导读:MySQL Query Rewrite Plugin 是 MySQL 5.7.6 引入的新功能,可以让 MySQL DBA 在 Server 内做一些 SQL 改写及优化,用于一些紧急优化或是测试上线。本文是吴炳锡在高可用架构群的分享,介绍如何如何使用该功能。
 吴炳锡,知数堂联合创始人,MySQL DBA 课程讲师,前新媒传信首席 DBA、MySQL 中国用户组(ACMUG)主席。吴炳锡老师有多年 MySQL 及系统架构设计及培训教学经验,擅长 MySQL 大规模运维管理优化、高可用方案、多 IDC 架构设计,企业级应用数据库设计等。
吴炳锡,知数堂联合创始人,MySQL DBA 课程讲师,前新媒传信首席 DBA、MySQL 中国用户组(ACMUG)主席。吴炳锡老师有多年 MySQL 及系统架构设计及培训教学经验,擅长 MySQL 大规模运维管理优化、高可用方案、多 IDC 架构设计,企业级应用数据库设计等。
大家好,我是吴炳锡 从MySQL工作10多年了,从MySQL 4.X开始折腾MySQL,跨度了MySQL 5.0, MySQL 5.1 , MySQL 5.5, MySQL 5.6及现在的MySQL 5.7,也经历了: MySQL AB,Percona, MySQL Sun,MariaDB Oracle MysQL这些公司对MySQL的发展的看法。 目前我和叶金荣,在全职创办: 知数堂
http://zhishuedu.com
从事MySQL ,Python,大数据相关的培训及服务支持工作。同时,也推荐一下个人的公众号(刚出生不久的一个公众号):

今天我给大家分享主题是:《MySQL Query Rewrite Plugin 的使用》 首先给大看一下 MySQL 5.7 后支持新特性:

这些还没包括一些微优化,如MySQL 5.7的分区不在是Server端处理,而是在引擎层处理,等等。
这里面很多功能,可以说是让你会觉是MySQL是一个全新的DB。 因为时间关系,我这里就不啰嗦了,大家以后有兴趣的,也可以一块去研究传播。也欢迎给我投稿。
Query Rewrite Plugin 介绍
MySQL发展到今天已经不是原来那个MySQL只能用来做增删改查,压力一大都容易压挂。现在的MySQL也可以顶住非常压力,来减少程序开发人员的任务。
MySQL Query Rewrite Plugin就是这么一个神器,可以让MySQL DBA在Server内做一些SQL改写及优化,用于一些紧急优化或是测试上线。
该功能是MySQL 5.7.6引入进来的。
需要注意以下约束:
• 只针对标准的SELECT语句工作,不能对视图定义及存储过程中SELECT语句改写
• 改写规则记录在内存中,实际对应到:query_rewrite库下的rewrite_rules这个表
• 利用query_rewrite下的存储过程: flush_rewrite_rules() 及DML语句来加载更改规则
工作原理
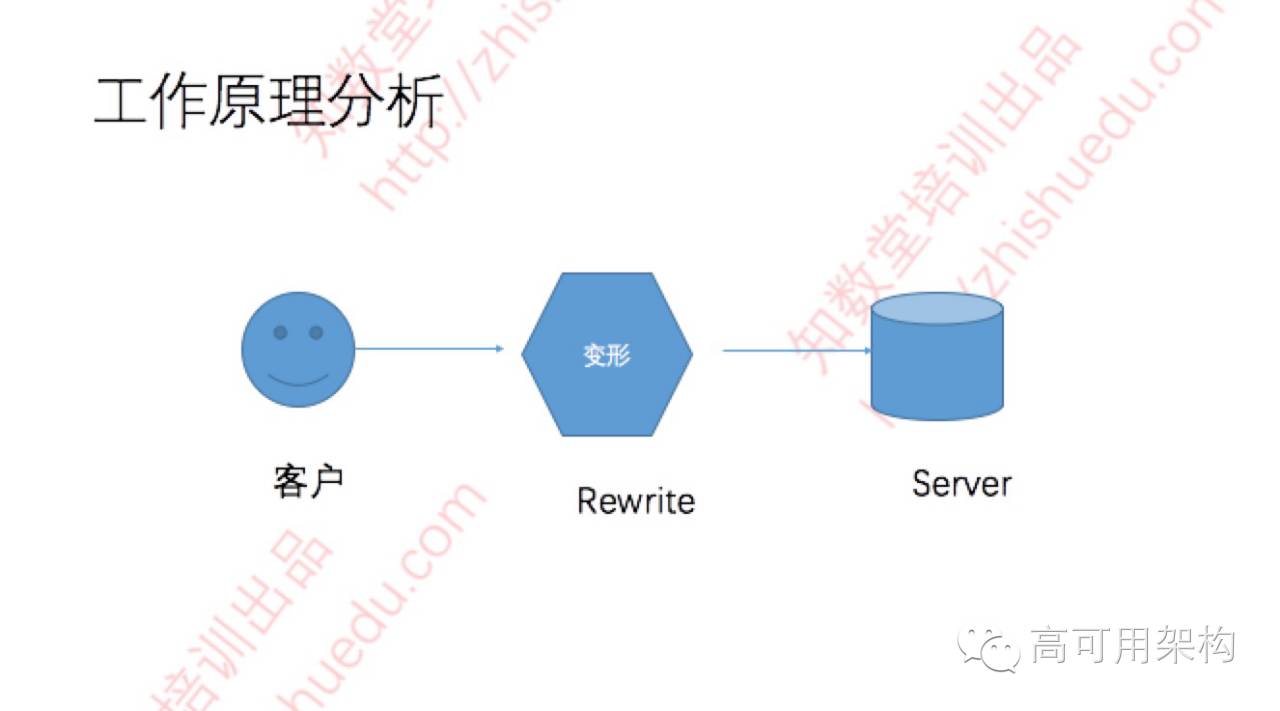
客户端发起SQL请求,在Server内部进行改写,然后在执行。 在这个改写可以在接收到SQL的明文SQL改写,也可以是优化器处理完后的词法树改写,目前这块使用是的明文改写。也可以参考下图:
启用或禁用 Query Rewrite Plugin
在相应的MySQL发行版目录下对应到: $basedir/share/install_rewriter.sql
#mysql -u root -p
加载完毕,无报错的情况下,进入MySQL再次确认一下:
MySQL>SHOW GLOBAL VARIABLES LIKE 'rewriter_enabled';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| rewriter_enabled | ON |
+------------------+-------+
(如果没找到相的SQL,请确认一下MySQL的版本是不是支持)
如果为了长期使用,建议写到配置文件:
[mysqld]
rewriter_enabled=ON
说明: 如果想禁用该特性,只需要使用相应的$basedir/share/uninstall_rewriter.sql
来一个简单的练习,测试一下:
use rewrite_rules;
insert into rewrite_rules(pattern, replacement) values('select ?' , 'select ?+1');
call flush_rewrite_rules();

特别提示: 被SQL改写的SQL在测试时,可以利用show warnings; 来确定一下改写成什么样子
再来看一下:
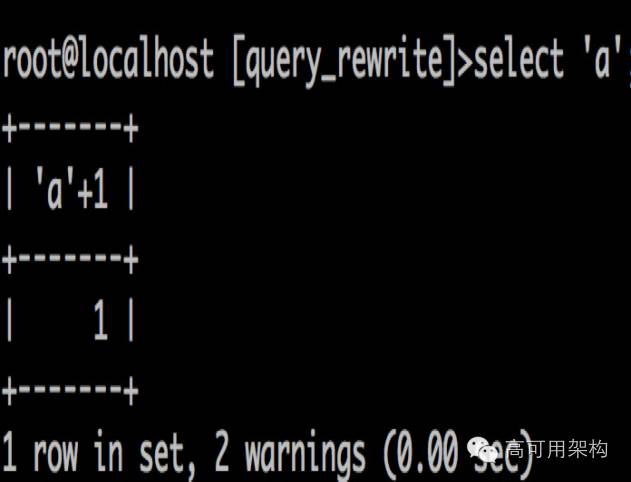
两个警告, 一个是类型不对,内部去除,另一个进行转换+1

这里看到关建词,并没有进行转换。 所以大家对于转换也要小词,对于关词键,类型不匹配的也要小心处理。 免的出现不是预期的结果。
简单说一下,存储改写规则的表, 也让我们后面能更好的使用及排查问题:
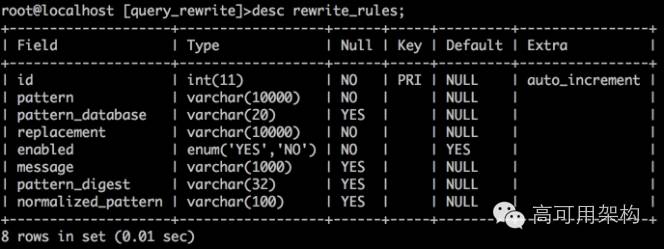
id: 无业务意义,就是自增(一个良好的习惯)
pattern : 对应的需要改写的源SQL,规一化后的样子(把参数,用问题替换)
pattern_database: 指写需要改写的DB名称(如果SQL中有From关键词,且SQL中没有DB名,该参数是必须的)
replacement: 指定改写后的样子
enabled: 是不是启用
message: 改写启用,如果规则不生效,错误原因在这里,该字段一段应该是空的。
pattern_digest : 用于Debug使用 ,一般可以不看
normallized_pattern: 用于Debug使用,一般可以不看
开始 Case,从 Case 中学习
分成以下几个案例:
•
去除类型转换
•
改字段名后兼容报错
•
利用
SQL改写优化(join例子)
•
添加
SQL执行超时
首先看第一个案例:
表结构:

查询:
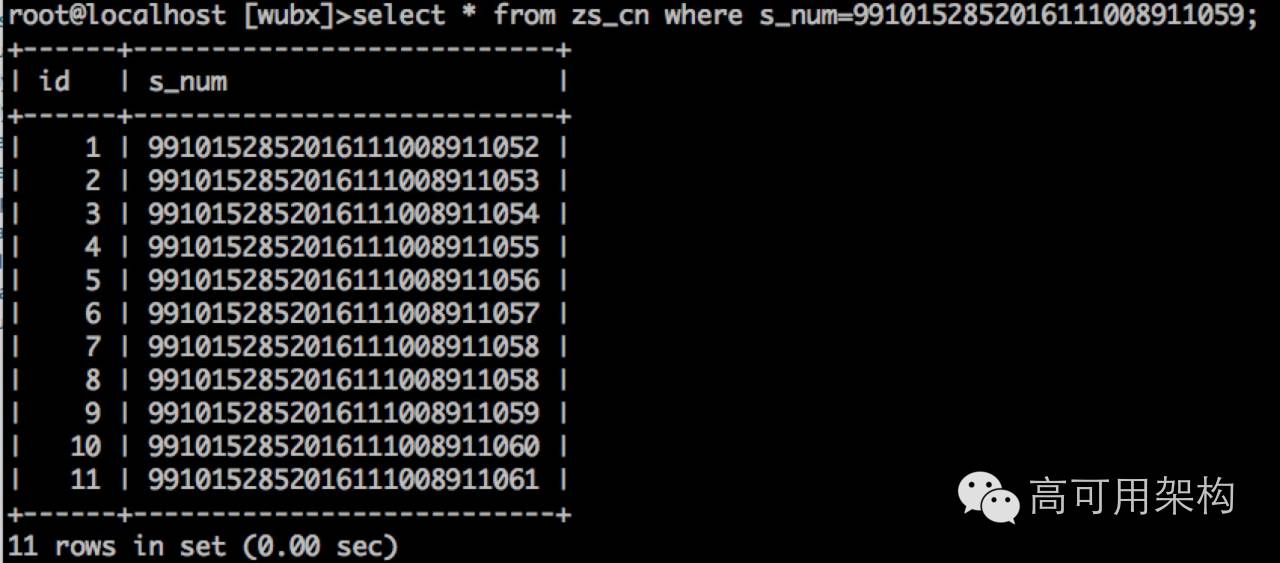
看到有什么问题了吗? (表里只有11行数据,所有都查出来),而且更不靠谱的是连一个警告都没有。
有经验的DBA一看就知道是数据类型的问题,处理上也非常发方便,在SQL上加一个引号就可以了。 如果这个是线上发现, 立刻让开发去改,特别是那种编译性语言,也不会太快。 那么先来看看Query rewrite 来一个首秀:
•
insert into query_rewrite.rewrite_rules(pattern,pattern_database, replacement) -> values("select * from zs_cn where s_num=?","wubx","select * from zs_cn where s_num=cast(? as char character set utf8)");
•
call query_rewrite.flush_rewrite_rules();
特别注意: 在转换中 ? 不能用引号括起来,要不,就不起作用了。
改写:
root@localhost [wubx]>show warnings;+-------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| Level | Code | Message |+-------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| Note | 1105 | Query 'select * from zs_cn where s_num=9910152852016111008911059' rewritten to 'select * from zs_cn where s_num=cast(9910152852016111008911059 as char character set utf8)' by a query rewrite plugin |+-------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
出错排查举例

在启用规则时报错,
查询:select * from query_rewrite.rewrite_rules;

提示一般比较明确,很容易看明白。
案例二: 改字段名后兼容报错
提示:
: ERROR 1054 (42S22): Unknown column ‘id’ in ‘where clause’ for Table : zs_user


出错的原因:
• 业务上线字段写错
• 线上更改字段名,有的业务没改等等原因
利用query rewrite rule 救急:
• insert into query_rewrite.rewrite_rules(pattern,pattern_database, replacement) values('select * from zs_user where id=?','wubx','select * from zs_user where user_id=?');
• call query_rewrite.flush_rewrite_rules();
改写后完美运行

利用子查询优化inner join(去除)
SELECT count( distinct emp_no) FROM employees.employees INNER JOIN employees.salaries USING(emp_no) WHERE DATEDIFF(to_date, from_date)

优化后的样子:

inner join是一个迪卡尔集,所以准确需要去除。
而
IN操作,只是查前面,看是不是在后面这个里面,在MySQL 5.7 相当于做一个物化视图,会执行好放那里。 这样只有判断,前面的结果是不是在后面的集合中,所以不用去除了。
(这里一个特殊的要求,前表字段是唯一的)
知道了这一切后,可以固化这个
SQL:
INSERT INTO query_rewrite.rewrite_rules
(
pattern,
Replacement
)
VALUES
(
'SELECT count(distinct emp_no) FROM employees.employees INNER JOIN employees.salaries USING(emp_no) WHERE DATEDIFF(to_date, from_date)
'SELECT count(emp_no) FROM employees.employees WHERE emp_no IN ( SELECT emp_no FROM employees.salaries WHERE DATEDIFF(to_date, from_date)
);
CALL query_rewrite.flush_rewrite_rules();

再来看下一个例子:添加SQL执行超时
• 大家还在使用pt-kill吗?
• 可以一刀切,不管是什么语句,超时就干掉
• MySQL 5.7后推出了: max_execution_time 这个参数, 只作用于SELECT语句,但不处时存储过程中的SELECT语句
• 5.7 还引入一个 HINT可以用于语句超时,只针对个别SQL
• /*+ MAX_EXECUTION_TIME(N) */ #N毫秒

INSERT INTO query_rewrite.rewrite_rules
(
pattern,
Replacement
)
VALUES
(
'SELECT count(distinct emp_no) FROM employees.employees INNER JOIN employees.salaries USING(emp_no) WHERE DATEDIFF(to_date, from_date)
‘SELECT /*+ MAX_EXECUTION_TIME(1000)*/ count(distinct emp_no) FROM employees.employees INNER JOIN employees.salaries USING(emp_no) WHERE DATEDIFF(to_date, from_date)
);
CALL query_rewrite.flush_rewrite_rules();










