作者:Alfred 来自公众号:Alfred在纽西兰(id:gh_b6eff7d72ed8)
最近几天干啥都不来劲,昨晚偶然了解到Python里的itchat包,它已经完成了wechat的个人账号API接口,使爬取个人微信信息更加方便。鉴于自己很早之前就想知道诸如自己微信好友性别比例都来自哪个城市之类的问题,于是乎玩心一起,打算爬一下自己的微信。
安装完成后导入包,再登陆自己的微信。过程中会生产一个登陆二维码,扫码之后即可登陆。登陆成功后,把自己好友的相关信息爬下来。
import itchat
itchat.login()
#爬取自己好友相关信息, 返回一个json文件
friends = itchat.get_friends(update=True)[0:]
有了上面的friends数据,我们就可以来做分析啦。
仔细观察了一下返回的数据结构,发现”性别“是存放在一个字典里面的,key是”Sex“,男性值为1,女性为2,其他是不明性别的(就是没有填的)。可以写个循环获取想要的性别数据,得到自己微信好友的性别比例。
#初始化计数器
male = female = other = 0
#friends[0]是自己的信息,所以要从friends[1]开始
for i in friends[1:]:
sex = i["Sex"]
if sex == 1:
male += 1
elif sex == 2:
female += 1
else:
other +=1
#计算朋友总数
total = len(friends[1:])
#打印出自己的好友性别比例
print("男性好友: %.2f%%" % (float(male)/total*100) + "\n" +
"女性好友: %.2f%%" % (float(female) / total * 100) + "\n" +
"不明性别好友: %.2f%%" % (float(other) / total * 100))
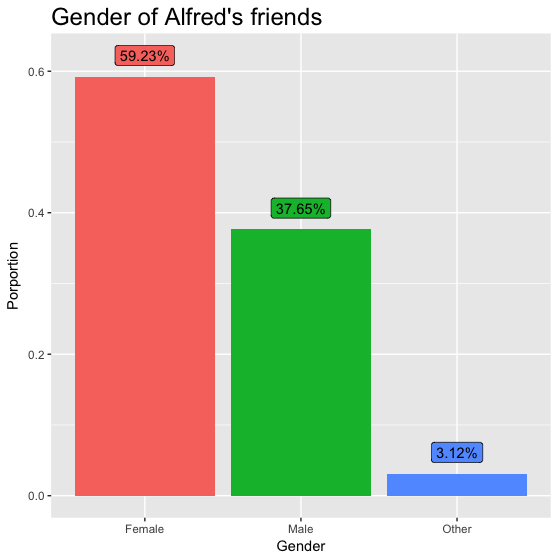
打印的结果为:
男性好友: 37.65%
女性好友: 59.23%
不明性别好友: 3.12%
啊,一不小心就暴露了自己女性朋友比较多的事实。然而为什么我现在还是一只汪?!
好了,再把这个数据用R画成图看看(Python作图真的是忍不了,代码就不放了):
再仔细观察friends列表,发现里面还包含了好友昵称、省份、城市、个人简介等等的数据,刚好可以用来分析好友城市分布,最好的方式是定义一个函数把数据都爬下来,存到数据框里,再进行分析。
#定义一个函数,用来爬取各个变量
def get_var(var):
variable = []
for i in friends:
value = i[var]
variable.append(value)
return variable
#调用函数得到各变量,并把数据存到csv文件中,保存到桌面
NickName = get_var("NickName")
Sex = get_var('Sex')
Province = get_var('Province')
City = get_var('City')
Signature = get_var('Signature')
from pandas import DataFrame
data = {'NickName': NickName, 'Sex': Sex, 'Province': Province,
'City': City, 'Signature': Signature}
frame = DataFrame(data)
frame.to_csv('data.csv', index=True)
以上便得到一个叫data的csv桌面文件, 用R打开并简单做一下数据预处理,得到如下(涉及隐私的已被预处理):
City NickName Province Sex Signature
1 Alfred 男 一个专注挖矿的,煎得一手好牛排#stay focused.
2 马鞍山 月* 安徽 女 你太虚伪了
3 花地玛堂区 M*** 澳门 女 双子,天秤,白羊
4 嘉*** 女
5 广州 西* 广东 女
6 珠海 浪**** 广东 男 满目青山空念远,不如惜取眼前人。
# ... with *** more rows
接着先根据省份、城市进行数据的分组和聚合,选择排名前二十的,利用ggplot2包画出如下的城市分布图(代码太长,不放了,就是这么任性,有需要参考的直接向我拿):
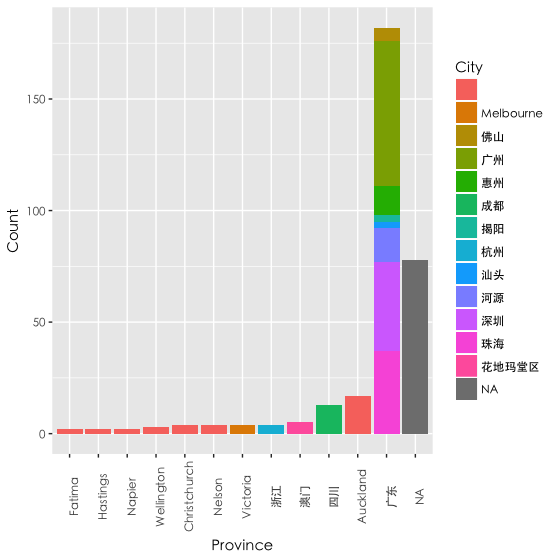
看来我大部分的朋友都是在广东的(不是废话吗),其中广东的朋友大部分集中在广、深、珠,第二名是在奥克兰, 接着是四川、澳门等。灰色的NA值是指没有设置自己所在地的朋友,一共有70多人。另外,在国外的朋友由于微信的设置问题(很多是直接跳过省份,只有城市可以选择的),很多国外的城市被误当成了省份。
再来一张图看看自己微信朋友在广东的具体分布(取前八):
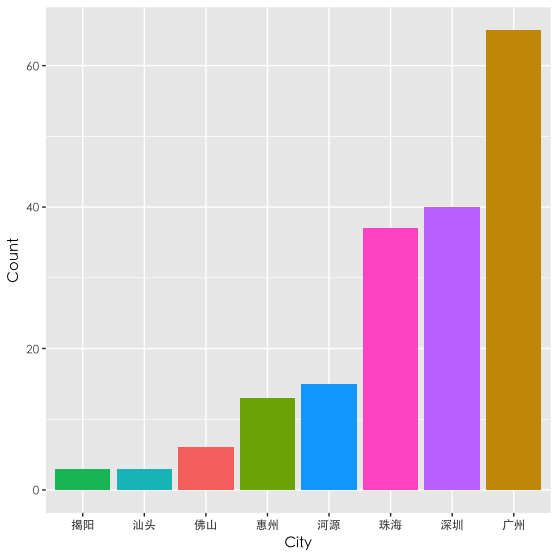
好玩的来了。之前已经爬下了每个好友的个性签名,刚好可以分析一下大伙儿个性签名时使用的高频词语是什么,顺便可以做个词云图。
先把原先爬下来的个性签名(Signature)打印出来,发现有很多本来是表情的,变成了emoji、span、class等等这些无关紧要的词,需要先替换掉,另外,还有类似<>/= 之类的符号,也需要写个简单的正则替换掉,再把所有拼起来,得到text字串。
import re
siglist = []
for i in friends:
signature = i["Signature"].strip().replace("span","").replace("class","").replace("emoji","")
rep = re.compile("1f\d+\w*|[<>/=]")
signature = rep.sub("", signature)
siglist.append(signature)
text = "".join(siglist)
接着就可以把JB,啊不,把结巴分词这个包搞进来分词。
import jieba
wordlist = jieba.cut(text, cut_all=True)
word_space_split = " ".join(wordlist)
终于可以进入画图阶段了。可以根据自己想要的图片、形状、颜色画出相似的图形(在这里,我使用的是我的头像,当然,为了颜色可以更加鲜艳使最后画出的词云图更加好看易辨,我先对自己的头像用PS做了一点小处理)。为此,我们需要把matplotlib、wordcloud、numpy、PIL等包搞进来。
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
import numpy as np
import PIL.Image as Image
coloring = np.array(Image.open("/Users/apple/Desktop/wechat.jpg"))
my_wordcloud = WordCloud(background_color="white", max_words=2000,
mask=coloring, max_font_size=60, random_state=42, scale=2,
font_path="/Library/Fonts/Microsoft/SimHei.ttf").generate(word_space_split)
image_colors = ImageColorGenerator(coloring)
plt.imshow(my_wordcloud.recolor(color_func=image_colors))
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()

看来,在我的微信好友的个人签名里,有人善于聆听,有人强调善良,有人重视灵魂,有人凝视人生。一直在等待,不放弃寻找。历尽曲折,不畏虚伪。真心如一,不能辜负。一步一生多努力,一起一切one more dream(真编不下去了)。
我本来提供的原图(经过处理的我的头像):

以上是不是很有趣呢?是不是又打开了一扇新世界的大门呢?
我微信好友也不是太多,如果微信好友有几千个,可以得到几千条数据,分析一下还是很有价值的。
当然,itchat包还有很多其他的功能还有待发掘,包括自动回复微信信息、自动添加好友、管理微信群等,有时间再慢慢摸索吧。
目前已有856+位行业人士加入.......
欢迎加入数据君数据分析秘密组织(收费)

(保存图到手机相册,然后微信扫,才可以加入)
这是一份事业!
数据挖掘与大数据分析
(datakong)

传播数据|解读行业|技术前沿|案例分享
2013年新浪百强自媒体
2016年中国十大大数据影响平台
荣誉不重要,干货最实在










