正文
国防科学技术大学博士生
SQuAD比赛第三名
研究方向为自动问答系统
1. 引言
教机器学会阅读是近期自然语言处理领域的研究热点之一,也是人工智能在处理和理解人类语言进程中的一个长期目标。得益于深度学习技术和大规模标注数据集的发展,用端到端的神经网络来解决阅读理解任务取得了长足的进步。本文是一篇机器阅读理解的综述文章,主要聚焦于介绍公布在 SQuAD(Stanford Question Answering Dataset)榜单上的各类模型,并进行系统地对比和总结。
2. SQuAD简介
SQuAD 是由 Rajpurkar 等人[1]提出的一个最新的阅读理解数据集。该数据集包含 10 万个(问题,原文,答案)三元组,原文来自于 536 篇维基百科文章,而问题和答案的构建主要是通过众包的方式,让标注人员提出最多 5 个基于文章内容的问题并提供正确答案,且答案出现在原文中。SQuAD 和之前的完形填空类阅读理解数据集如 CNN/DM[2],CBT[3]等最大的区别在于:SQuAD 中的答案不在是单个实体或单词,而可能是一段短语,这使得其答案更难预测。SQuAD 包含公开的训练集和开发集,以及一个隐藏的测试集,其采用了与 ImageNet 类似的封闭评测的方式,研究人员需提交算法到一个开放平台,并由 SQuAD 官方人员进行测试并公布结果。

▲ 图1:一个(问题,原文,答案)三元组
3. 模型
自从 SQuAD 数据集公布以来,大量具有代表性的模型纷纷涌现,极大地促进了机器阅读理解领域的发展,下面就 SQuAD 榜单上代表性的模型进行介绍。总的来说,由于 SQuAD 的答案限定于来自原文,模型只需要判断原文中哪些词是答案即可,因此是一种抽取式的 QA 任务而不是生成式任务。几乎所有做 SQuAD 的模型都可以概括为同一种框架:Embed 层,Encode 层,Interaction 层和 Answer 层。Embed 层负责将原文和问题中的 tokens 映射为向量表示;Encode 层主要使用 RNN 来对原文和问题进行编码,这样编码后每个 token 的向量表示就蕴含了上下文的语义信息;Interaction 层是大多数研究工作聚焦的重点,该层主要负责捕捉问题和原文之间的交互关系,并输出编码了问题语义信息的原文表示,即 query-aware 的原文表示;最后 Answer 层则基于 query-aware 的原文表示来预测答案范围。
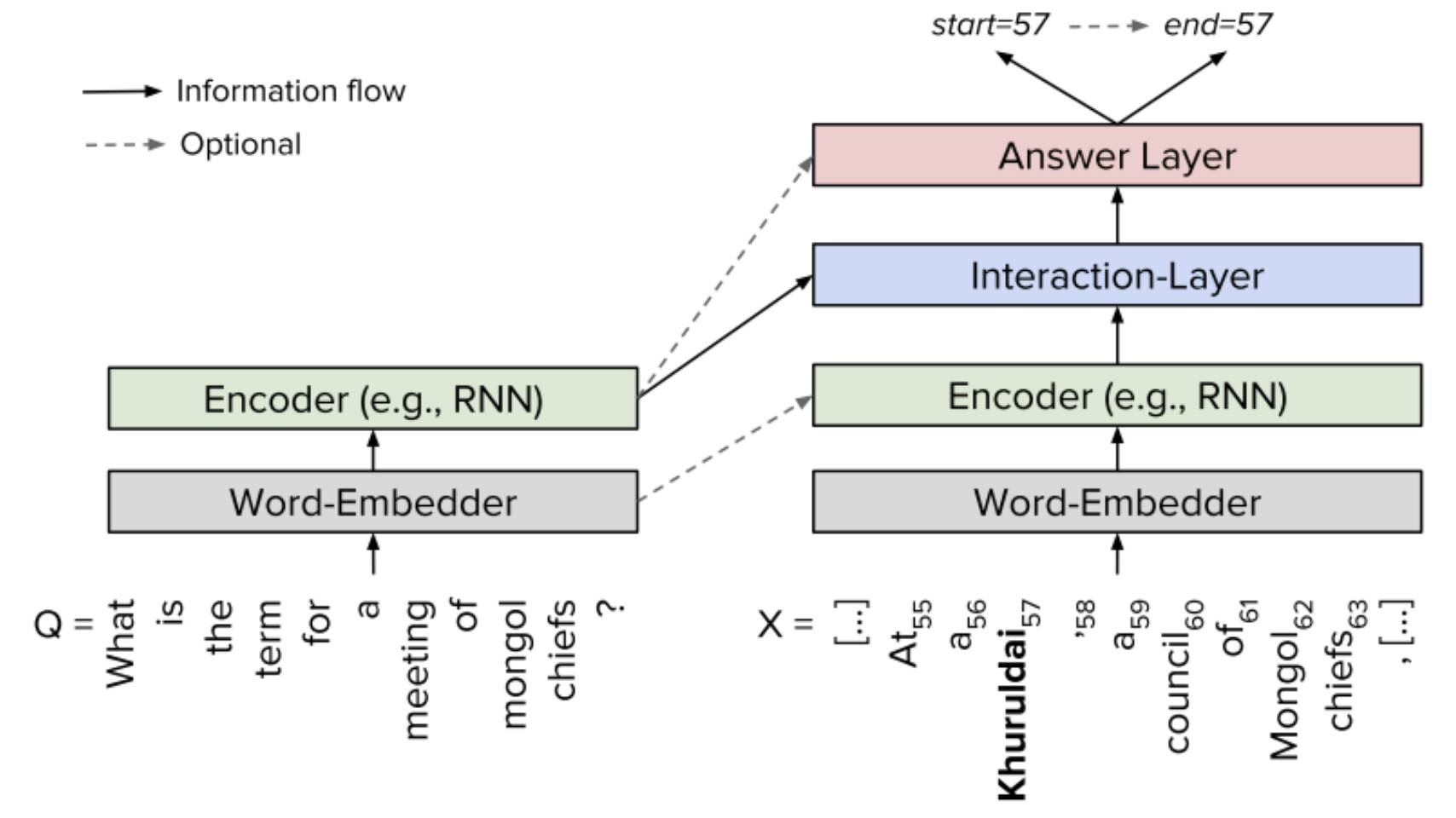
▲
图2:一个高层的神经 QA 系统基本框架,来自[8]
3.1 Match-LSTM[4]
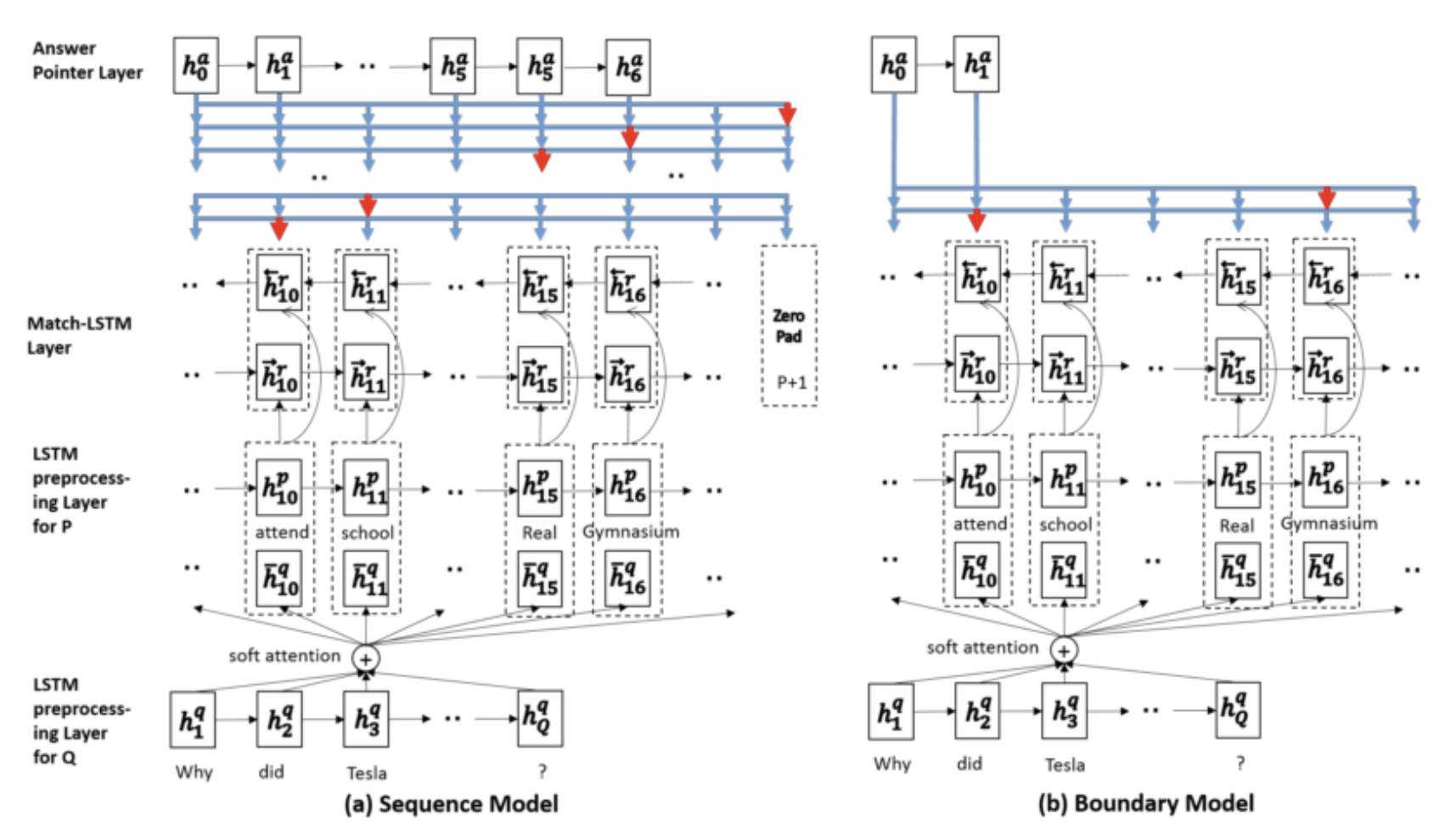
Match-LSTM 的 Answer 层包含了两种预测答案的模式,分别为 Sequence Model 和 Boundary Model。Sequence Model 将答案看做是一个整数组成的序列,每个整数表示选中的 token 在原文中的位置,因此模型按顺序产生一系列条件概率,每个条件概率表示基于上轮预测的 token 产生的下个 token 的位置概率,最后答案总概率等于所有条件概率的乘积。Boundary Model 简化了整个预测答案的过程,只预测答案开始和答案结束位置,相比于 Sequence Model 极大地缩小了搜索答案的空间,最后的实验也显示简化的 Boundary Model 相比于复杂的 Sequence Model 效果更好,因此 Boundary Model 也成为后来的模型用来预测答案范围的标配。
在模型实现上,Match-LSTM 的主要步骤如下:
1) Embed 层使用词向量表示原文和问题;
2) Encode 层使用单向 LSTM 编码原文和问题 embedding;
3) Interaction 层对原文中每个词,计算其关于问题的注意力分布,并使用该注意力分布汇总问题表示,将原文该词表示和对应问题表示输入另一个 LSTM 编码,得到该词的 query-aware 表示;
4) 在反方向重复步骤 2,获得双向 query-aware 表示;
5) Answer 层基于双向 query-aware 表示使用 Sequence Model 或 Boundary Model 预测答案范围。
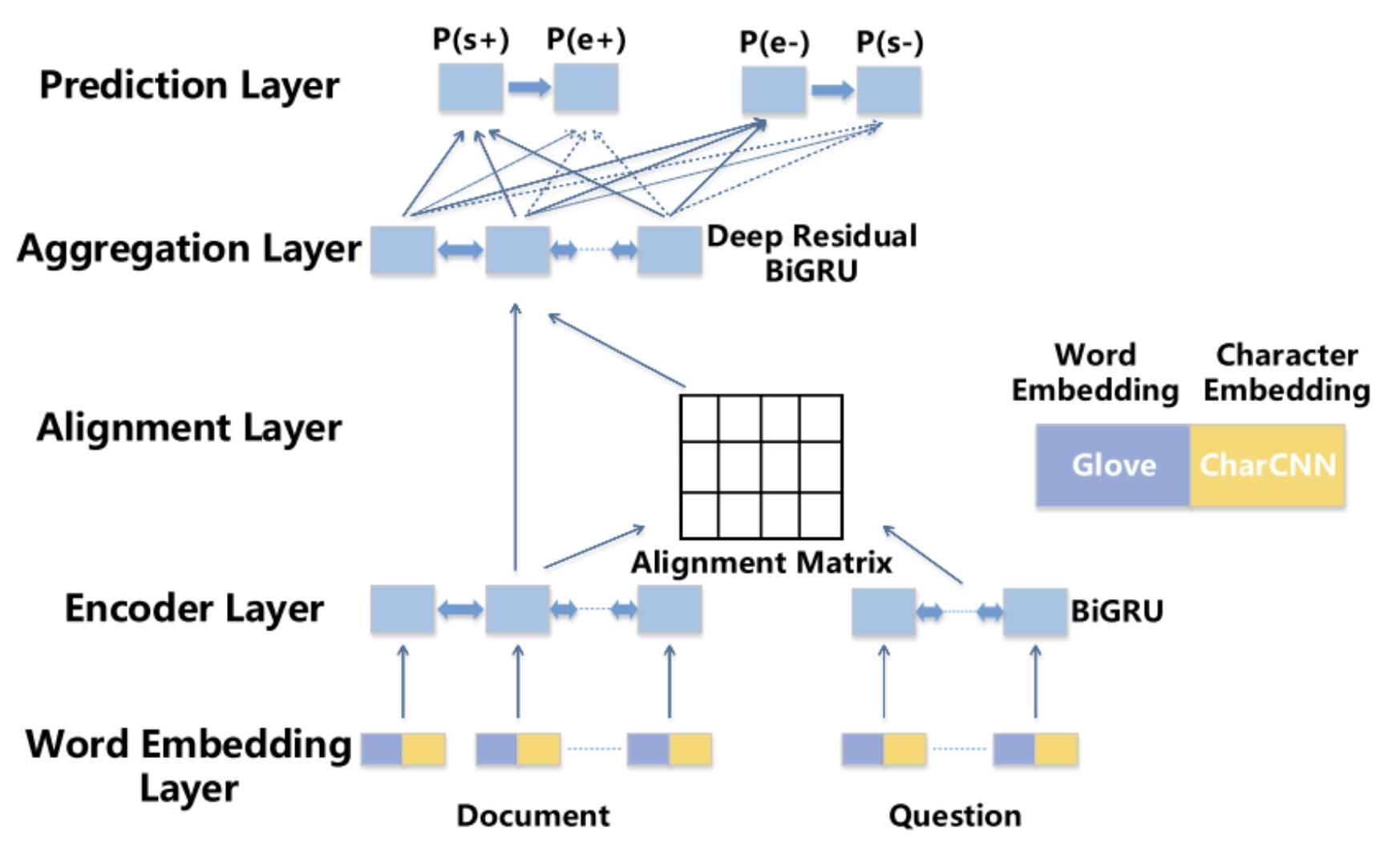
3.2 BiDAF[5]
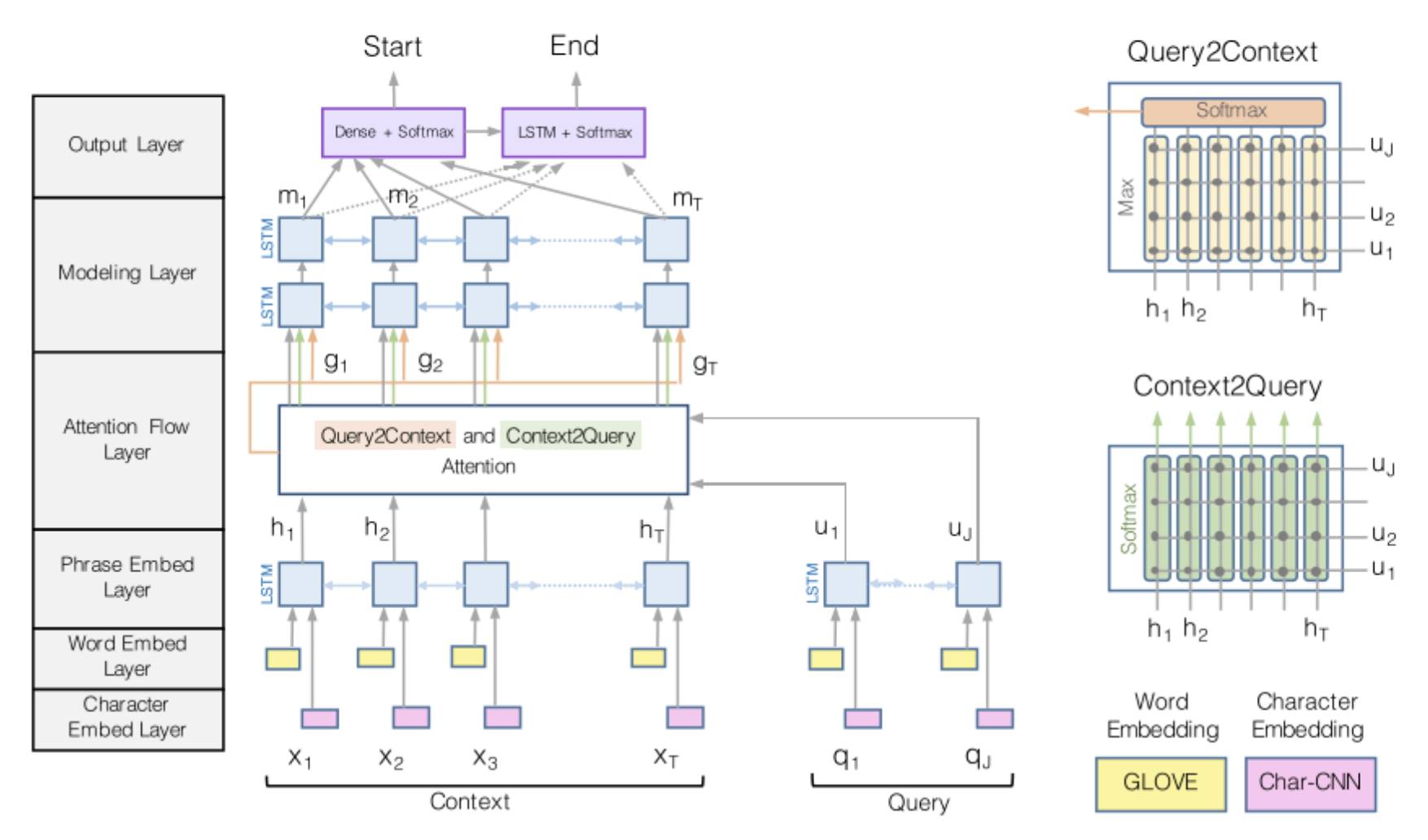
相比于之前工作,BiDAF(Bi-Directional Attention Flow)最大的改进在于 Interaction 层中引入了双向注意力机制,即首先计算一个原文和问题的 Alignment matrix,然后基于该矩阵计算 Query2Context 和 Context2Query 两种注意力,并基于注意力计算 query-aware 的原文表示,接着使用双向 LSTM 进行语义信息的聚合。另外,其 Embed 层中混合了词级 embedding 和字符级 embedding,词级 embedding 使用预训练的词向量进行初始化,而字符级 embedding 使用 CNN 进一步编码,两种 embedding 共同经过 2 层 Highway Network 作为 Encode 层输入。最后,BiDAF 同样使用 Boundary Model 来预测答案开始和结束位置。
3.3 Dynamic Coattention Networks[6]
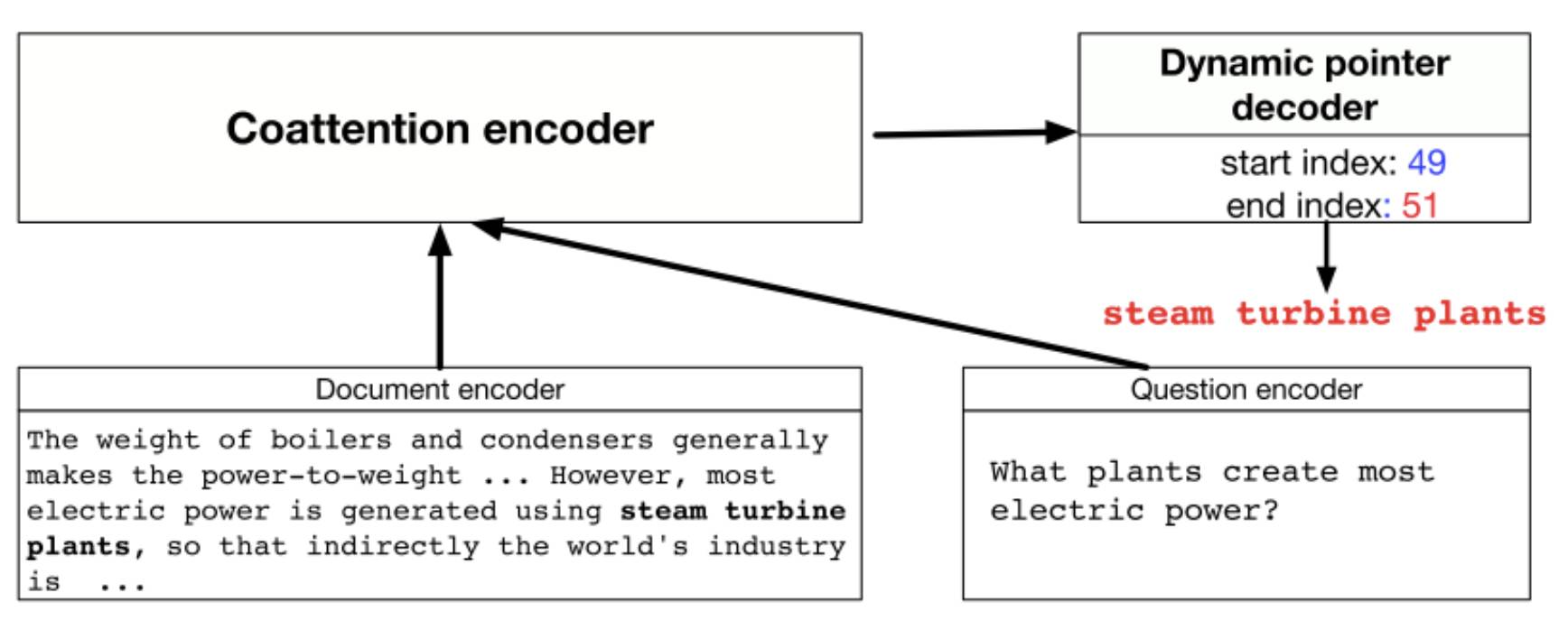
DCN 最大的特点在于 Answer 层,其 Answer 层使用了一种多轮迭代 pointing 机制,每轮迭代都会产生对答案开始和结束位置的预测,并基于这两个预测使用 LSTM 和 Highway Maxout Network 来更新下一轮的答案范围预测。而在 Interaction 层,DCN 使用和 BiDAF 类似的双向注意力机制计算 query-aware 的原文表示。
3.4 Multi-Perspective Matching[7]
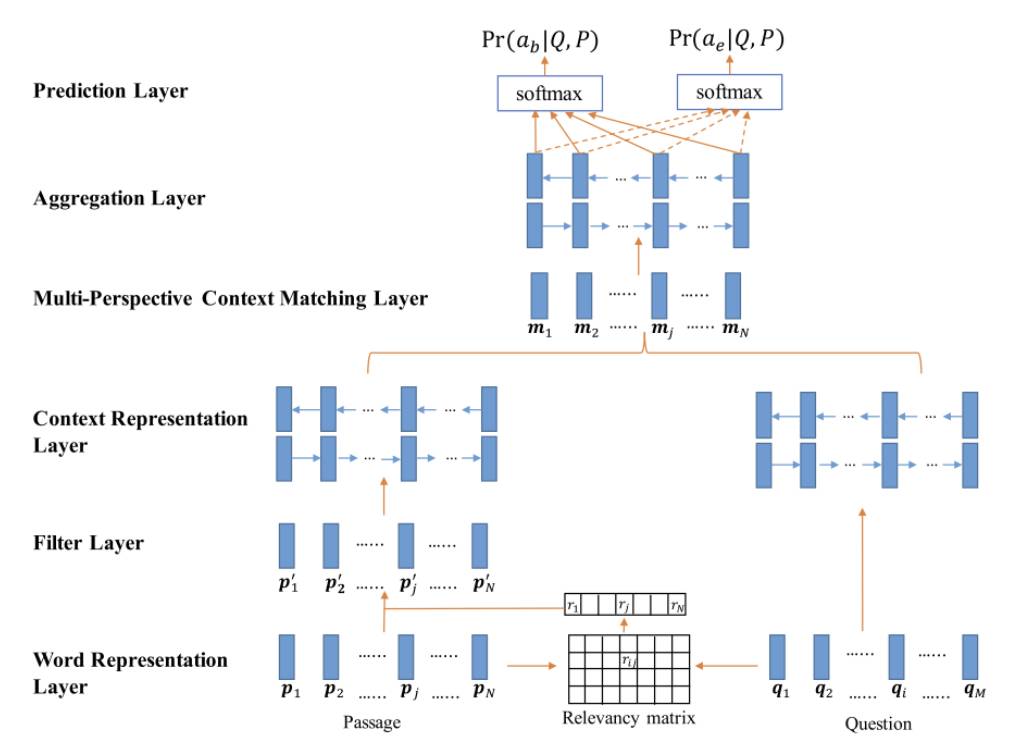
Multi-Perspective Matching 在 Encode 层同样使用 char, word 两个 embedding,只不过 char embedding 使用 LSTM 进行编码。在 Encode 层之前,该模型使用一个过滤操作,作用是过滤掉那些和问题相关度低的原文词。该模型最大的特点在 Interaction 层,该层针对每个原文词使用一种 multi-perspective 的匹配函数计算其和问题的匹配向量,并使用 BiLSTM 来进一步聚合这些匹配向量。匹配的形式包括每个原文词和整个问题的表示匹配,每个原文词和每个问题词匹配后进行最大池化,和每个原文词和每个问题词匹配后进行平均池化。最后在 Answer 层,基于匹配向量聚合表示使用两个前馈网络来预测答案开始和结束位置。
3.5 FastQAExt[8]
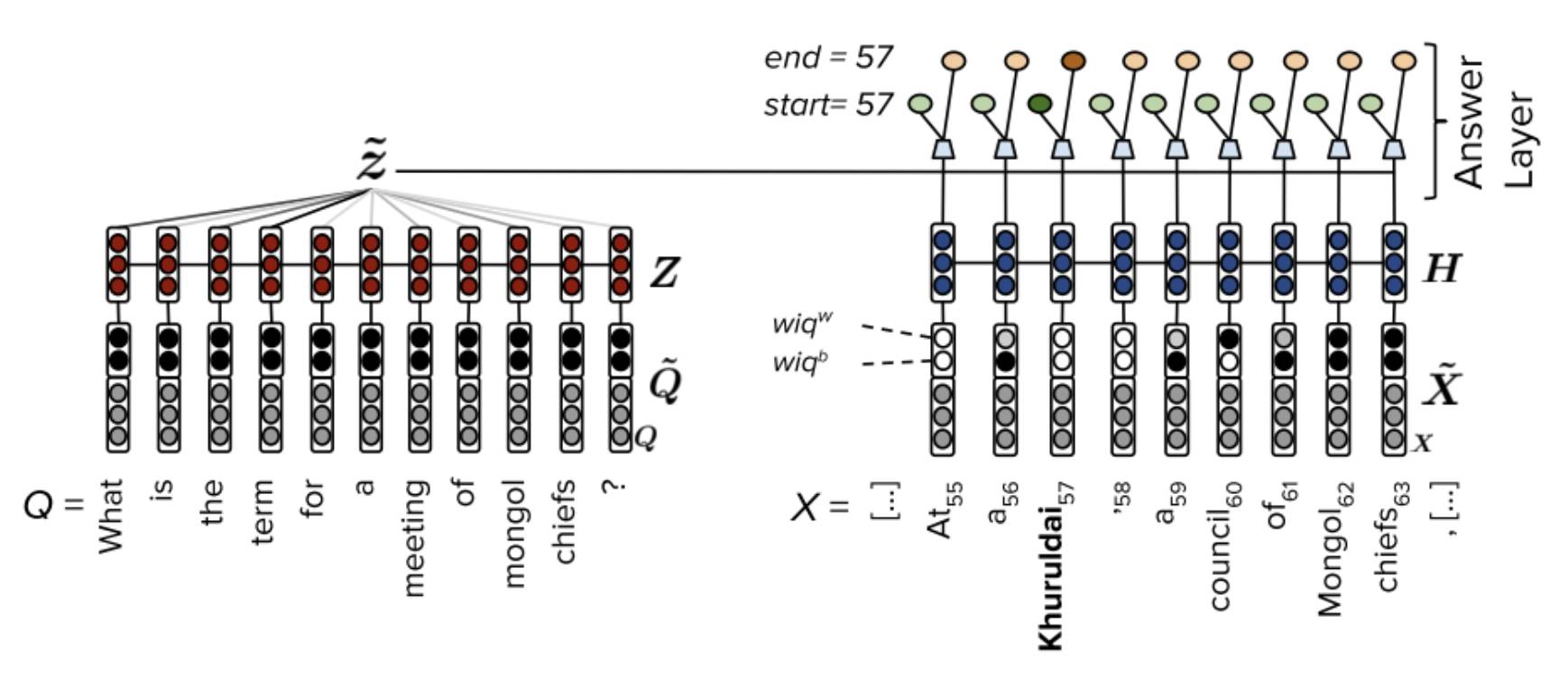
FastQAExt 使用了一种轻量级的架构,其 Embed 层除了 word 和 char 两种 embeeding 作为输入以外,还额外使用了两个特征:1. binary 特征表示原文词是否出现在问题中;2. weighted 特征表示原文词对于问题中所有词的相似度。并且这两个特征同样用在了问题词上。在 Interaction 层,FastQAExt 使用了两种轻量级的信息 fusion 策略:1. Intra-Fusion,即每个原文词和其他原文词计算相似度,并汇总得到原文总表示,接着将该原文词和对应原文总表示输入 Highway Networks 进行聚合,聚合后原文词表示进一步和上下文词表示进行类似的聚合;2. Inter-Fusion,即对每个原文词计算和问题词的相似度,并汇总得到问题总表示,接着将将该原文词和对应问题总表示输入 Highway Networks 进行聚合,得到 query-aware 原文表示。此外,在 Answer 层,FastQAExt 首先计算了一个问题的总表示,接着将 query-aware 原文表示和问题总表示共同输入两个前馈网络产生答案开始和结束位置概率。在确定答案范围时,FastQAExt 使用了 Beam-search。
3.6 jNet[9]
jNet 的 baseline 模型和 BiDAF 类似,其在 Interaction 层除了对每个原文词计算一个对应的问题表示以外,还将 Alignment Matrix 按原文所在维度进行池化(最大池化和平均池化),池化后的值表示原文各词的重要程度,因此基于该值对原文表示进行过滤,剔除不重要的原文词。在 Answer 层,jNet 不仅先预测答案开始位置再预测答案结束位置,还反向地先预测答案结束位置再预测答案开始位置。最后对两方向概率求平均后作为总概率输出。
jNet 的最大创新在于对问题的理解和适应。为了在编码问题表示时考虑句法信息,jNet 使用 TreeLSTM 对问题进行编码,并将编码后表示作为 Interaction 层的输入。为了对不同问题进行适应,jNet 首先使用了问题类型的 embedding,将该 embeeding 作为 Interaction 层输入。另外,jNet 定义了 K 个 cluster 的中心向量,每个 cluster model 了一个特定的问题类型比如"when","where"等,接下来的适应算法分为两步:adapting 和 updating。Adapting 指根据问题总表示和 K 个 cluster 的相似度来更新出一个新的问题表示,并输入 Interaction 层;Updating 层旨在修改 K 个 cluster 的中心以令每个 cluster 可以 model 不同类型的问题。
3.7 Ruminating Reader[10]
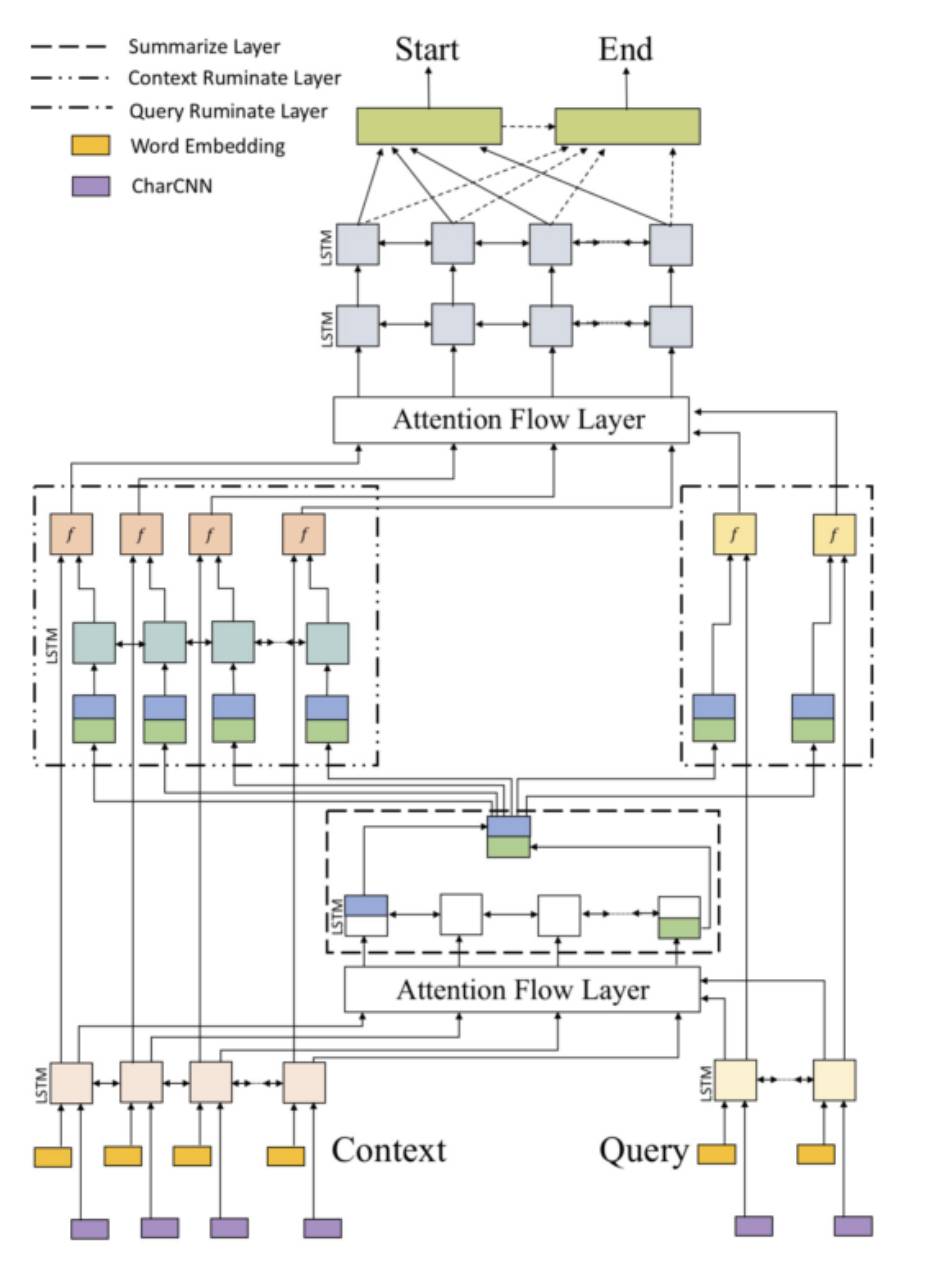
Ruminating Reader 是 BiDAF 的改进和扩展,它将之前的单 Interaction 层扩展为了双 Interaction 层。第一个 Interaction 层和 BiDAF 的 Interaction 层相同,输出 query-aware 的原文表示。query-aware 原文表示经过一个双向 LSTM 编码,其输出的最后一位隐层状态作为 query-aware 原文表示的总结。接着,该总结向量依次与各原文词表示和各问题词表示经过一个 Highway Network 处理,以将总结向量的信息重新融入原文和问题表示当中。最后,基于更新后的原文和问题表示,使用第二个 Interaction 层来捕捉它们之间的交互,并生成新的 query-aware 的原文表示。Ruminating Reader 的 Embed 层,Encode 层和 Answer 层和 BiDAF 相同。
3.8 ReasoNet[11]
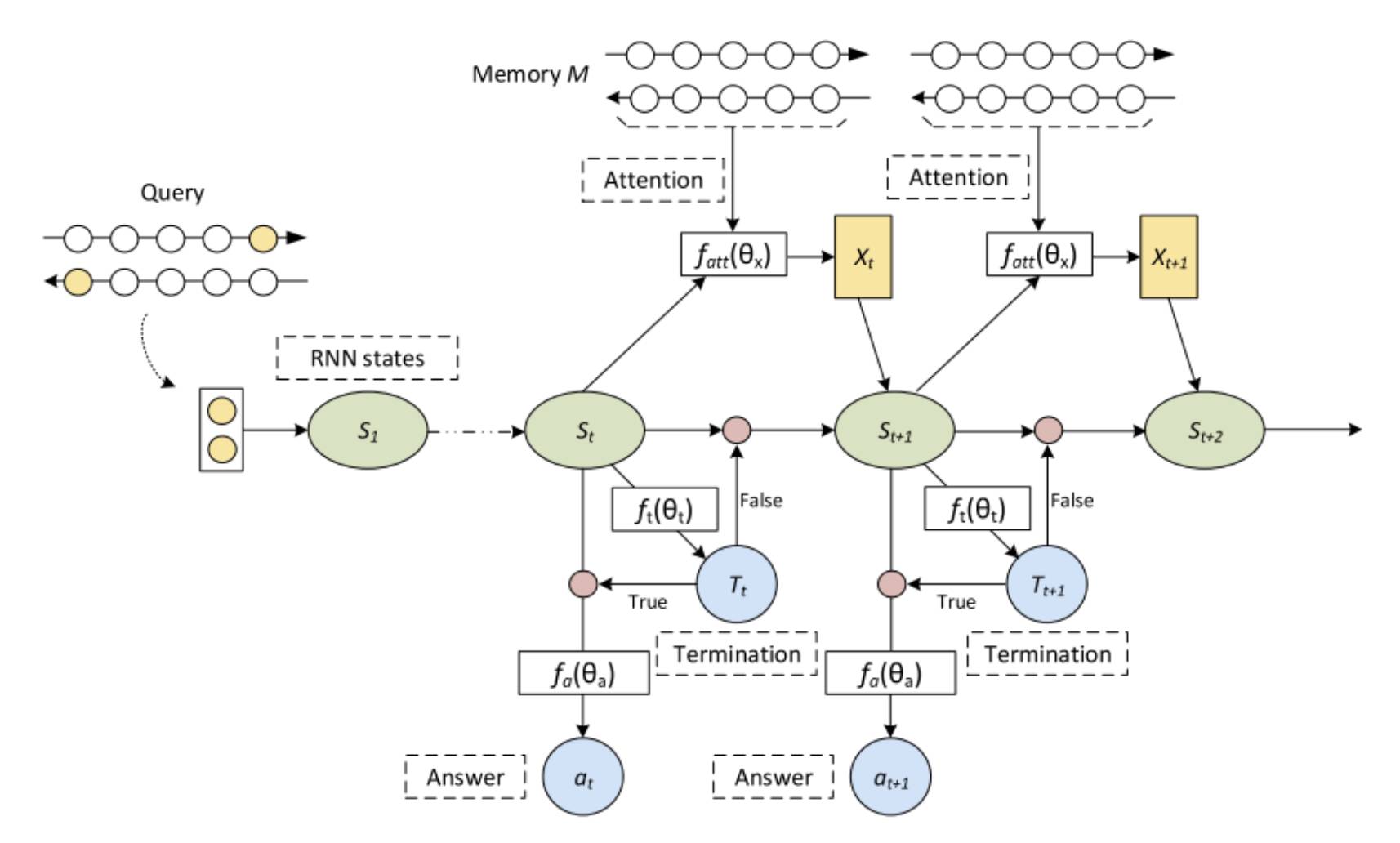
和之前介绍的 Embed-Encode-Interaction-Answer 框架不同,ReasoNet 使用了 Memory Networks 的框架[12]。在使用 BiRNN 编码问题和原文后,问题的最后一位隐层状态初始化为一个中间状态 s,而原文和问题表示作为 Memory。接下来是一个多轮迭代的过程,在每一轮迭代中,中间状态 s 首先经过一个逻辑回归函数来输出一个 binary random variable t,t 为真,那么 ReasoNet 停止,并且用当前中间状态 s 输出到 Answer 模块产生对答案的预测;否则,中间状态 s 会和 Memory(原文和问题)中每一位表示计算注意力,并基于注意力求原文和问题的加权表示 x,x 和 s 共同作为一个 RNN 的输入,产生新的中间状态 s 并进入下一轮迭代。由于出现了 binary random variable,ReasoNet 使用了强化学习的方法进行训练。
3.9 r-net[13]
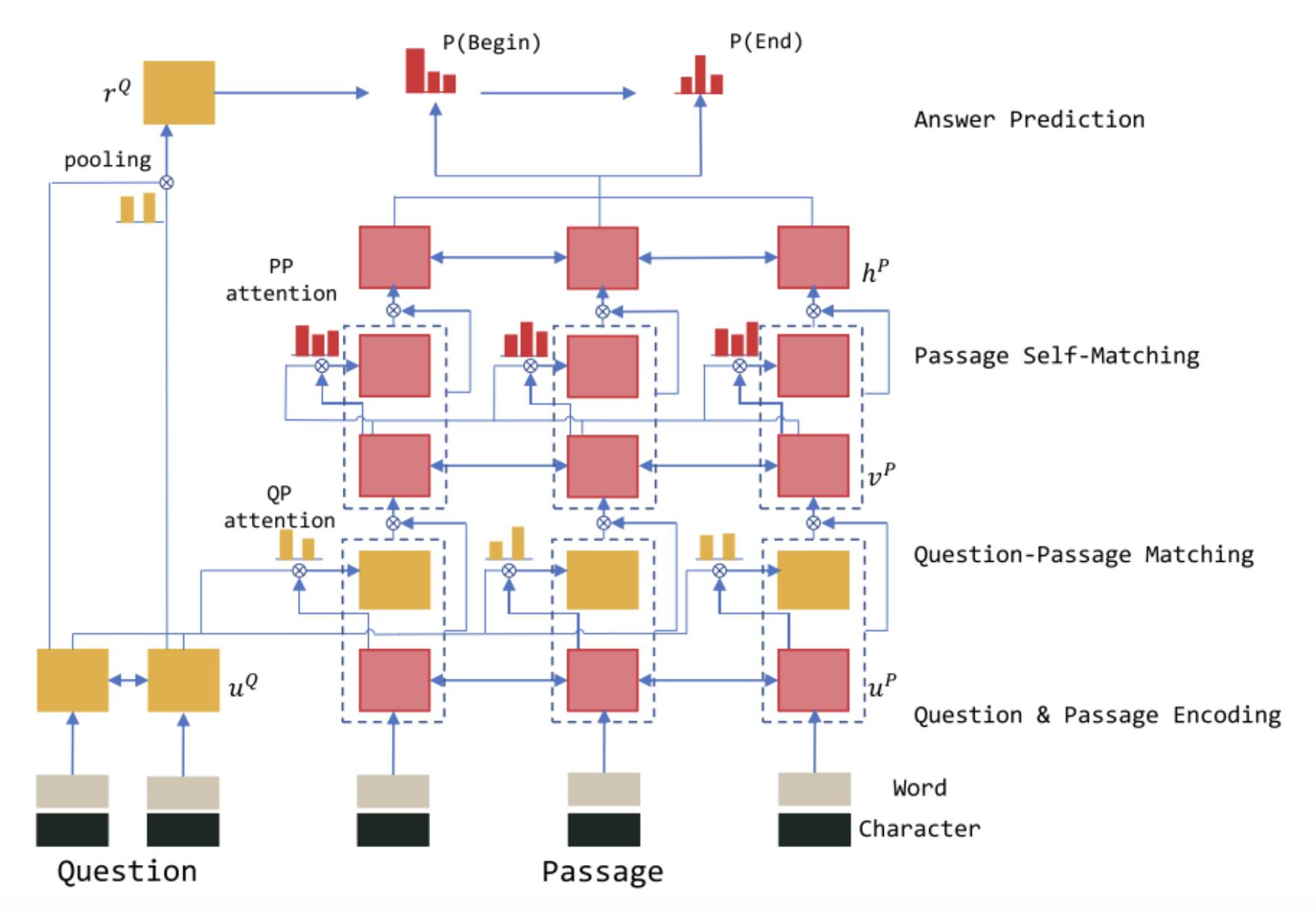
r-net 同样使用了双 Interaction 层架构,其第一 Interaction 层负责捕捉原文和问题之间的交互信息,而第二 Interaction 层负责捕捉原文内部各词之间的交互信息。具体来说,在第一 Interaction 层,r-net 首先使用了类似于 Match-LSTM 的方法,即对原文中每个词,计算其关于问题的注意力分布,并使用该注意力分布汇总问题表示,将原文该词表示和对应问题表示输入 RNN 编码,得到该词的 query-aware 表示。不同的是,在原文词表示和对应问题表示输入 RNN 之前,r-net 使用了一个额外的门来过滤不重要的信息。接着,在第二 Interaction 层,r-net 使用了同样的策略来将 query-aware 表示进一步和自身进行匹配,将回答答案所需的证据和问题信息进行语义上的融合,得到最终的原文表示。
在其他方面,r-net 的 Embed 层同样使用了 word 和 char 两种 embedding 以丰富输入特征。在 Answer 层,r-net 首先使用一个 attention-pooling 的问题向量作为一个 RNN 的初始状态,该 RNN 的状态和最终的原文表示共同输入一个 pointer networks 以产生答案开始概率,接着基于开始概率和原文表示产生另一个 attention-pooling 向量,该向量和 RNN 状态共同经过一次 RNN 更新后得到 RNN 的新状态,并基于新状态来预测答案结束概率。
3.10 Mnemonic Reader[14]
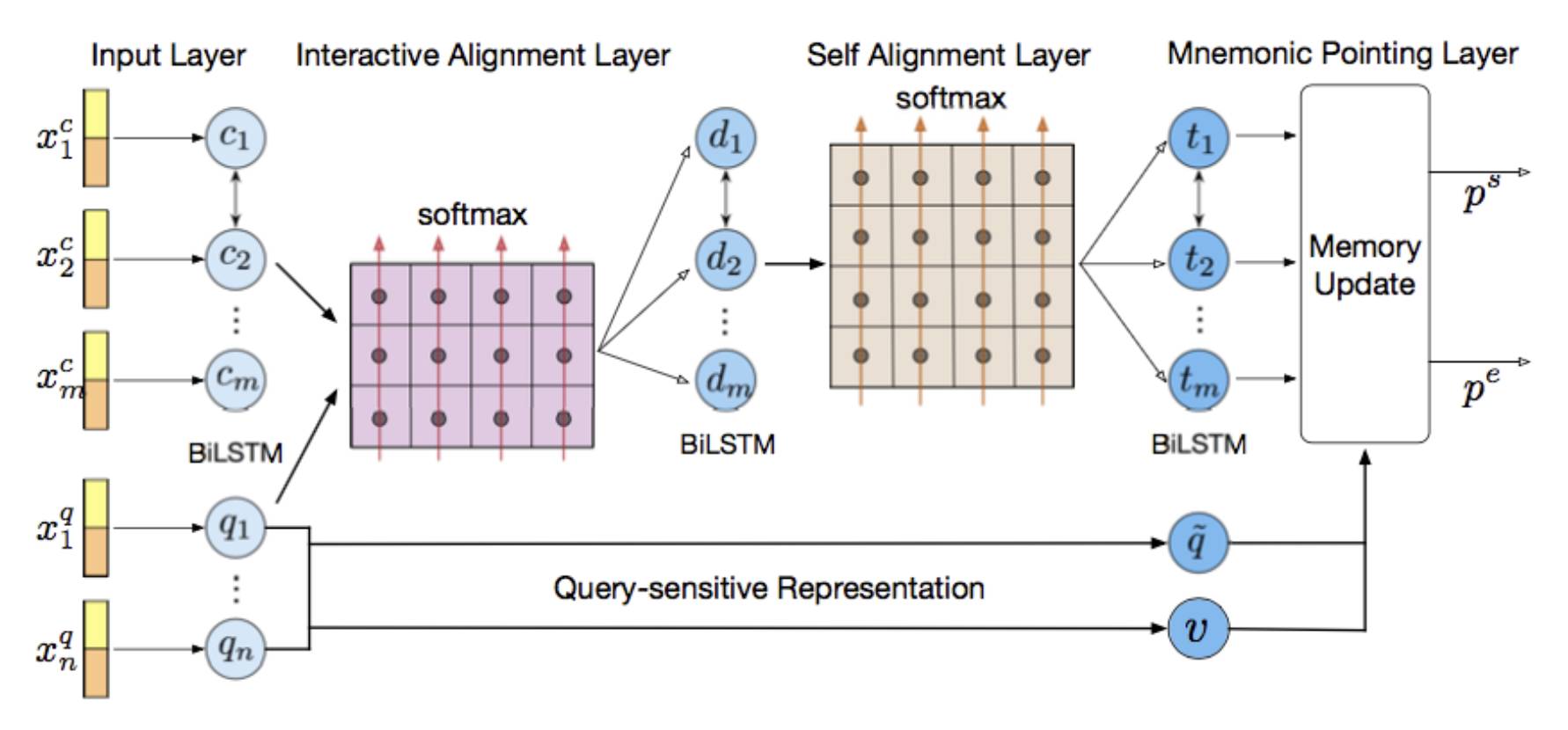
相比于之前的工作,我们的 Mnemonic Reader 同样使用了类似于 r-net 和 Ruminating Reader 的两层 Interaction 层设计。其中第一个 Interaction 层负责捕捉原文和问题之间的交互信息,第二 Interaction 层负责捕捉原文内部的长时依赖信息。不同于 r-net 的是,r-net 使用了单向注意力+门机制来编码这些交互信息,而 Mnemonic Reader 使用了双向注意力机制来编码交互信息,因此能够捕捉更加细粒度的语义信息。在 Answer 层,我们使用对问题敏感的表示方法,具体来说,问题表示分为两种:显式的问题类型 embedding 和隐式的问题向量表示。进一步地,我们使用了 Memory Network[12] 的框架来预测答案范围,将问题表示作为一个可更新的记忆向量,在每次预测答案概率后将候选答案信息更新至记忆向量中。该过程可以持续多轮,因此可以根据之前预测信息来不断修正当前预测,直到产生正确的答案范围。
性能对比
下图是 SQuAD 榜单排名,其中 EM 表示预测答案和真实答案完全匹配,而 F1 用来评测模型的整体性能。可以看到,目前 r-net, ReasoNet 和 Mnemonic Reader 分列 SQuAD 榜单的前三名,但是 ReasoNet 和 Mnemonic Reader 距离第一名 r-net 还是存在一定的差距。值得一提的是,人类在 SQuAD 数据集上的性能分别为 82.3 和 91.2,因此目前最 state-of-the-art 的方法也远未达到人类的水平,让计算机具备人类的阅读理解能力的道路依然漫长。
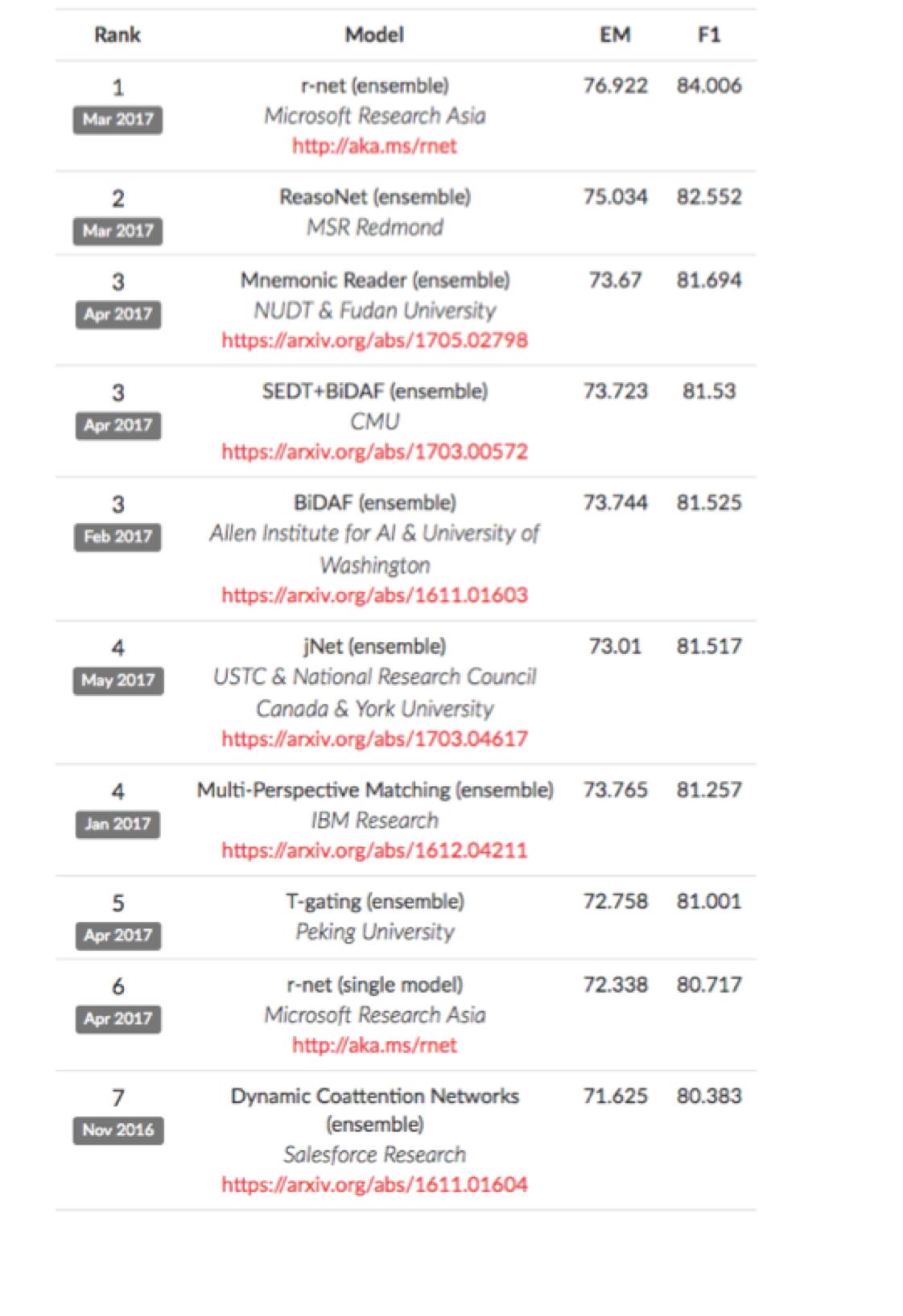
▲ 图2:SQuAD leaderboard上的各模型性能对比(2017年5月11日)
总结
总结以上工作,有以下几点思考:
1) 大规模语料集的构建是推进机器阅读理解发展的重要前提。从 15 年提出的 CNN/DM 完形填空数据集,到近期的 SQuAD 数据集,再到之后的若干新数据集,每一个新数据集都提出了当前方法无法有效解决的新问题,从而促使研究人员不断探索新的模型,促进了该领域的发展。
2) 针对抽取式阅读理解任务,可以看到有如下几个技术创新点:一. 建立在单向或双向注意力机制上的 Interaction 层对于模型理解原文和问题至关重要,而[10],[13]和[14]中更复杂的双 Interaction 层设计无疑要优于之前的单 Interaction 层设计,原因是在问题-原文交互层之上的原文自交互层使得更多的语义信息能在原文中流动,因此在某种程度上部分解决了长文本中存在的长时依赖问题。二. 多轮推理机制如[6],[11]和[14]对于回答复杂问题具备一定帮助,尤其是针对 SQuAD 中的答案不是一个单词而可能是一个短语的情况,多轮推理机制可以不断缩小预测范围,最终确定正确答案位置。三. 对问题敏感的问题表示方法[9],[14]能够更好地 model 各类型问题,并根据问题类型聚焦于原文中的特定单词,比如 when 类问题更加聚焦于原文中的时间信息,而 where 类问题更关注空间信息。
参考文献
[1] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. In Proceedings of EMNLP.
[2] Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, , and Phil Blunsom. 2015. Teaching ma- chines to read and comprehend. In Proceedings of NIPS.
[3] Felix Hill, Antoine Bordes, Sumit Chopra, and Jason Weston. 2016. The goldilocks principle: Reading childrens books with explicit memory representa- tions. In Proceedings of ICLR.
[4] Shuohang Wang and Jing Jiang. 2017. Machine comprehension using match-lstm and answer pointer. In Proceedings of ICLR.
[5] Minjoon Seo, Aniruddha Kembhavi, Ali Farhadi, and Hananneh Hajishirzi. 2017. Bidirectional attention flow for machine comprehension. In Proceedings of ICLR.










