xlim[1],0,CELL_META$cell.xlim[2],3, col=rec_colors[1], border = NA) circos.rect(CELL_META$cell.xlim[1],3,CELL_META$cell.xlim[2],4.7, col=rec_colors[2], border = NA) circos.rect(CELL_META$cell.xlim[1],4.7,CELL_META$cell.xlim[2],5, col=rec_colors[3], border = NA) circos.rect(CELL_META$cell.xlim[1],5,CELL_META$cell.xlim[2],6, col=rec_colors[4], border = NA) for(h in circos.yaxis.scale) { #CELL_META is an easy way to get meta data in the current cell #The cell.xlim element specifies the range of x-axis values that are visible within the cell. circos.lines(CELL_META$cell.xlim, c(h, h), lty = 4, col = "grey16") } circos.genomicPoints(region, value, col = ifelse(value[[1]] == 0|value[[1]] == 6, "#0080ff",ifelse(value[[1]] ==1.11111, "white", "#0080ff")), pch = 16, cex = ifelse(value[[1]] == 0|value[[1]] == 6, 1.8,ifelse(value[[1]] ==1.11111, 0.01, 1.8)) ) }, bg.col = "white", track.margin = c(0.02, 0)) #for (i in sector.index.constitutive){ #circos.lines(c(AP2_Peak3_new$x.center[i], AP2_Peak3_new$x.center[i]), CELL_META$cell.ylim, #sector.index = sector_indices[i], #track.index = get.current.track.index(), #lty = 1, #col ="#d42729") #} circos.yaxis(side = "left", at = circos.yaxis.scale, sector.index = get.all.sector.index()[1], labels = FALSE)}#circos.nested shows the zooming connecting parts, the order of sector should be the same as the df "AP2_loci2" and "AP2_Peak3"circos.nested(f1, f2, correspondance2, connection_col = chr_bg_color[correspondance2[[1]]])

#15inches X 15inches#legend("right", inset=.02, title="Category",# c("Constitutive","Not expressed","Cyclic"), fill=c('#d42729', 'grey16', '#377EB8'), horiz=F, cex=0.8)circos.info()
## No sector has been created
##
## No track has been created
#circos.par: Parameters for the circular layoutcircos.clear()
三、应用案例
1.基因组结构展示
- 通过展示染色体的排列和基因的位置,帮助理解基因组的整体结构。
- 例如,展示不同物种或不同个体的基因组结构,比较它们之间的相似性和差异性。
2.基因表达分析
- 展示基因在不同时间点的表达模式,分析基因表达的动态变化。
- 例如,展示 AP2 基因在细胞周期不同阶段的表达时间,研究其在细胞周期调控中的作用。
3.基因间相互作用
- 通过连接线展示基因间的相互作用关系,帮助理解基因调控网络。
- 例如,展示染色体之间的相互作用、基因之间的调控关系等。
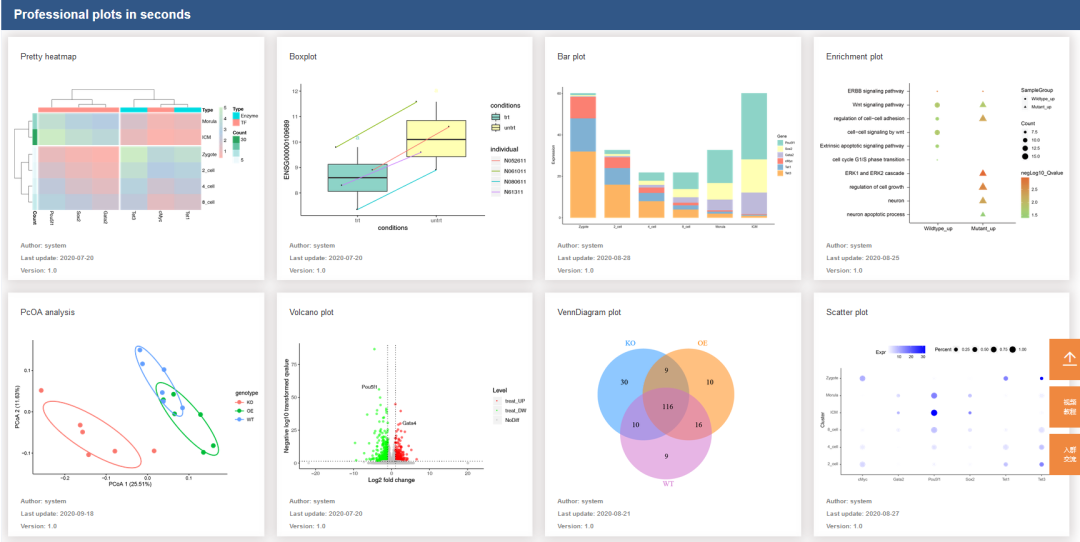
高颜值免费 SCI 在线绘图(点击图片直达)
最全植物基因组数据库IMP (点击图片直达)
往期精品(点击图片直达文字对应教程)
机器学习