当地时间 2017 年 4 月 24-26 日,第五届 ICLR 会议将在法国土伦举行。作为深度学习领域的盛会之一,ICLR 2017 有许多精彩的内容值得我们关注。在这篇文章中,机器之心梳理了 ICLR 2017 提交论文的特点、本届会议的最佳论文以及机器之心过去一段时间报道过的有关 ICLR 2017 的文章。此外,去不了大会现场的读者也不必感到遗憾,因为有以下大会 Oral Session 的直播。
直播地址:https://www.facebook.com/iclr.cc
ICLR 全称为「International Conference on Learning Representations(国际学习表征会议)」。2013 年,深度学习巨头 Yoshua Bengio、Yann LeCun 主持举办了第一届 ICLR 大会。经过几年的发展,在深度学习火热的今天,ICLR 已经成为人工智能领域不可错过的盛会之一。
机器学习方法的表现极大地依靠所应用的数据表征的选择,表征学习领域的快速发展涉及到我们如何能够最好的学习数据中有意义、有作用的表征。ICLR 会议的关注点就包括深度学习、特征学习、度量学习、组合建模、结构化预测、强化学习等领域与主题,以及大规模学习、非凸优化问题。而这些技术应用的领域也非常广泛,从视觉到语音识别,到文本理解、游戏、音乐等各个领域。
下面列出了 ICLR 会议涉及的相关主题:
数个小时之后,ICLR 2017 即将在法国开幕。但在此之前,我们为你整理了以下内容,希望能为你参与此次大会(现场或看直播)提供帮助。
提交论文的可视化
在大会开始之前,我们觉得有必要了解下此届 ICLR 大会所提交的论文的特点。不久之前,Carlos E. Perez 使用 OpenReview 上的公开数据,对 ICRL 2017 上提交的论文进行了可视化分析,这能帮助我们了解此次大会的一些概况,比如哪些论文文献得到的评价好、作者以及引用量的分布。(注:文中作者使用 JavaScript 进行的可视化动态展示,此文不便于展示,感兴趣的读者可在这里查看:http://prlz77.github.io/iclr2017-stats)
首先,他使用 GloVe 算法对论文摘要词语进行了可视化,词语用 t-SNE 技术做了降维:
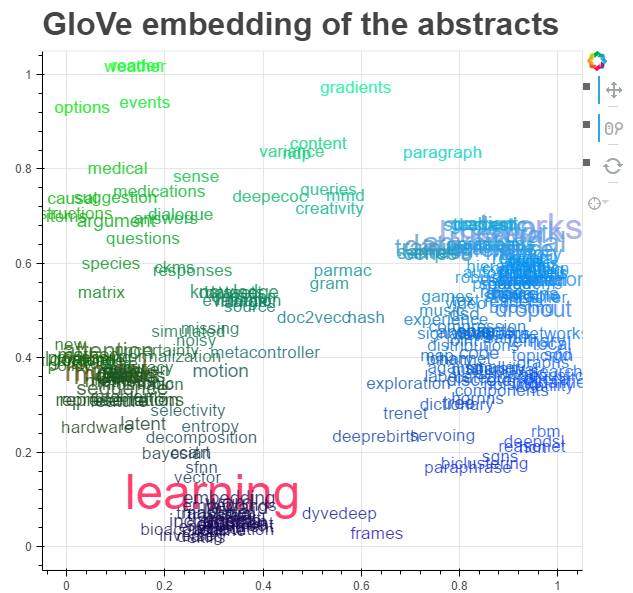
正如所料,网络、架构、数据、学习……是最常见的词。除此以外,回馈值(award)、注意(attention)和对抗(adversarial)也出现在重要词语的列表中,接下来是当前热门模型,深度强化学习、记忆/注意模型和生成对抗网络(GAN)模型。
除了论文中的关键词,哪家机构发论文最多?下图是使用提交论文中的所属机构(affiliation)字段,绘制出的每个机构提交数量的直方图:
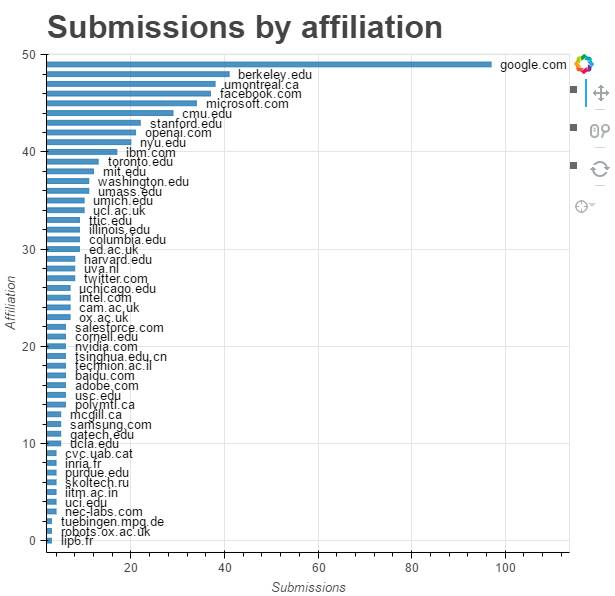
可以看出,前 50 名最高产的机构中,谷歌一马当先,下面依次是蒙特利尔大学、伯克利大学和微软。有趣的是,排名靠前的有很多新公司,特别是像 OpenAI 这样的新公司也能超过其它业已成熟的机构。
数量并不总是意味着质量,按照平均文献评价得分排序,该分析画出了以下论文数量气泡图(大小表示数量)。
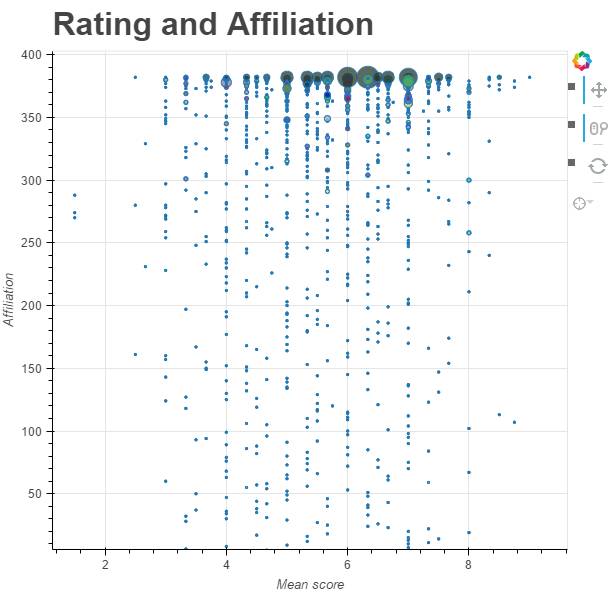
可以看到,谷歌有 9 篇论文的平均得分达到 7.5 以上,最大的一个气泡(论文数最多)包含了平均分为 6 的 13 篇论文。谷歌的论文包括 DeepMind、谷歌大脑和谷歌研究的论文。
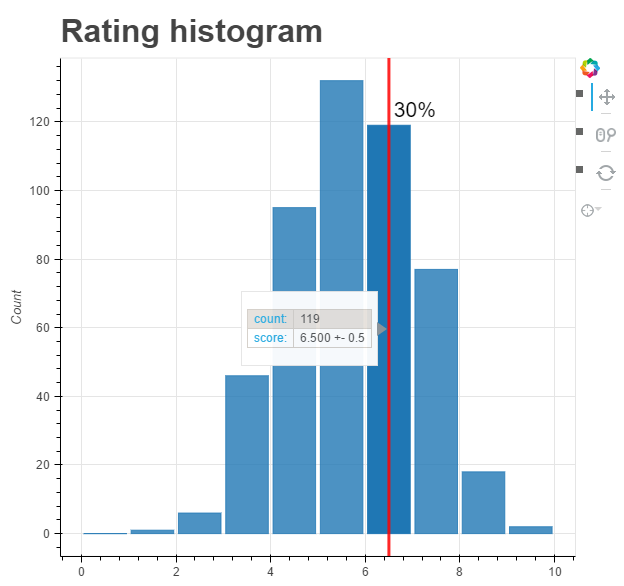
考虑到 ICLR 2016 的接收率接近 30%,Perez 对每个分数值制作直方图,以显示接收阈值:
最后,看一下有什么有趣的论文。在这里,使用散点图进行了表示,其中 y 轴表示论文的回复数量(作为「兴趣度」的度量),x 轴表示平均评论者置信度(reviewer confidence),气泡的大小和颜色反映论文的平均分数:
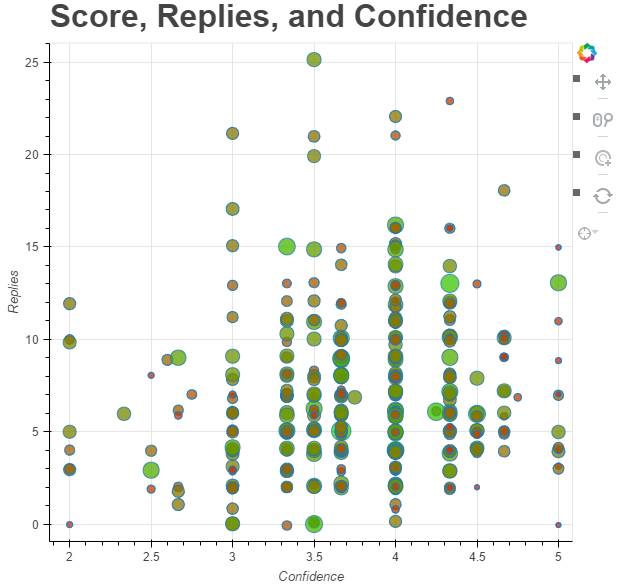
给定前面的三个参数,我们可以找到一些有趣的论文,如用于机器理解(Machine Comprehension)的双向注意力流(Bidirectional Attention Flow)、使用强化学习的神经架构搜索(Neural Architecture Search)以及离散变量自动编码器(Discrete Variational Autoencoders)。气泡可点击交互,链接到相应的 OpenReview 页面,Perez 还添加了一些随机抖动,以便在放大时它们能相互分开。
此外,Perez 还做了排名前 10 位的论文的可视化,排序先按照平均分数,然后按照置信度(分数是原始的平均分数)。
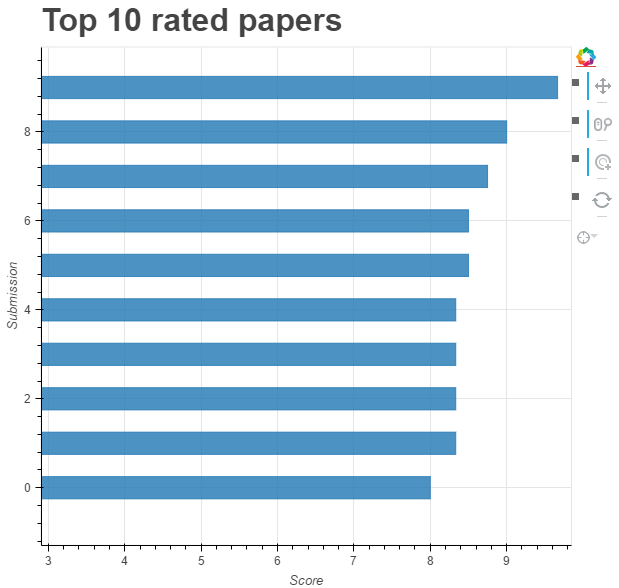
这里给出了排名前 10 的论文,其中第一名是《Understanding deep learning requires rethinking generalization》,这也是本届 ICLR 的最佳论文之一。
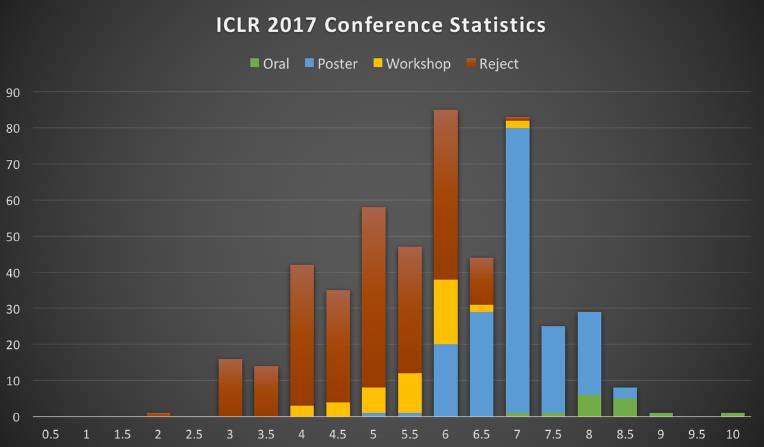
最后的论文接收分布类似于上面给出的分数直方图(阈值是在 6.5 和 6 之间):
最佳论文
这一节机器之心摘要介绍了 ICLR 2017 的三篇优秀论文(其中两篇都有谷歌参与),据官网的日程安排,大会三天每天都安排了对一篇最佳论文的宣讲。
最佳论文一:理解深度学习需要重新思考泛化(Understanding deep learning requires rethinking generalization)

尽管深度人工神经网络规模庞大,但它们的训练表现和测试表现之间可以表现出非常小的差异。传统的思考是将小的泛化误差要么归结为模型族的特性,要么就认为与训练过程中的正则化技术有关。
通过广泛的系统性实验,我们表明这些传统的方法并不能解释大型神经网络在实践中泛化良好的原因。具体而言,我们的实验表明一个当前最佳的用于图像分类的卷积网络(该网络是使用随机梯度方法训练的)可以轻松拟合训练数据的随机标签。这个现象在质量上不受特定的正则化的影响,而且即使我们将真实图像替换为完全非结构化的随机噪声,这个现象依然会发生。我们通过一个理论构建(theoretical construction)证实了这些实验发现,表明:只要参数的数量超过了数据点的数量(实践中常常如此),那么简单的 2 层深度的神经网络就已经有完美的有限样本表达能力(finite sample expressivity)了。
我们通过与传统模型的比较而对我们的实验发现进行了解释。
最佳论文二:基于隐私数据的深度学习半监督知识迁移(Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data)

一些机器学习应用的训练涉及到敏感数据,如临床试验中患者的病历。而模型中可能会无意中隐含一些训练数据;因此通过仔细分析该模型就能揭露一些敏感性信息。
为了解决这个问题,我们展示了一种能为训练数据提供强健隐私保障的普适性方法:教师全体的私有聚合(Private Aggregation of Teacher Ensembles/PATE)。该方法通过黑箱的方式组合多个由互斥数据集(如用户数据的不同子集)训练的模型。因为这些模型都依赖于敏感性数据,所以它们并不会发布,但是它们还是可以作为「学生」模型的「教师」。学生在所有教师间的投票中选择学习预测输出,其并不会直接访问单一的教师或基础参数与数据。学生的隐私属性可以直观地理解(因为没有单一的教师和单一的数据集决定学生的训练),正式地即依据不同隐私训练模型。即使攻击者不仅可以访问学生,还能检查内部运行工作,这一属性还将保持不变。
与以前的研究相比,该方法对教师的训练只增加弱假设条件:其适应于所有模型,包括非凸模型(如深度神经网络)。由于隐私分析和半监督学习的改进,我们的模型在 MNIST 和 SVHN 上实现了最先进的隐私/效用(privacy/utility)权衡。
最佳论文三:通过递归使神经编程架构泛化(Making Neural Programming Architectures Generalize via Recursion)

根据经验,想要从数据中学习程序的神经网络会表现出很差的泛化能力。而且一直以来,当输入复杂度(input complexity)超过一定水平时,我们也难以推理这些模型的行为。为了解决这些问题,我们提出了使用一种关键抽象——递归(recursion)——来增强神经架构。在一个应用中,我们在一个神经编程器-解释器框架中实现了递归——该框架可用于四种任务:小学加法、冒泡排序、拓扑排序和快速排序。我们表明该方法需少量训练数据就能得到更优的泛化能力和可解释性。回归可将问题分成更小的组成部分,并能极大减少每个神经网络组件的域(domain),使得该问题可以解决,从而能够保证整体系统的行为。我们的经验表明为了使神经架构能稳健地学习程序语义(program semantics),有必要结合使用递归这样的概念。
机器之心 ICLR 相关文章列表
下面列出了机器之心此前已经发布过的有关 ICLR 2017 会议的文章,其中包括对重要研究论文的介绍、关于自动编程研究的总结和一些实现。
本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]









