如何评测语义领域相关技术是大家共同关注的。三角兽公司基于多年理论和相关技术实践的经验,针对语义领域的 4个方向技术,将会发表一系列解读文章。本篇文章由三角兽 CEO Zhuoran Wang 提供。

注:三角兽科技 CEO Zhuoran Wang 博士曾参与 DSTC 2013的评测,期间他提出的一种领域无关的对话状态跟踪算法曾获 SIGDial 2013国际会议最佳论文提名,该系统在 DSTC 2014(即 DSTC 2&3)中被用做官方 baseline 系统。
1
正 文 如 下
人机对话,是人工智能领域的一个子方向,通俗的讲就是让人可以通过人类的语言(即自然语言)与计算机进行交互。作为人工智能的终极难题之一,一个完整的人机对话系统涉及到的技术极为广泛,例如计算机科学中的语音技术,自然语言处理,机器学习,规划与推理,知识工程,甚至语言学和认知科学中的许多理论在人机对话中都有所应用。笼统的讲,人机对话可以分为以下四个子问题:开放域聊天、任务驱动的多轮对话、问答和推荐。

我们通过下面的例子来说明这四类问题的不同体现。
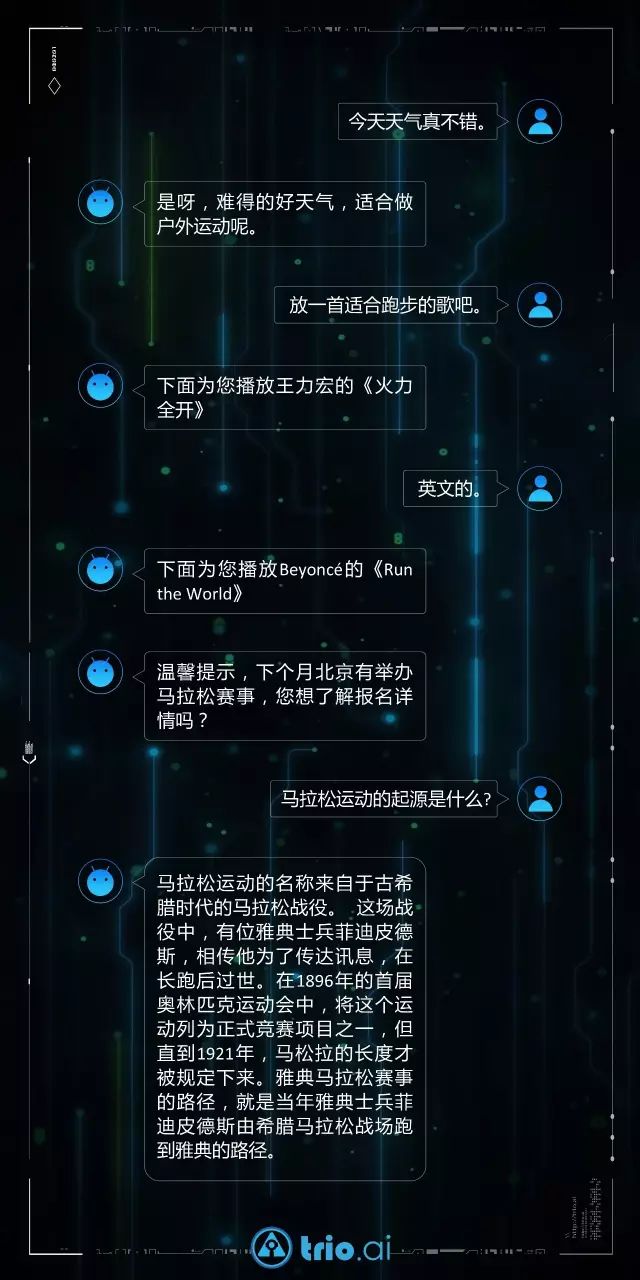
图1: 人机对话示例
开放域聊天:顾名思义,就是不局限话题的聊天,即在用户的 query 没用明确的信息或服务获取需求(如 social dialogue)时系统做出的回应。

图1中1-2行
为开放域聊天的典型示例
开放域聊天在现有的人机对话系统中,主要起到拉近距离,建立信任关系,情感陪伴,顺滑对话过程(例如在任务类对话无法满足用户需求时)和提高用户粘性的作用。
任务驱动的多轮对话:用户带着明确的目的而来,希望得到满足特定限制条件的信息或服务,例如:订餐,订票,寻找音乐、电影或某种商品,等等。因为用户的需求可以比较复杂,可能需要分多轮进行陈述,用户也可能在对话过程中不断修改或完善自己的需求。此外,当用户的陈述的需求不够具体或明确的时候,机器也可以通过询问、澄清或确认来帮助用户找到满意的结果。
因此,任务驱动的多轮对话不是一个简单的自然语言理解加信息检索的过程,而是一个决策过程,需要机器在对话过程中不断根据当前的状态决策下一步应该采取的最优动作(如:提供结果,询问特定限制条件,澄清或确认需求,等等)从而最有效的辅助用户完成信息或服务获取的任务。在学术文献中所说的 Spoken Dialogue Systems(SDS)一般特指任务驱动的多轮对话。
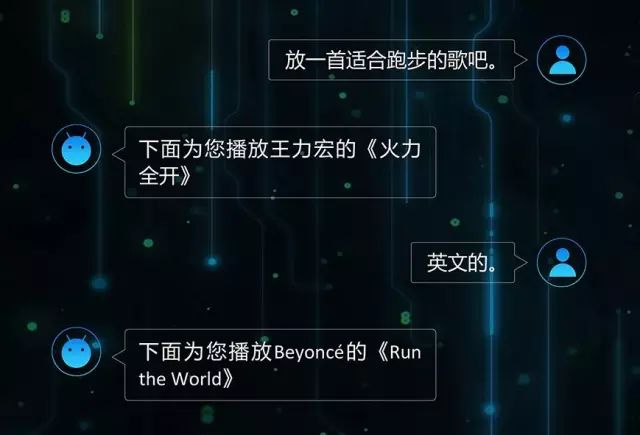
图1中的3-6行
是一个音乐领域的任务驱动的多轮对话的例子
问答:更侧重于一问一答,即直接根据用户的问题给出精准的答案。问答更接近一个信息检索的过程,虽然也可能涉及简单的上下文处理,但通常是通过指代消解和 query 补全来完成的。问答系统和任务驱动的多轮对话最根本的区别在于系统是否需要维护一个用户目标状态的表示和是否需要一个决策过程来完成任务。

图1中8-9行,是一个问答的例子
推荐:前面的开放域聊天,任务驱动的多轮对话和问答系统本质上都是被动的响应用户的 query,而推荐系统则是根据当前的用户 query 和历史的用户画像主动推荐用户可能感兴趣的信息或者服务,如图1中第7行的例子。

因为上述的四类系统各自要解决的问题不同,实现技术迥异,用一套系统实现所有功能是不现实的。通常要将上述功能整合在一个应用中,我们还需要一个中控决策模块。之所以叫中控决策,是因为这个模块不仅负责需求和问题的分类,还内包括任务之间的澄清、确认和跨领域的引导,所以最理想的技术实现也应该通过一个决策过程来完成[1]。
商业应用的人机对话系统根据应用的场景不同既可以是同时综合上述四类问题的复杂系统,也可以单纯解决其中一类问题。例如大家熟知的苹果 Siri、微软 Cortana、百度度秘等语音助手类产品就是集合上述四类问题综合系统(但是 Siri 和 Cortana 的聊天功能并不能算开放域,而是人工为高频的 query 编辑了对应的话术,当用户的聊天 query 不在预先配置的范围内时,系统则回复“我听不懂”之类的固定答案。而度秘的开放域聊天则是应用了更先进的基于海量数据的检索式聊天技术。相关技术的讨论超出了本文范畴,我们会在后续的文章中详解。)目前的智能客服类系统则多以解决问答和推荐类问题为主;微软推出的“小冰”,包括后继推出的同类型产品日文版 Rinna、英文版 Zo 和 Ruuh,主打的就是开放域聊天;而许多订票,订酒店类的对话系统则是任务驱动的多轮对话的典型应用。
问答和推荐是比较经典的问题,各自的技术和评估体系业界也相对熟悉。所以这篇文章先从任务驱动的多轮对话讲起。

首先我们来科普一下任务驱动的多轮对话系统。图2 为学术文献中任务驱动的多轮对话系统的一个经典框图。
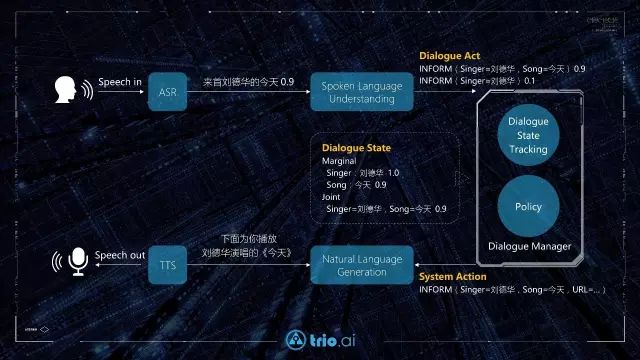
图2: 任务驱动的多轮对话系统的一个经典框图
自然语言理解:将自然语言的 query 识别成结构化的语义表示。在对话系统中,这个结构化的语义表示通常被称作 dialogue act 由 communicative function 和 slot-value pairs 组成,其中 communicative function 表示 query 的类型(如:陈述需求,询问属性,否定,选择疑问,等等)而每个 slot-value pair 则表达一个限制条件(constraint),也可理解为用户目标的一个组成单元。
例如“我要西二旗附近的川菜”对应的 dialogue act 可以表示为 inform(foodtype=川菜,location=西二旗)。这里“inform”就是 communicative function,表示陈述需求,“foodtype=川菜”和“location=西二旗”是限制条件(slot-value pairs) 。常用的 communicative function 定义可以参考剑桥大学的对话系统中使用的集合[2],而语言学家 Harry Bunt 等人则总结出了一套 ISO-24617-2 标准包含56个 communicative function 的定义,以及它的扩展集 DIT++ 包含88种定义。但由于 ISO-24617-2 和 DIT++ 体系过于复杂,通常的任务驱动类对话系统只用到其中很小一个子集就足够满足需求了,不过感兴趣的读者可以参考 DIT++ 网站(1)。
由于对话系统更关注口语处理,而且通常是处理经过了语音识别后的口语,所以在这个领域,我们通常说 Spoken Language Understanding(SLU),以突出与广义的自然语言理解的不同,并蕴含了对非严谨语法和语音识别错误鲁棒的问题。
对话状态跟踪:坦率的讲这个翻译有点儿诡异,英文中这个概念叫 Dialogue State Tracking(DST),看起来就是顺眼得多。概括的说,对话状态跟踪就是根据多轮的对话来确定用户当前的目标(user goal)到底是什么的过程。为了更好的理解这个过程,我们先来看看什么是对话状态。一个对话状态中,最主要的信息是用户的目的,即 user goal。用户目的的表示形式是一组 slot-value pairs 的组合。
图1中3-6行
概率分布,称作置信状态(belief state或者belief)。所以,对话状态跟踪有时也称作置信状态跟踪(belief state tracking)。
为了方便后面的讲解,这里再介绍两个概念,用户的目的在一个置信状态中的表示可以分为两部分:首先每个 slot 上都可以有多个可能的 value,每个 value 对应一个置信概率,这就形成了每个 slot 上的边缘置信状态(marginal belief);然后这些可能的 slot-value pairs 的组合的概率分布就形成的联合置信状态(joint be仍以图1中3-6行的对话为例,当对话进行到第3行时,用户的目的是“occasion=跑步”,到第5行时,这个目的就变成了“occasion=跑步,language=英文”。对话状态中还可以记录完成对话任务所需的其他额外信息,例如用户当前询问的属性(requested slots),用户的交互方式(communication method),和用户或系统的历史对话动作(dialogue history)等等。
此外,大家应该已经注意到无论 ASR 或者 SLU 都是典型的分类问题,既然是分类就会有误差,于是这给任务驱动的对话系统引入了一个在不确定性环境下决策的问题(planning under uncertainty)。虽然最终的决策是由下面要介绍的对话策略完成的,但是对话状态需要为后面的决策提供依据,也就是如何刻画这个不确定性的问题。要解决这个问题,首先我们希望 ASR 或 SLU(或两者)在输出分类结果的同时输出一个置信度打分,最好还能给出多个候选结果(n-best list)以更好的保证召回。然后对话状态跟踪模块在上述置信度和 n-best list 的基础上,不仅需要维护一个对话状态,而是估计所有可能的对话状态的 belief),也就是用户完整目的的概率分布。通常对话系统的决策过程需要参考这两部分信息才能找到最优的对话策略。
对话策略:即 policy,是根据上面介绍的置信状态来决策的过程。对话策略的输出是一个系统动作(system action)。和用户的 dialogue act 类似,系统动作也是一个由 communicative function 和 slot-value pairs 组成的语义表示,表明系统要执行的动作的类型和操作参数。“每次决策的目标不是当前动作的对与错,而是当前动作的选择会使未来收益的预期(expected long-term reward)最大化”。
自然语言生成:natural language generation(NLG)的任务是将对话策略输出的语义表示转化成自然语言的句子,反馈给用户。
有了上面的基础知识,我们就可以进入正题了:如何评估一个任务驱动的多轮对话系统?下面我们就分对话状态跟踪和对话策略两部分详细介绍。
等一下,为什么不讲 SLU 和 NLG?先说 SLU,其本质就是一个结构化分类的问题,虽然所用到的模型可能千差万别,繁简不一,但是评估标准比较明确,无非是准确率、召回率、F-score 等,所以这里就不详细论述了。至于 NLG,据我所知目前的商业应用的对话系统中的 NLG 部分主要是靠模板解决的,所以也没什么可评估的。不是说 NLG 问题本身简单,而是现有对话系统的能力还远没达到要靠优化 NLG 来提升用户体验的程度,前面一系列的问题还都没解决到极致,模板话术死板这事儿根本不是瓶颈所在。当然,学术界对 NLG 问题早有很多年的研究积累,感兴趣的读者可以参考我前前前雇主赫瑞瓦特大学交互实验室 Oliver Lemon,Helen Hastie 和 Verena Rieser,霍尔大学 Nina Dethlefs,还有剑桥大学对话组 Tsung-Hsien Wen 的工作。

虽然对话状态跟踪本质上也是一个分类问题,但作为辅助对话策略决策的一个关键步骤,DST 维护的是一个概率分布,那么这里就引入了两个问题:(1)怎样衡量一个概率分布的优劣;(2)在哪一轮评估合适。下面我们就结合2013年 Dialog State Tracking Challenge(DSTC)(2) 的评估结果来分析一下这些问题。
DSTC 2013 是国际上第一届对话状态跟踪任务的公开评测,由微软研究院,本田研究院和卡内基·梅陇大学联合组织。评测数据来自匹斯堡公车路线电话自动查询系统3年间的真实用户 log。评测提供5组训练集和4组测试集,分别用于测试以下四种情况:
(1)有与测试集来自完全相同的 ASR、SLU 和对话策略的训练数据;
(2)有与测试集来自完全相同的 ASR 和 SLU的训练数据,但对话策略不同;
(3)只有少量与测试集来自完全相同的 ASR、SLU 和对话策略的训练数据;
(4)产生测试数据的 ASR、SLU 和对话策略均与产生训练样本的系统不同。
除了两组训练集只有 ASR 的标注外,其它训练集均提供了人工标注的 ASR、SLU 和 DST 结果。此次评测共有11个团队参与,提交了27个系统。因为是第一次评测,主办方提出了11种评测指标和3种评测时机(schedule)作为参考,详细说明如下:
Hypothesis accuracy: 置信状态中首位假设(top hypothesis)的准确率。此标准用以衡量首位假设的质量。
Mean reciprocal rank: 1/R 的平均值,其中R是第一条正确假设在置信状态中的排序。此标准用以衡量置信状态中排序的质量。
L2-norm: 置信状态的概率向量和真实状态的0/1向量之间的 L2 距离。此标准用以衡量置信状态中概率值的质量。
Average probability: 真实状态在置信状态中的概率得分的平均值。此标准用以衡量置信状态对真实状态的概率估计的质量。
ROC performance: 如下一系列指标来刻画置信状态中首位假设的可区分性
Equal error rate: 错误接受率(false accepts,FAs) 和错误拒绝率(false rejects,FRs)的相交点(FA=FR)。
Correct accept 5/10/20: 当至多有5%/10%/20%的 FAs 时的正确接受率(correct accepts,CAs)。
上述 ROC 曲线相关指标采取了两种 ROC 计算方式。第一种方式计算 CA 的比例时分母是所有状态的总数。这种方式综合考虑了准确率和可区分度。第二种方式计算 CA 的比例时分母是所有正确分类的状态数。这种计算方式单纯考虑可区分度而排出准确率的因素。
图3:DSTC 2013 提交的系统根据上述11种评估指标
排序结果的不同程度[3] 圆圈的半径越小表示结果越相似
上述评估标准从不同角度衡量了置信状态的质量,但从 DSTC 2013提交的系统结果分析可以看出一些标准之间有很强的相关性,如图3所示。所以在后续的 DSTC 2014评测中选取了上述11中指标的一个子集作为主要评估指标。
DSTC 2013 还提出了三种评测的时机,分别为:
可以看出上述三种评估时机中,schedule 2 更能体现在真实应用中的价值。而 schedule 1是有偏执的,因为当一个概念被提及后,如果用户或系统没有对其修改的操作,多数情况下其置信状态的估计不会改变,这个结果会一直保持多个对话轮次,这样无论这个估计的质量优劣,都会被计算多次,对评估指标的均值产生影响。Schedule 3 的问题在于忽略了置信状态质量在对话过程中的影响,即一个概念如果在对话过程中被多次提及或澄清过,那么在对话过程中这个概念对应的置信概率的变化被忽略了。其实 schedule 2 也有一定的局限性,如果概念之间有冲突或相互影响,即当用户或系统提及一个概念时会潜在的影响其他在当前轮未被提及的概念的置信概率时,schedule 2 就无法衡量这个影响造成的状态变化。
次年,剑桥大学组织了两次 DSTC 评测(DSTC 2 & 3 (3) ),分别提出了两项新的挑战。在 DSTC2 中,对话的场景选为在剑桥找餐厅的问题。与 DSTC 2013 不同,此次评测假定用户的目标在对话过程中是可以改变的;随后在 DSTC 3 中,对话场景从找餐厅扩展到找餐厅或酒店。但 DSTC 3 除了极少量供调试用的种子数据外并不提供额外的训练数据,参评团队需要只用 DSTC 2 的训练数据训练模型,并迁移至DSTC3的测试集上。这两次评测的主要评估指标均为基于 schedule 2 的 accuracy,L2 norm 和 ROC CA 5。
之后的两年中,新加坡的 I2R A*STAR 研究所组织了 DSTC 4 (4) 和 DSTC 5 (5) 的评测 。主要评测目标是对在旅游场景下人和人对话中的对话状态建模。其中,DSTC 5 在 DSTC 4 的基础上提出通过机器翻译实现跨语言对话建模的挑战。由于这两次评测的数据来自人工标注,并没有引入 ASR 和 SLU,所以选用的评估指标是基于 schedule1 和 schedule 2 的 accuracy ,外加参评系统输出的 slot-value pairs 的准确率、召回率和 F-score。
现有的对话状态跟踪的评测标准有一定的局限性。主要问题在于,上述评估机制完全基于结构化的语义和对话状态表示。而在真实的商业应用对话系统中,为了更大程度的满足用户的需求,往往会采用结构化表示和非结构表示相结合的方法。例如,在第四代小米电视的对话系统中,三角兽科技就提供了模糊语义理解技术,在用户搜索视频的目的无法完全结构化表示时能够更精准的满足用户的需求。但是这种非结构化的表示则不适于用上述的评测标准进行评估,而应通过评估整体的对话效果来评测。

2017小米4A电视发布会中对三角兽科技表示感谢

首先,我们再次说明,因为对话策略是一个决策过程,无法评估单轮决策结果的优劣。所以对话策略的评估通常是通过评估整体对话系统的效果来实现的。
一个任务驱动的多轮对话系统的核心目的是最有效的帮助用户完成信息或服务获取的任务。那么,评估一个任务驱动的对话系统的好坏最直接的两个指标就是任务完成率和平均对话轮数。其中,任务完成率越高越好,而在同等对话完成率的基础上,平均对话轮数越少越好。理想的情况下,统计上述指标需要有真人参与对话。(虽然早期的对话系统研究中也有通过对话模拟器进行自动评估的先例[4],但是对话模拟器自身的质量引入了另一个维度的问题。)获得上述的统计结果,我们既可以离线标注真实用户与对话系统交互的 log[5],也可以预先(随机)产生用户目的,再让真人实验员按照指定的目的进行对话[6]。后者,可以通过 Amazon Mechanical Turk 类的众测平台完成[6]。此外,如果进行众测类实验,还应注意两个问题:(1)通常我们除了需要自动统计客观的任务完成率(通过匹配预先指定的用户目的和机器输出的结果),还应要求测试用户提供主观感知到的任务完成情况。因为根据以往的研究经验,这两个结果的绝对值会有较大出入[6];(2)造成主客观任务完成率差异的主要原因是测试用户因为各种原因在陈述需求时并未能准确完整的表达预定义的目的。因此,我们还需要一个检测机制来检验用户陈述的需求和系统输出结果的匹配程度[6]。
这里值得一提的是,据我所知唯一一次端到端对话系统的公开评测是 Spoken Dialog Challenge 2010,其选用的主要评估指标就是任务完成率和平均对话轮数。

评测一个任务驱动的多轮对话系统,主要涉及评测自然语言理解、对话状态跟踪和对话策略三个部分。自然语言理解是一个典型的分类问题,可以通过准确率、召回率和 F-score 等指标进行评测。对话状态跟踪,作为辅助对话策略的一个中间环节,业界已总结出一系列的评测标准,详情请参考历届 DSTC 公开评测。而对话策略的质量通常需要通过对话系统的整体效果来体现,其主要评测指标是任务完成率和平均对话轮数。
 参考文献
参考文献
[1] Z Wang, H Chen, G Wang, H Tian, H Wu & H Wang (2014) Policy Learning for Domain Selection in an Extensible Multi-domain Spoken Dialogue System. In Proceedings of Conference on Empirical Methods on Natural Language Processing (EMNLP 2014) .
[2] B Thomson & S Young (2010) Bayesian update of dialogue state: A POMDP framework for spoken dialogue systems. Computer Speech & Language 24 (4) , 562-588 .
[3] J Williams, A Raux, D Ramachandran & A Black (2013) The dialog state tracking challenge. In Proceedings of the SIGDIAL 2013 Conference .
[4] K Scheffler & S Young (2001) Corpus-based dialogue simulation for automatic strategy learning and evaluation. In Proceedings of NAACL Workshop on Adaptation in Dialogue Systems .
[5] A Black, S Burger, A Conkie, H Hastie, S Keizer, O Lemon, N Merigaud, G Parent, G Schubiner, B Thomson, J Williams, K Yu, S Young, & M Eskenazi (2011) Spoken Dialog Challenge 2010 : Comparison of Live and Control Test Results. In Proceedings of the SIGDIAL 2011 Conference .
[6] F Jurcıcek, S Keizer, M Gašic, F Mairesse, B Thomson, K Yu & S Young (2011) Real user evaluation of spoken dialogue systems using Amazon Mechanical Turk. In Proceedings of INTERSPEECH .
本文为机器之心转载文章,转载请联系原公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]








