
大纲
-
序
-
数据来源
-
工具介绍
-
数据分析
-
数据概览
-
测定基准
-
分析特征重要性
-
数据展示(可视化)
-
特征工程
-
机器学习预测
-
总结
-
参考
PS:上篇介绍到特征工程,下篇介绍机器学习

-
1912年,当时世界上体积最庞大、内部设施最豪华的客运轮船,有“永不沉没”美誉的泰坦尼克号,在她的处女航中撞冰山沉入大西洋底3700米处,船上1500多人丧生。
-
1985年,美国和法国联合搜索队发现泰坦尼克号残骸。
-
1997年,詹姆斯·卡梅隆执导美国电影《泰坦尼克号》,将整个惊心动魄的过程首次以电影的方式还原。
-
2012年,《泰坦尼克号》3D版在中国内地重映,再次唤起人们对艘富有传奇色彩的巨轮的缅怀。
-
2017年5月,有科学家表示,细菌正在蚕食泰坦尼克号沉船残骸。据最近的估计,到2030年,这艘船可能会迎来它的末日,彻底消失。
假设如果真有穿越这回事,突然哪一天你的灵魂穿越到了正在航行的泰坦尼克号上的某个乘客身上,你发现你身处某层客舱内,被你的同伴称为Mr/Miss,而你只有现代的记忆。突然一声巨响同时船身剧烈摇晃,人们惊慌不知所措,那么此时此刻的你,有多大机率可以活下来?
接下来,我会通过数据分析,告诉你有哪些特征会影响你的存活机率。

著名的数据分析竞赛网站Kaggle上,举行了很多数据分析比赛,其中比较著名的就有 泰坦尼克号乘客生还预测 。
Kaggle提供的数据集中,共有1309名乘客数据,其中891是已知存活情况,剩下418则是需要进行分析预测的。
提供的数据特征如下:
PassengerId: 乘客编号
Survived :存活情况(存活:1 ; 死亡:0)
Pclass : 客舱等级
Name : 乘客姓名
Sex : 性别
Age : 年龄
SibSp : 同乘的兄弟姐妹/配偶数
Parch : 同乘的父母/小孩数
Ticket : 船票编号
Fare : 船票价格
Cabin :客舱号
Embarked : 登船港口
PassengerId 是数据唯一序号;Survived 是存活情况,为预测标记特征;剩下的10个是原始特征数据。
下面我将尝试分析所得原始数据,通过构建特征工程,建模预测乘客的生存情况。

Carpenters Tools used on Titanic.jpg
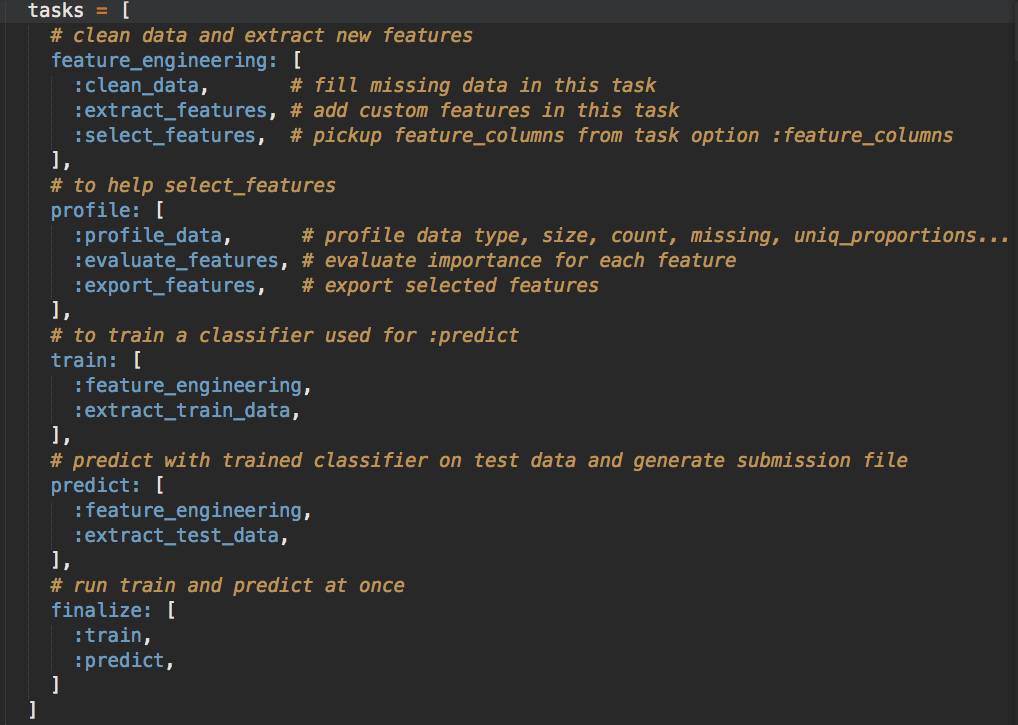
以下数据分析过程中,我使用的是我自己用Ruby语言开发的一套简单的可通用的数据分析工具,集成了数据分析报告、数据可视化、特征工程构建、机器学习分类模型训练、数据导出等。
先看下有哪些命令可以使用:
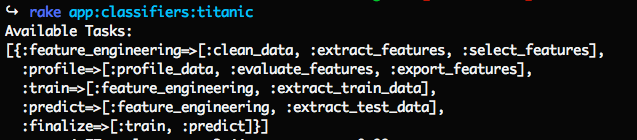
每个任务的用途和前置子任务用途描述如下:
每个任务都可以单独执行,具体用法会在后面的分析过程中逐个演示。
说到数据挖掘,是把散乱数据转换成「有价值」信息的过程,数据是可以是数字或者文本内容甚至图像,而信息是有语义的、人脑可理解的报告、图表。
数据分析的结果,就是把数字转化成人类可理解的信息。
数据概览
先看一眼已有的数据概括。
第一步,配置好数据路径:

task-config-dataset.png
第二步,执行数据分析任务 profile_data 输出数据摘要信息:
rake app:classifiers:titanic:profile_data
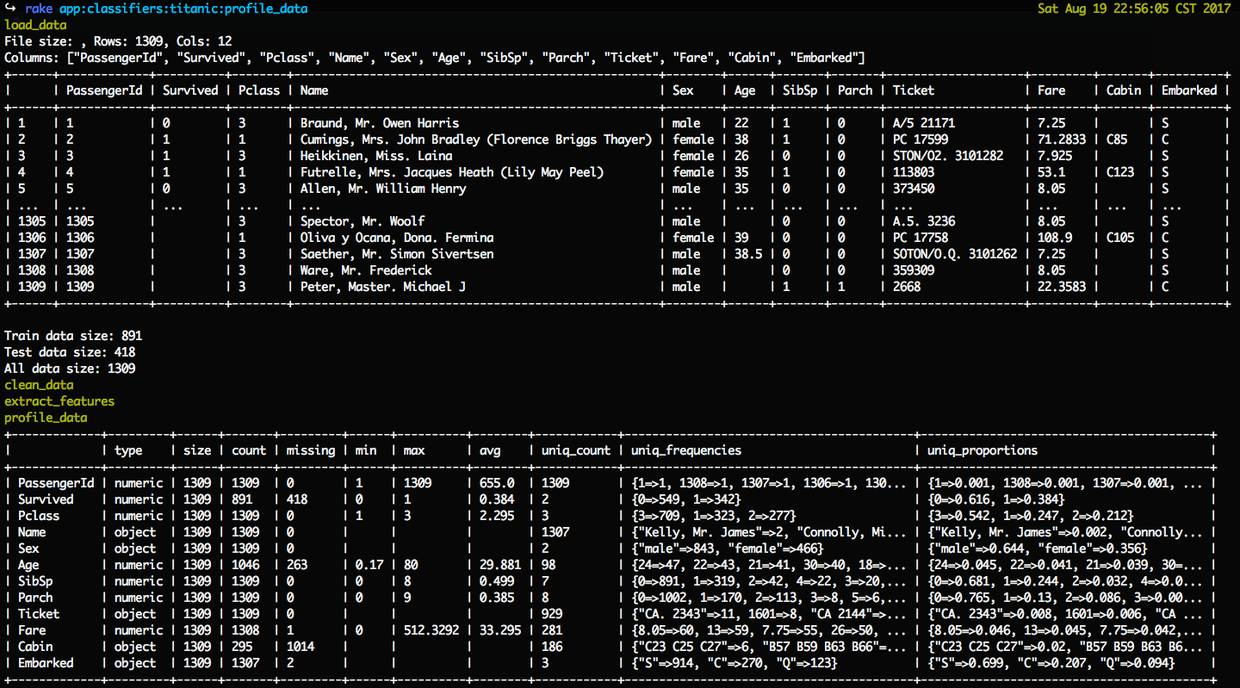
rake_app_classifiers_titanic_profile_data.png
得到基本的数据信息:
Rows: 1309, Cols: 12,Columns: ["PassengerId", "Survived", "Pclass", "Name", "Sex", "Age", "SibSp", "Parch", "Ticket", "Fare", "Cabin", "Embarked"]
(注:uniq_proportions 是数据唯一值数量的占比值,下面描述时直接x100,如 0.616 描述为 61.6%,方便理解)
从输出统计中可以得出以下信息:
-
Survived 中549条是0(死亡),342条是1(生还);占比(uniq_proportions)分别是61.6%和38.4,死亡率很高。有418条missing(表示没有值),是要预测的数据量。
-
Pclass 的unit_count (唯一数量)是3,通过uniq_frequencies 看出分为1,2,3 个类别,对应头等舱、二等舱和三等舱),其中3占了过半为54.2%
-
有几个特征有缺失数据(missing 不为0的),Age 为263,Fare 为1,Cabin 为1014,Embarked 为2
-
Sex 乘客性别分布中男性占 64.4%,女性 35.6%(人多不一定是好事,后面分析中发现男性死亡很高)
-
Age 乘客年龄分布中最小0.17(婴儿),最大是80岁,平均为29.881
-
Ticket 总数是1309,而唯一数是929,说明有一票多人使用情况(这个信息在后面的特征提取中有用)
-
Fare 最高是512.3292,而平均是33.295,贫富分化差距不小(同样,这个信息在后面的特征提取中会有用)
-
Embarked 有3组为"S"、"Q"、"C",其中"S"占69.9%,我猜这可能是启航的港口,登船港口跟存活率有什么关系这是个疑问
测定基准-没事跑个分
先跑个分看看,执行训练任务train:
rake app:classifiers:titanic:train summary=n
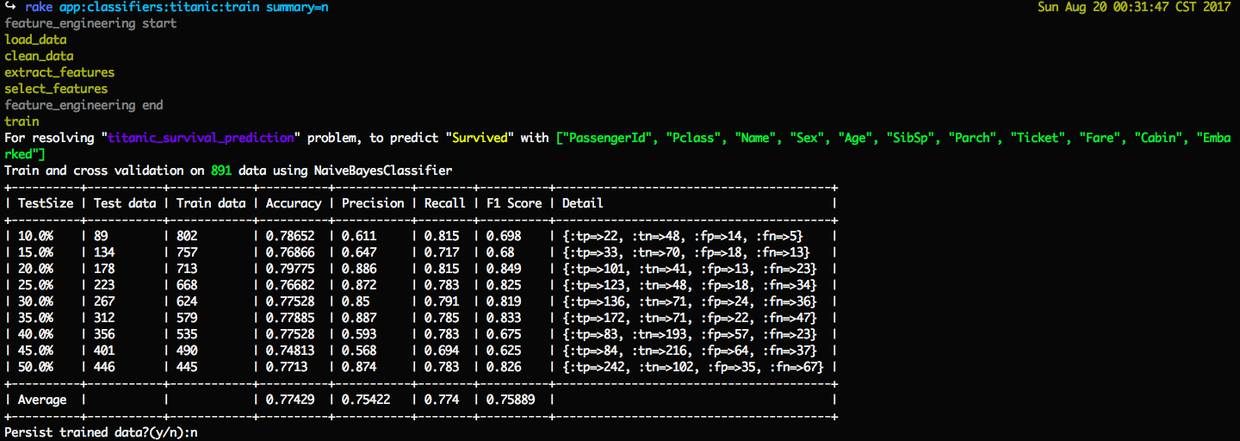
rake_app_classifiers_titanic_train.png
在什么数据都没改动的情况下,使用所有特征数据来跑训练任务(任务没有配置时,默认使用朴素贝叶斯分类)和CV(Cross Validation,交叉验证),得到平均的 F1 Score 是 0.75889,意味这个是我们的模型的最低基准,最终构建出的模型分数要高于这个之上才是可靠的模型。
分析特征重要性
这么多特征,有哪些特征是跟存活率比较相关的?
可以使用这个数据分析任务,再做进一步分析:使用任务参数 label_column=Survived 来指明哪个是要预测的标记特征,再执行一次数据分析任务:
rake app:classifiers:titanic:profile_data label_column=Survived
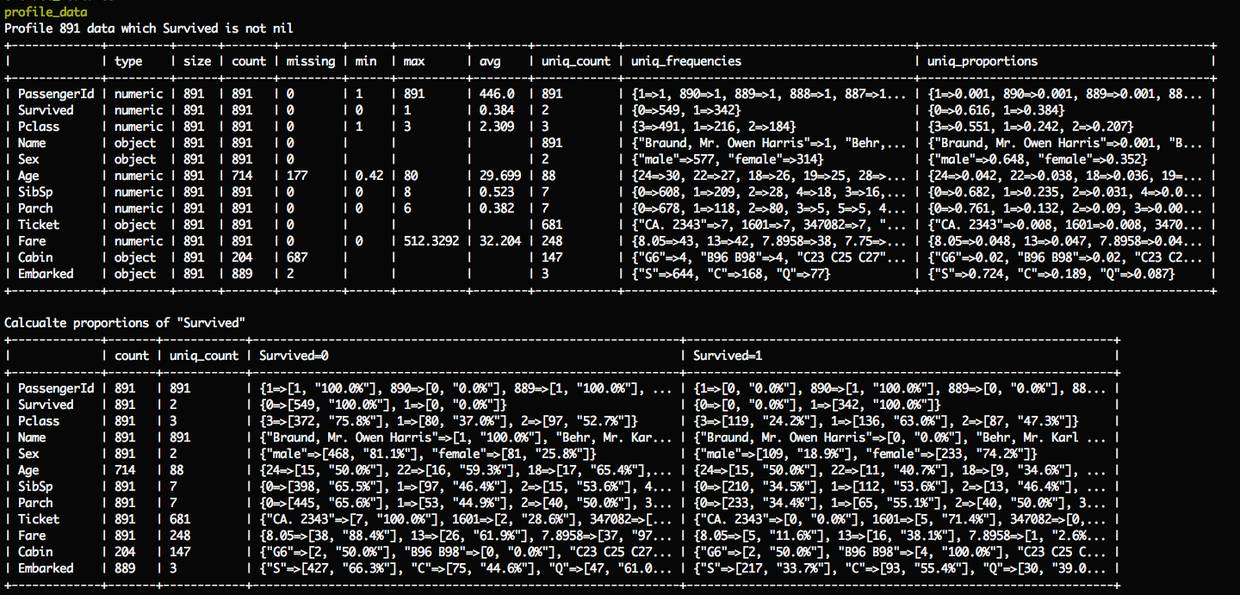
rake app:classifiers:titanic:profile_data label_column=Survived
这次的输出就有些差异,可以看到是针对 Survived 有值的数据来统计:
Profile 891 data which Survived is not nil
还多了特征分布占比统计:
Calcualte proportions of "Survived"
从而能知道各个特征值与标签特征Survived的对比,得出符合该特征时的“生存率”。
例如 Pclass 的统计:
+-------------+-------+------------+--------------------------------------------------------------+--------------------------------------------------------------+
| | count | uniq_count | Survived=0 | Survived=1 |
+-------------+-------+------------+--------------------------------------------------------------+--------------------------------------------------------------+
| Pclass | 891 | 3 | {3=>[372, "75.8%"], 1=>[80, "37.0%"], 2=>[97, "52.7%"]} | {3=>[119, "24.2%"], 1=>[136, "63.0%"], 2=>[87, "47.3%"]} |
Pclass=3(Survived=0)有372条,占75.8%,意思是三等舱的乘客中死亡率是75.8%;
Pclass=1(Survived=1)有136条,占63.0%,意味头等舱的乘客中有63.0%是存活了下来。
以此类推,性别数据中:
+-------------+-------+------------+--------------------------------------------------------------+--------------------------------------------------------------+
| | count | uniq_count | Survived=0 | Survived=1 |
+-------------+-------+------------+--------------------------------------------------------------+--------------------------------------------------------------+
| Sex | 891 | 2 | {"male"=>[468, "81.1%"], "female"=>[81, "25.8%"]} | {"male"=>[109, "18.9%"], "female"=>[233, "74.2%"]} |
不用建模光是根据这2组数据就已经可以想象到,如果当时是女性,并入驻在头等舱,存活下来的机率是很高的;反之,如果是男性,又是入驻在三等舱区的,差不多5个人中只能活1个。。。
这些分类结果比较少、存活率倾斜比较明显的,显然是比较重要的特征。那么其他特征值分布比较离散的,对最终的存活率影响是怎样的呢?
在这里可以先使用 evaluate_features (特征评估)任务来对每个特征进行一次初步评估,原理是单独使用每个特征来自动训练(默认使用了朴素贝叶斯做分类算法)并进行Cross Validation(交叉验证),得出Accuracy(准确率)、Precision(精确率)、Recall(召回值),用来评估该特征对预测标记特征的重要程度。
执行特征评估任务,并使用选项label_column指明Survived 为标记特征:
rake app:classifiers:titanic:evaluate_features label_column=Survived
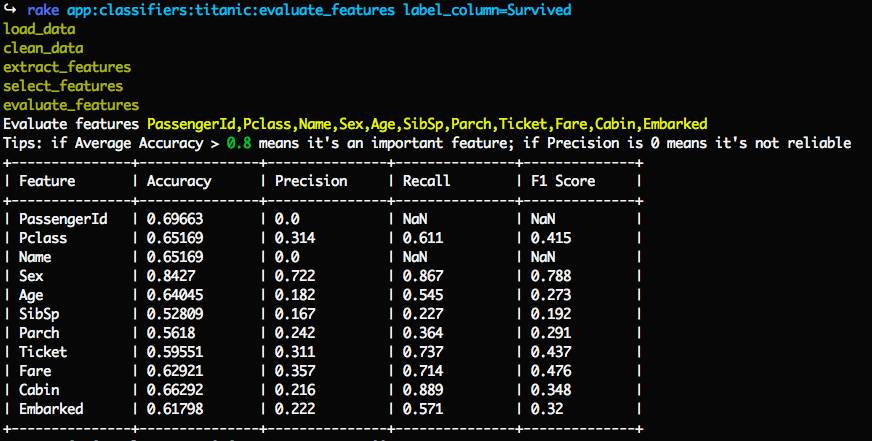
rake_app_classifiers_titanic_evaluate_features_label_column_survived.png
留意提示:
Tips: if Average Accuracy > 0.8 means it's an important feature; if Precision is 0 means it's not reliable
从分析结果中可以看到:
-
Sex 的Accuracy 大于0.8,属于比较重要的特征。
-
PassengerId 以及 Name 的 Precision 是 0,表示特征值太离散,不适合用来做预测的特征,而事实上这2个特征的值都是唯一不重复的(Name只有2条重复),确实不适合做为分类特征。
-
Age、SibSp、Parch、Cabin、和Embarked 的 Precision 值都偏低(< 0.3),说明这个几项相关性不足(有部分是受到缺失值得影响)。
数据展示(可视化)
人是视觉生物,天生对图像信息比数字、文字信息更敏感,为了能更直观的表达统计数据所体现的意义,可将数据以各种图表的形式来可做视化展示,辅助对数据的理解。
我编写的这套工具中集成了一些图表的Web UI,可以直接使用数据分析任务的输出报表来生成图表,可以查看每一个特征的统计。
例如性别数量统计:
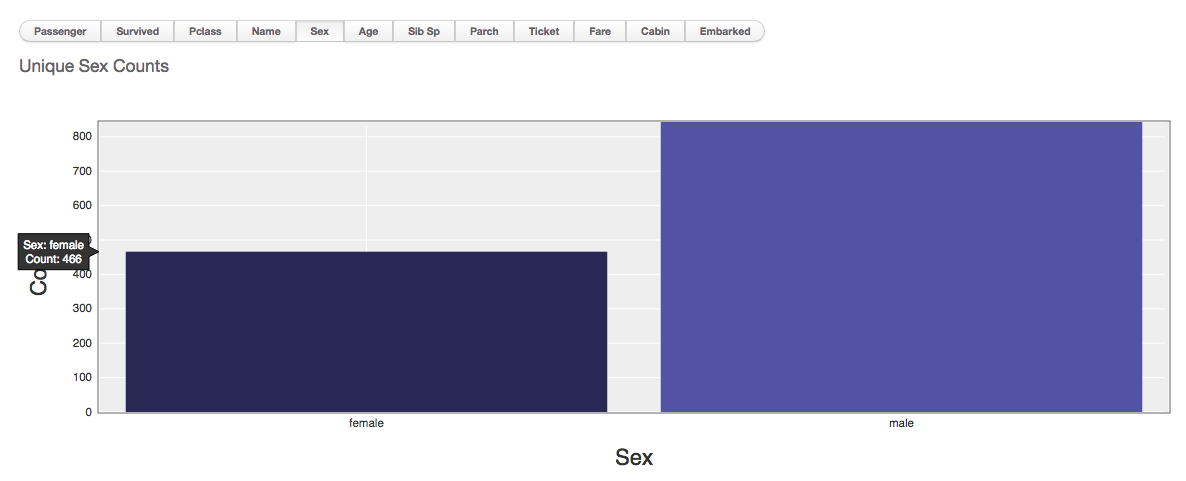
性别统计
男多女少!那人多力量就大吗?让数据回答,加入存活状态对比看看:
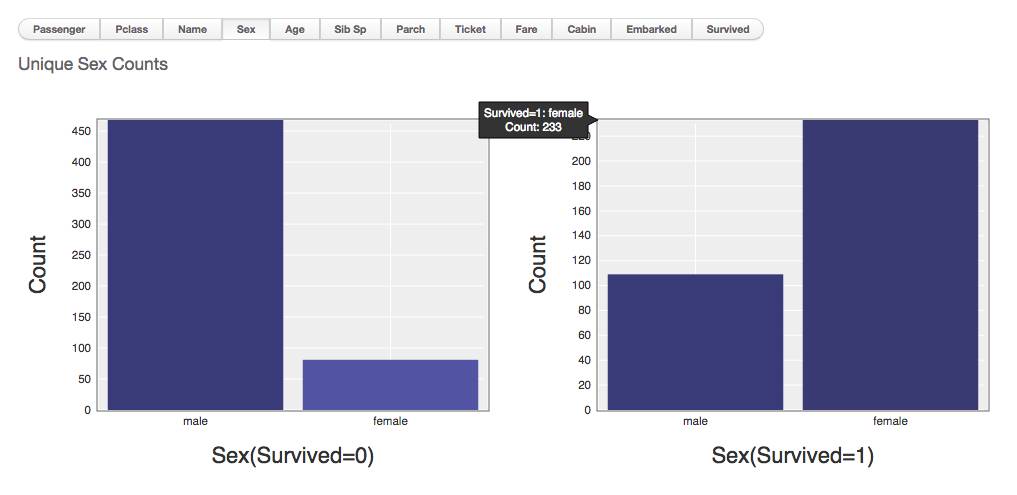
性别与存活状态对比统计
很明显,不用看数字都看得明白:女性存活率更高!
乘客的年龄与人数的分布统计图:
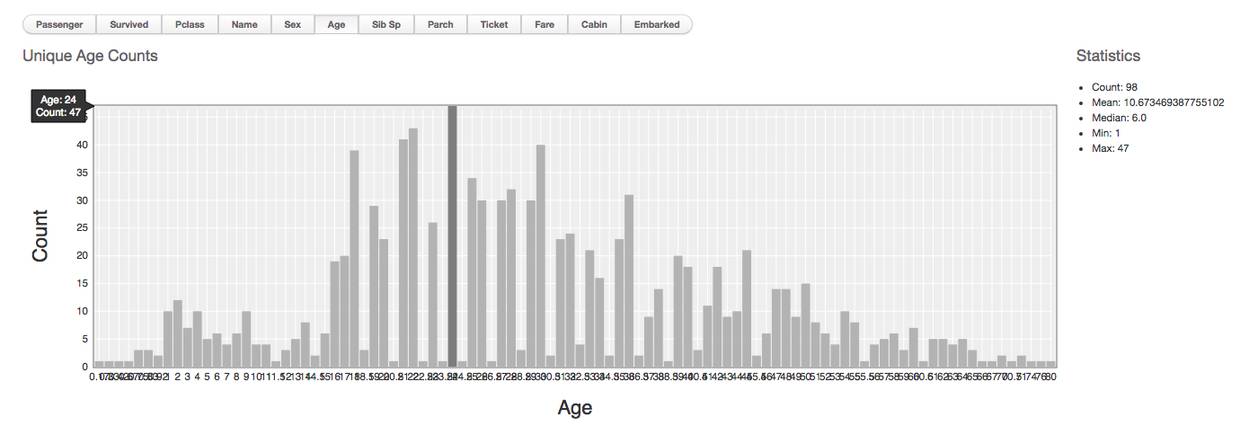
乘客的年龄与人数的分布统计图
从图中可看出在乘客中,人数最多的是24岁、有47人,整体呈现出中间层年龄段人数居多,人群以年轻、中年人为主。年轻力壮就会更有利吗?未必!
在接下来的特征工程的后半段中会有更多的图表展示,这里先不展开了。

什么是特征工程?
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。而特征工程的目的是最大限度地从原始数据中提取特征以供算法和模型使用。顾名思义,特征工程其实就是一项工程活动,它是能够将数据像艺术一般展现的技术。这样说的原因是好的特征工程很好的混合了专业领域知识、直觉和基本的数学能力。
数据清洗
通过前面的数据分析知道有一些数据有缺失,需要先填充。
这里可以使用console=y 选项来以交互模式来执行数据清洗任务clean_data:
rake app:classifiers:titanic:clean_data console=y
填补 Fare
看下 Fare 数据的缺失情况:

只有一条缺失记录,而这个乘客的Ticket只有他一个人在使用,无法通过查找相同票号的价格来填补。
船票的价格显然是跟 Pclass (客舱等级)及 Cabin(客舱号)有关的,因此使用具有相同Pclass和Cabin的中位数来填补:
df.where(df['Fare'].not_eq(nil) & df['Pclass'].eq(3) & df['Cabin'].eq(nil) )['Fare'].median
=> 8.05
填补 Age
df['Age'].missing
=> 263
发现所有 Name 中有“Mr.” “Mrs.” 等头衔字眼,因此提取出来可以作为一个辅助特征Title,然后再使用具有相同Title和Sex的中位数来填补。
填补 Cabin
Cabin 缺失的比较多,但发现相同Cabin的Ticket也相同,因此可以反推具有相同Ticket的乘客也会住在同一个Cabin内,因此可以找出具有相同Ticket但Cabin不为空的乘客数据来填补:
df['Cabin'].missing
=> 1014
same_cabins = 0
df.where(df['Cabin'].eq(nil)).each_row_with_index do |row, idx|
same_cabin = df.where( df['Cabin'].not_eq(nil) & df['Ticket'].eq(row['Ticket']) )
if same_cabin.size != 0
same_cabins += 1
end
end
same_cabins
# => 16
发现这类数据也不多,只有16条。
其他的不确定性太多放弃填补。Cabin 数据虽然不完整,但还可以用来提取新的特征,下文有说明。
填补 Embarked
+-----+-------------+----------+--------+-------------------------------------------+--------+-----+-------+-------+--------+------+-------+----------+
| | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
+-----+-------------+----------+--------+-------------------------------------------+--------+-----+-------+-------+--------+------+-------+----------+
| 62 | 62 | 1 | 1 | Icard, Miss. Amelie | female | 38 | 0 | 0 | 113572 | 80 | B28 | |
| 830 | 830 | 1 | 1 | Stone, Mrs. George Nelson (Martha Evelyn) | female | 62 | 0 | 0 | 113572 | 80 | B28 | |
+-----+-------------+----------+--------+-------------------------------------------+--------+-----+-------+-------+--------+------+-------+----------+
Embarked 的缺失只有2条,观察数据后发现是2位女士,共用同一张Ticket “113572”,住在同一个Cabin “B28”,在同一个Pclass 1,因此推断她们可能是认识的,因此也非常有可能是一起出行并在同一个港口登船,所以不用分别处理。另外我按常理推断相同港口出售的票是相连的,可取Ticket前4位数字相同的表示是相同港口,最后找出有相同Pclass和相似Ticket中 Embarked 的众数:
df.filter_rows { |p| p['Ticket'].to_s.first(4) == '113572'.first(4) && p['Pclass'] == 1 } ['Embarked'].frequencies.max_index
=> #<:vector>
C 7
得出是 “C”。
完成数据清洗后,查看现有的数据概况:
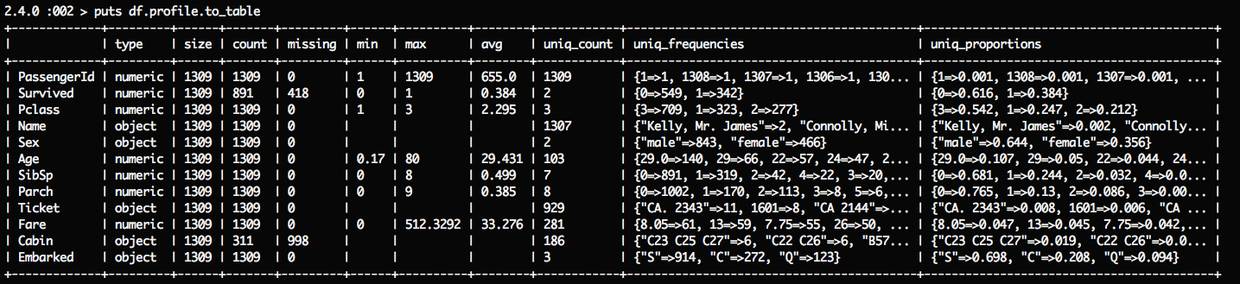
可以看到只有 Cabin 还有998条是缺失的了,至此数据清洗完毕,接下来做新特征提取。
提取新特征

问题:应该提取出哪些特征?
面对这样的群体灾难事件场景中,有什么因素会影响到个人生存机会呢?是个人的年龄、体力、社会身份、财富、拥有的权力?是因为你是女性、带着孩子的母亲?小孩和老人行动缓慢会很不利?人缘好朋友多会更有优势?拖家带口是累赘还是助力,还是独善其身更有利?亦或是你当时所处的位置导致了最后的结局?
设想
结合已有的数据,我觉得有如下这些因素可以尝试:
-
Sex(性别):性别是人类个体之间最大的生理特征区别,影响到体力、社交地位,在群体中往往也受到优待(女士优先),而且前面的特征评估已说明这个特征很重要
-
AgeLevel(年龄层):年龄影响到体力、社交地位,年纪小的、或者年纪大的在群体中往往也受到优待(尊老爱幼);这里可以分组为(child, young, midlife, aged),基于 Age 提取
-
SocialTitle(社交头衔):在群体活动中,不同身份显然也会影响到群体决策 ;这里分组为 Mrs, Miss, Mr and Master,基于 Name 提取
-
IncomeClass(收入水平): 收入决定了所买的船票类型,也就决定了客舱所在的位置,以及社交地位;分组为 no-income, lower-income, middle-income, upper-income), 可基于 Fare 和 Pclass 提取
-
SocialClass(社交地位):一个人可以没有很多钱,但他从事的职业、贵族身份在群体活动中是有影响力的;分为 lower-class, middle-class, upper-class,基于Title, IncomeClass 提取
-
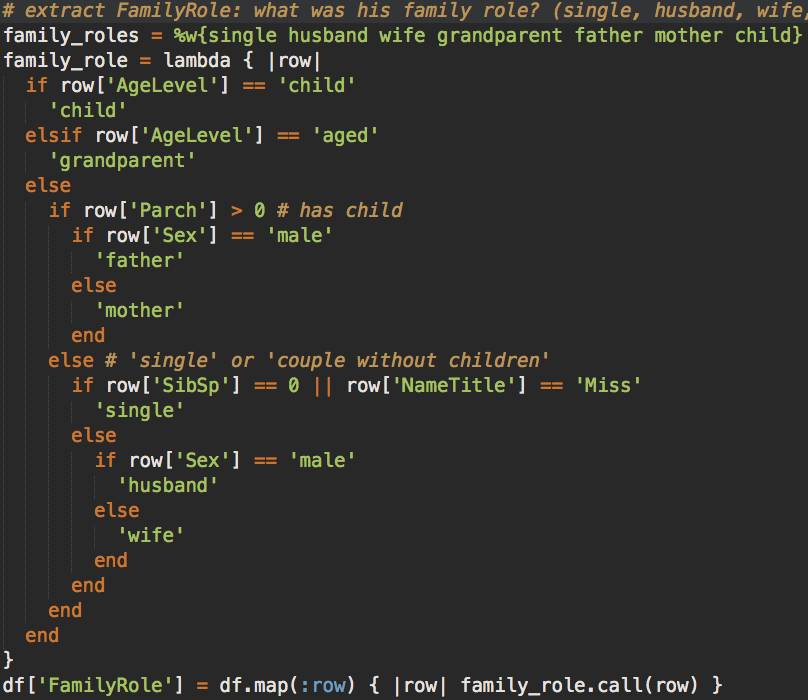
FamilyRole(家庭角色):如果你是位父亲,你所肩负的责任能让你愿意作出巨大牺牲;一位母亲在灾难面前为了保护孩子往往迸发超出常人的生存欲望;可分组为grandparent, couple, father, mother, child;可基于Sex,AgeLevel,SibSp,Parch
-
CabinArea(舱位所在区域):显然这会影响到逃生的时机,基于Cabin
-
Mates(伙伴数量):这次航行中的同行人数(有多少人使用相同的Ticket)
-
FamilySize(同船的家庭成员数量): 家人在一起互助肯定比一群陌生人有更多的信任和生存机会;基于SibSp和Parch
-
TravelAlone(是否孤身上路):Mates + FamilySize,无论是朋友还是家人,多一个熟人在身边也许就比别人多一份生存机率
实现

提取Sex(性别)
使用原有数据,不需要改动。
提取 AgeLevel(年龄层)
按如下年龄划分:
age_level = lambda { |age, default="unknown"|
{
0..14.5 => 'child', # 少年0-14
15..35.5 => 'young', # 青年15-35
36..60.5 => 'midlife', # 中年36-60
61..90.5 => 'aged', # 老年61-90
}.select { |range| range === age }.values[0] || default
}
df['AgeLevel'] = df['Age'].map { |age| age_level.call(age) }
提取 SocialTitle(社交头衔)
# extract "Title" from "Name"
df['NameTitle'] = df['Name'].map { |name| name.match(/, ([^.]+)./)[1] }
# extract SocialTitle: what was his social title?
social_title = lambda { |title, sex|
title = title.sub("the ", "")
title = 'Mrs' if title == 'Dr' && sex == 'female' # a special case
{
%w{Mr Don Major Capt Jonkheer Rev Col Dr Sir}=> 'Mr',
%w{Miss Mlle Ms Lady Dona} => 'Miss',
%w{Mrs Countess Mme} => 'Mrs',
%w{Master} => 'Master',
}.select { |_| _.include? title }.values[0]
}
df['SocialTitle'] = df['NameTitle', 'Sex'].map(:row) { |row| social_title.call(row["NameTitle"], row["Sex"]) }
这样把一些数量较少的NameTitle都归类起来,另外提取这个特征时,发现有一条特殊记录,有一个Dr是女性,因此做了特殊处理:
title = 'Mrs' if title == 'Dr' && sex == 'female' # a special case
提取 IncomeClass(收入水平)
考虑到游船还是需要一定的经济收入,我将上层阶级、中产阶级、下层阶级 按照 1:2:7 的比例(下层等级的数量是上层的数量之和),获取对应的唯一票价的分位数,作为分层的水平线:
uniq_fare = df['Fare'].uniq
income_classes = {"no-income": 0, "lower-income": uniq_fare.percentile(100-70), "middle-income": uniq_fare.percentile(100-20), "upper-income": uniq_fare.percentile(100-10) }.stringify_keys
# => {"no-income"=>0, "lower-income"=>10.5, "middle-income"=>57.75, "upper-income"=>82.2667}
得出的数据统计如下:
df['IncomeClass'].uniq_frequencies
# => {"middle-income"=>587, "lower-income"=>513, "upper-income"=>192, "no-income"=>17}
df['IncomeClass'].uniq_proportions
# => {"middle-income"=>0.448, "lower-income"=>0.392, "upper-income"=>0.147, "no-income"=>0.013}
参考资料:
提取 SocialClass(社交地位)
社交地位中“名”与”利“起主要作用(别不服气,现实社会的游戏规则就是这样)。乘客数据中的头衔信息很重要,因此可以把有贵族头衔以及IncomeClass是高级的都视作upper-class;中产收入的归为middle-class;其他的就是lower-class。
代码简单不展示了,只是有些英国的贵族头衔信息我不熟悉需要查下参考资料。
参考资料:
-
wiki/List_of_titles
-
wiki/Honorific
提取 FamilyRole(家庭角色)
这里判别规则比较复杂,看图理解
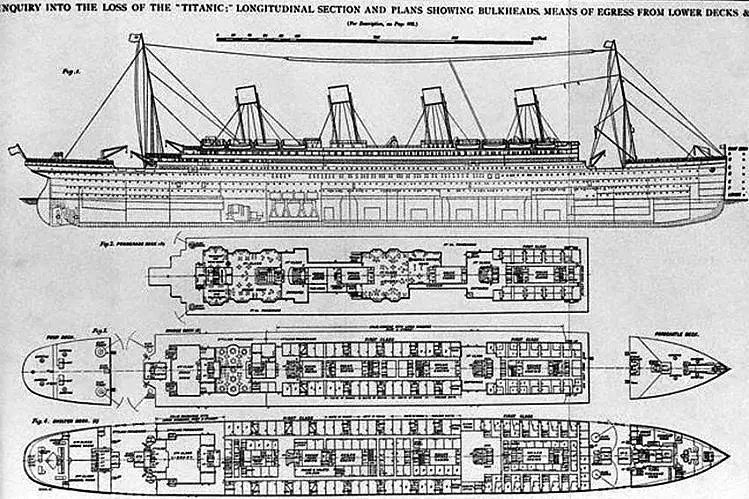
提取 CabinArea(舱位所在区域)
这里要先提取一个Deck(甲板)特征,这个是根据Cabin的首位字母得出的,可以分为A、B、C、D、E、F、G和T,未知的则标记为N/A。
# extract "Deck" from "Cabin"
df['Deck'] = df['Cabin'].map { |cabin| cabin && cabin[0] || 'N/A' }
可以参考泰坦尼克号的剖面图:
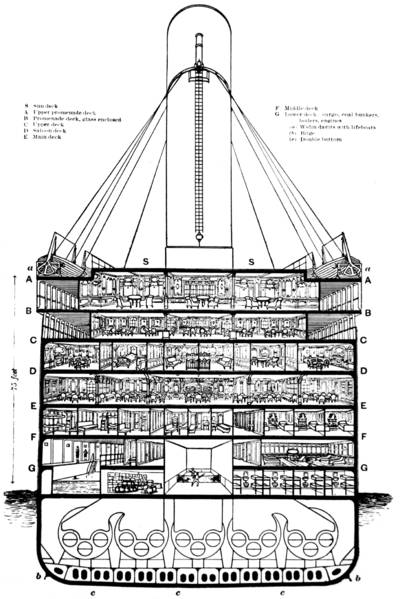
泰坦尼克号的剖面图
从图上可以看出从字母越前越靠近轮船上层,意味逃生的路径更短(这个和后面做新特征分析得到的统计信息是吻合的)。
这也是为什么Cabin即使有缺失数据,也可以换个姿势用来提取新特征。
CabinArea 则由Pclass和Deck组合而成,如 "P-1 D-C",意思是“头等舱的C区”
# extract CabinArea: where was he? () based on Pclass, Deck
# e.g.: "P-1 D-C"
df['CabinArea'] = df['Pclass', 'Deck'].map(:row) { |x| "P-#{x['Pclass']} D-#{x['Deck']}" }
提取 Mates(伙伴数量)
tickets = df['Ticket'].to_a.group_by(&:itself)
df['Mates'] = df['Ticket'].map { |ticket| tickets[ticket].size }
df['Mates'].uniq_proportions
# => {1=>0.545, 2=>0.202, 3=>0.112, 4=>0.049, 5=>0.027, 7=>0.027, 6=>0.018, 8=>0.012, 11=>0.008}
发现有近55%的乘客是独自出行,而后面做新数据分析发现,这样的人的生存率,不到3成。
提取 FamilySize(同船的家庭成员数量)
很简单,SibSp + Parch
# extract "FamilySize" from "SibSp" and "Parch"
df['FamilySize'] = df['SibSp'] + df['Parch']
df['FamilySize'].uniq_proportions
# {0=>0.604, 1=>0.18, 2=>0.121, 3=>0.033, 5=>0.019, 4=>0.017, 6=>0.012, 10=>0.008, 7=>0.006}
有6成是不带家人,然而,后面的数据分析显示,这个不是好主议。
提取 TravelAlone(是否孤身上路)
是否有伙伴或亲人,只有个人则标记为1,否则取0
df['TravelAlone'] = df['Mates', 'FamilySize'].map(:row) { |row| row.sum == 1 ? 1 : 0 }
df['TravelAlone'].uniq_frequencies
# => {1=>0.506, 0=>0.494}
各占一半。
把所有特征提取相关代码添加到 extract_features子任务中保存,至此,新的特征构建完毕!
至此我得到以下特征的数据:
-
Sex(性别)
-
AgeLevel(年龄层)
-
SocialTitle(社交头衔)
-
IncomeClass(收入水平)
-
SocialClass(社交地位)
-
FamilyRole(家庭角色)
-
CabinArea(舱位所在区域)
-
Mates(伙伴数量)
-
FamilySize(同船的家庭成员数量)
-
TravelAlone(是否孤身上路)
这些新特征是否真的对预测存活有帮助,接下来让看下新特征的分析和评估。
特征选取 - 评估及选取新特征
重新跑一次数据分析任务profile_data,这次加上任务参数feature_columns 来指定要分析的特征数据: feature_columns=Sex,AgeLevel,SocialTitle,IncomeClass,SocialClass,FamilyRole,CabinArea,Mates,FamilySize,TravelAlone
执行的完整命令为:
rake app:classifiers:titanic:profile_data label_column=Survived feature_columns=Sex,AgeLevel,SocialTitle,IncomeClass,SocialClass,FamilyRole,CabinArea,Mates,FamilySize,TravelAlone
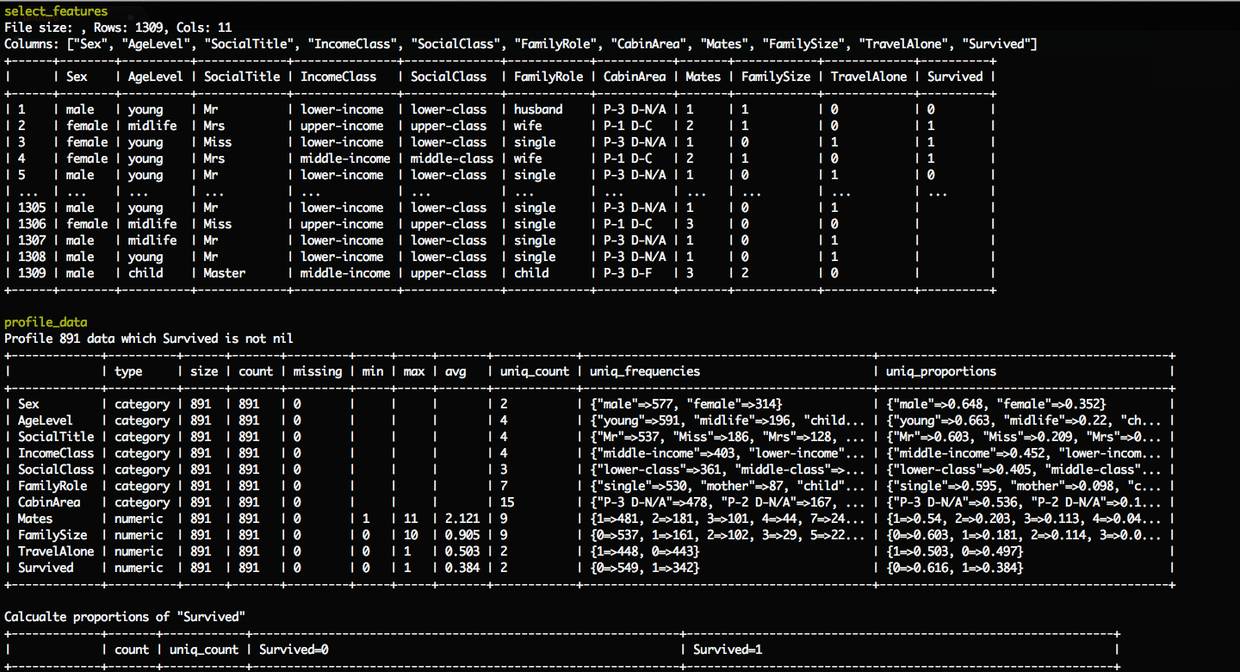
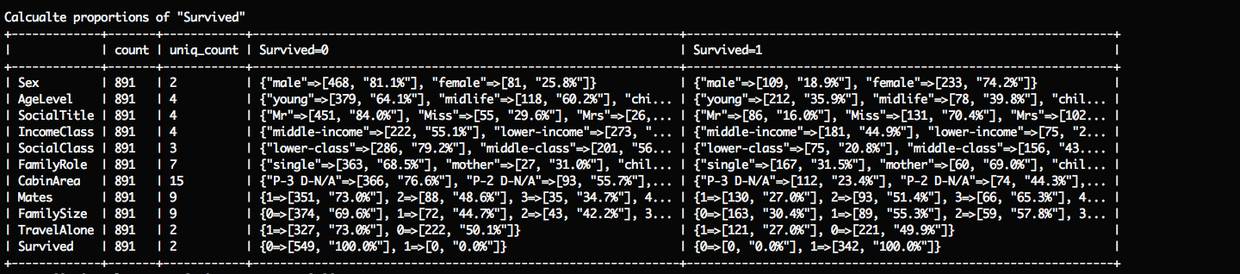
可以了解新增特征数据的整体概况,下面接着逐一分析每个新特征的数据统计。
新特征数据分析
要针对某个feature 分析,可以增加参数profile_feature=$feature_name 来执行数据分析任务profile_data,例如:
rake app:classifiers:titanic:profile_data label_column=Survived feature_columns=Sex,AgeLevel,SocialTitle,IncomeClass,SocialClass,FamilyRole,CabinArea,Mates,FamilySize,TravelAlone profile_feature=Sex
得到:
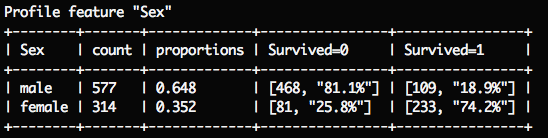
Sex(性别):
结合存活状态分布图:

Sex(性别)与存活状态分布图
在这场事故中,女性拥有更高的生存机率:74.2%;男性仅有18.9%。
性别为什么在这样的灾难中其关键性作用?从事后幸存者的口中得知,这是因为一个男人的一个命令。我们带着疑问继续看下其他特征的统计分析。
AgeLevel(年龄层):
年龄层统计结果:
Profile feature "AgeLevel"
+----------+-------+-------------+----------------+----------------+
| AgeLevel | count | proportions | Survived=0 | Survived=1 |
+----------+-------+-------------+----------------+----------------+
| young | 591 | 0.663 | [379, "64.1%"] | [212, "35.9%"] |
| midlife | 196 | 0.22 | [118, "60.2%"] | [78, "39.8%"] |
| child | 82 | 0.092 | [35, "42.7%"] | [47, "57.3%"] |
| aged | 22 | 0.025 | [17, "77.3%"] | [5, "22.7%"] |
+----------+-------+-------------+----------------+----------------+
按生理阶段分为4组:
-
child:少年(0-14)
-
young:青年(15-35)





