机器学习已成为数据科学家工具包中重要的工具,并在过去十多年中因其在各种应用中展现出的炫目成果而变得广为人知。要有效地利用机器学习的力量,理解其基本概念及其实际应用至关重要。
接下来我们将探讨数据科学项目中常用的十个机器学习算法。
1.线性回归(Linear Regression)
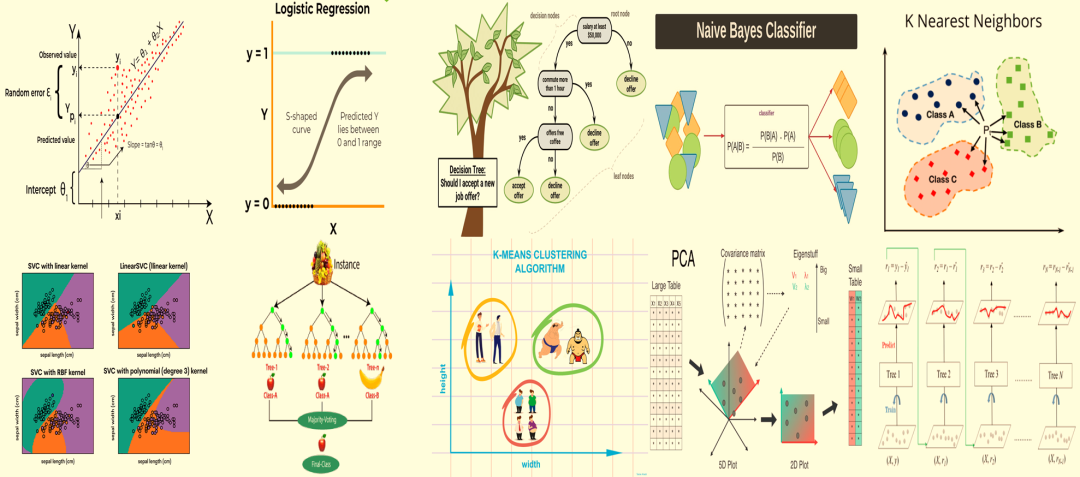
线性回归(Linear Regression)通过建立输入变量和输出之间的线性关系来预测连续输出。可以想象在图上的一组点中画一条直线。
它通过找到最适合数据点的直线来做出决定。这条直线是通过最小化实际值和直线预测值之间的差异(误差)来确定的。
评估指标
使用Sci-kit Learn及Diabetes数据集,下面代码块中遵循的常见步骤:
-
加载Diabetes数据集:该数据集包括十个基线变量,包括年龄、性别、BMI、平均血压和六个糖尿病患者的血清测量值。
-
拆分数据集:将数据集分为训练集和测试集。
-
创建并训练线性回归模型:使用训练集构建模型。
-
预测和评估:使用测试集进行预测,然后使用MSE和R-squared评估模型。
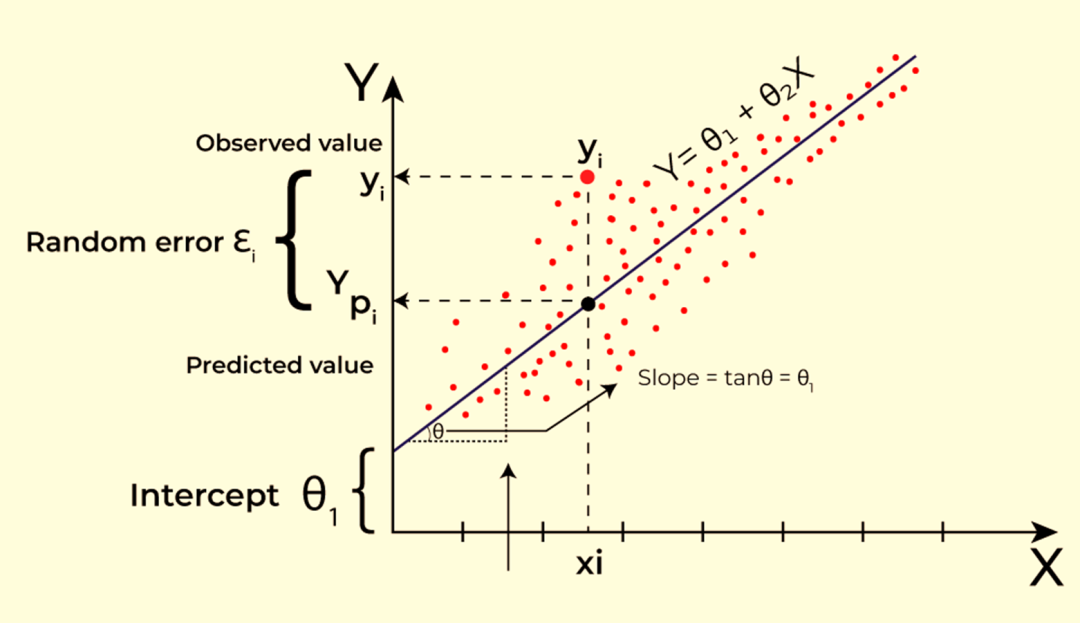
import numpy as npimport pandas as pdfrom sklearn.datasets import load_diabetesfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionfrom sklearn.metrics import mean_squared_error, r2_score
diabetes = load_diabetes()X = diabetes.datay = diabetes.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LinearRegression()model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)r2 = r2_score(y_test, y_pred)
print(f'Mean Squared Error: {mse}')print(f'R-squared: {r2}')
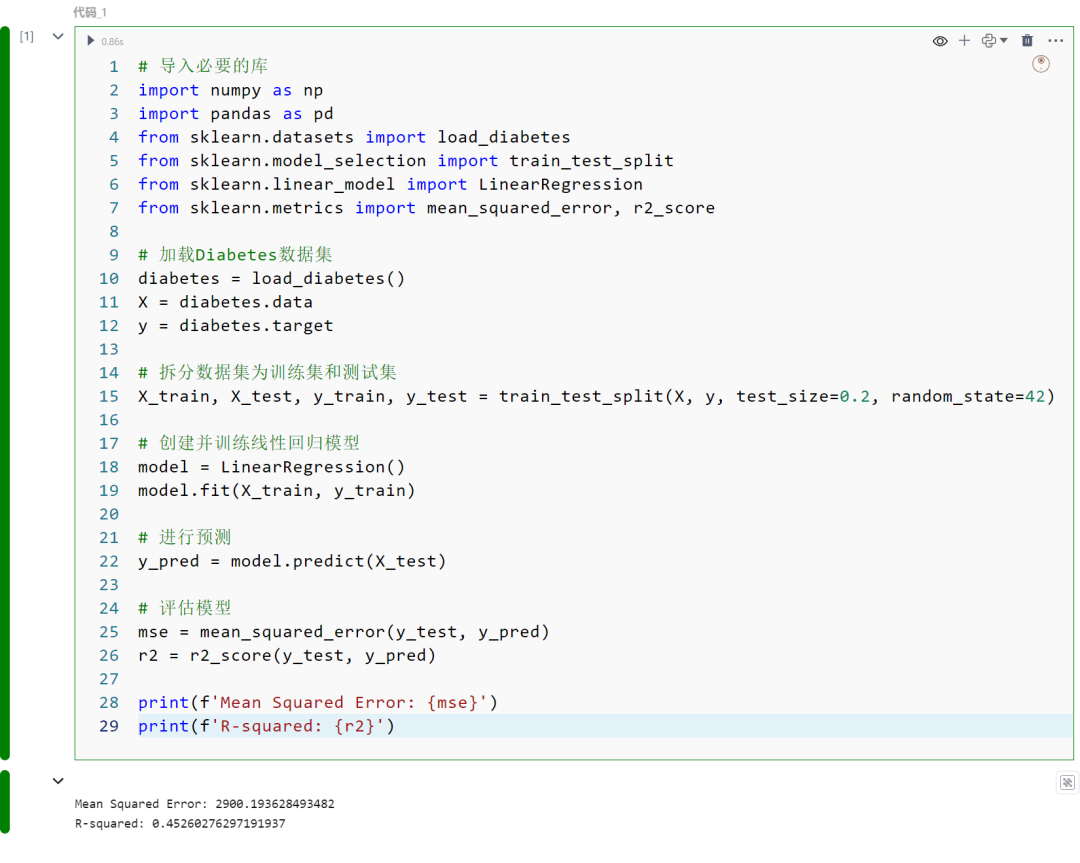
2.逻辑回归(Logistic Regression)
逻辑回归(Logistic Regression)用于分类问题。它预测给定数据点属于某一类的概率,如是/否或0/1。它使用逻辑函数输出一个介于0和1之间的值,然后根据阈值(通常为0.5)将该值映射到特定类别。
评估指标:
使用Sci-kit Learn及Breast Cancer数据集的应用逻辑回归的步骤:
-
加载Breast Cancer数据集:该数据集包含从乳房肿块的细针抽吸(FNA)数字化图像计算的特征,目标是将其分类为良性或恶性。
-
拆分数据集:将数据集分为训练集和测试集。
-
创建并训练逻辑回归模型:使用训练集构建模型。
-
预测和评估:使用测试集进行预测,然后使用准确率、精确率、召回率和F1分数评估模型。
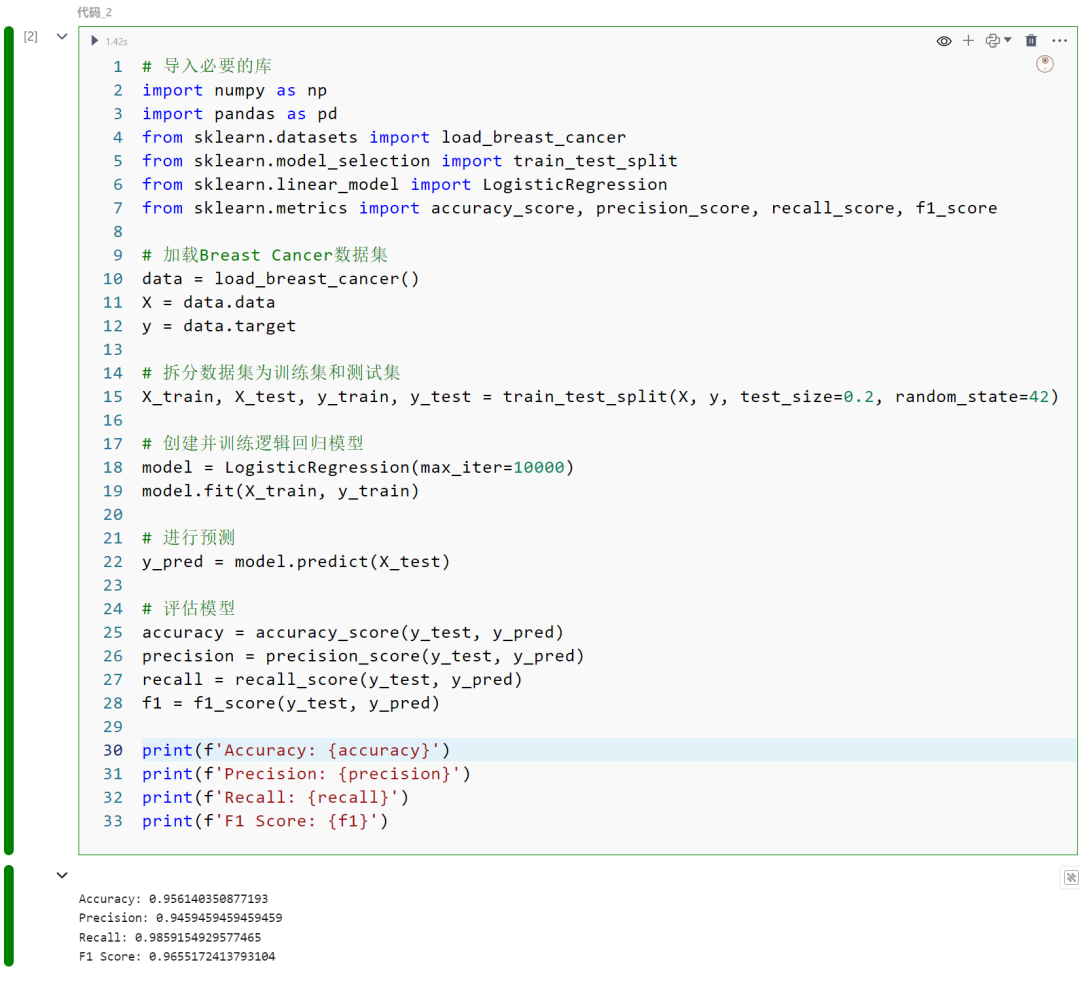
import numpy as npimport pandas as pdfrom sklearn.datasets import load_breast_cancerfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
data = load_breast_cancer()X = data.datay = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LogisticRegression(max_iter=10000)model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)precision = precision_score(y_test, y_pred)recall = recall_score(y_test, y_pred)f1 = f1_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')print(f'Precision: {precision}')print(f'Recall: {recall}')print(f'F1 Score: {f1}')
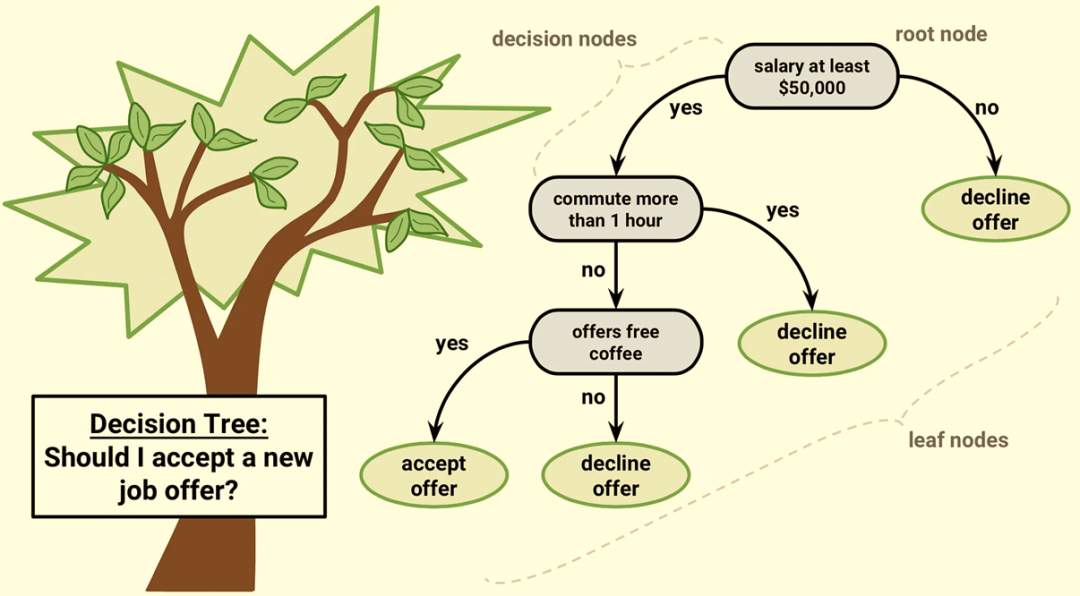
3.决策树(Decision Trees)
决策树(Decision Trees)类似于树状流程图,根据某些条件或特征对数据进行拆分。它们可以应用于回归和分类。决策树的工作原理是使用特征值将数据集拆分成更易管理的子组。每个内部节点表示一个属性测试,每个分支表示测试结果,每个叶节点表示一个类标签(决策)。
评估指标
使用Sci-kit Learn及Wine数据集进行决策树分类任务。该数据集是关于基于不同属性将葡萄酒分类为三种类型。训练模型、预测葡萄酒类型,并使用分类指标评估模型。
下面代码是基本流程和步骤:
-
加载Wine数据集:该数据集包括对在意大利同一地区生产的三种不同葡萄酒的化学分析。研究确定了三类葡萄酒中十三种成分的不同含量。
-
拆分数据集:将数据集分为训练集和测试集。这是为了在数据的一部分(训练集)上训练模型,并在未见过的数据(测试集)上测试其性能。使用80%的数据进行训练,20%的数据进行测试。
-
创建并训练决策树模型:创建一个决策树分类器。该模型将从训练数据中学习。它构建了一个类似树状的决策模型,其中树中的每个节点表示数据集的一个特征,分支表示决策规则,导致不同的结果或分类。
-
预测和评估:使用模型预测测试集的分类。通过将这些预测与实际标签进行比较来评估模型的性能。
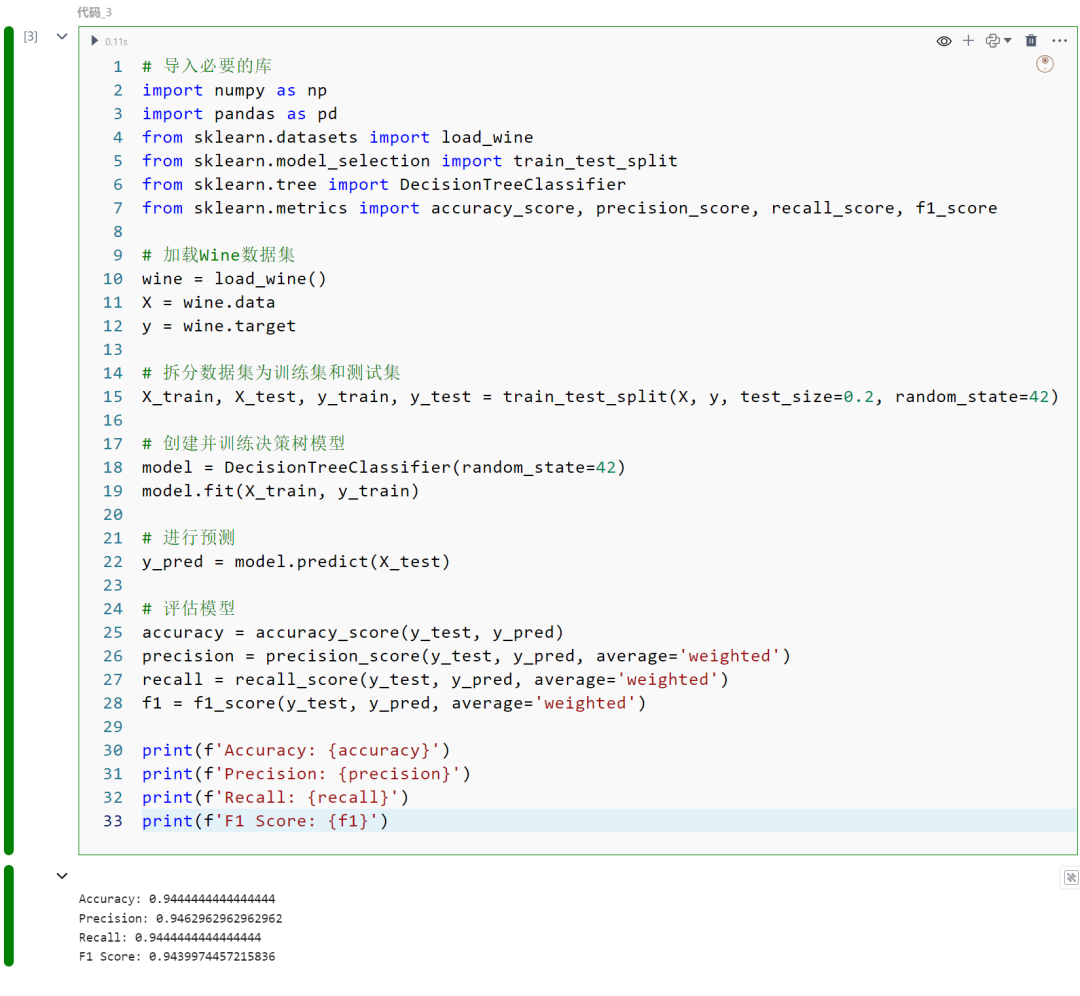
import numpy as npimport pandas as pd
from sklearn.datasets import load_winefrom sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
wine = load_wine()X = wine.datay = wine.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = DecisionTreeClassifier(random_state=42)model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)precision = precision_score(y_test, y_pred, average='weighted')recall = recall_score(y_test, y_pred, average='weighted')f1 = f1_score(y_test, y_pred, average='weighted')
print(f'Accuracy: {accuracy}')print(f'Precision: {precision}')print(f'Recall: {recall}')print(f'F1 Score: {f1}')
4.朴素贝叶斯(Naive Bayes)
朴素贝叶斯分类器是一类简单的“概率分类器”,使用贝叶斯定理和特征之间强(朴素)独立性假设。它特别适用于文本分类。
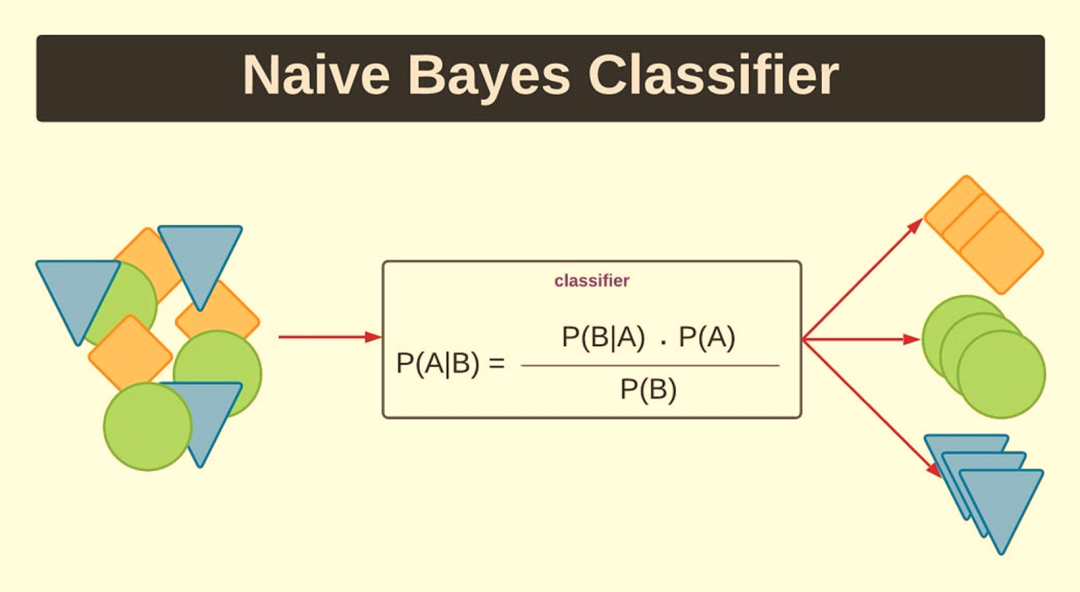
它计算每个类别的概率以及给定每个输入值的每个类别的条件概率。这些概率然后用于根据最高概率分类新值。
评估指标:
使用Sci-kit Learn及Digits数据集进行示例:该数据集涉及对手写数字(0-9)的分类。这是一个多类分类问题。下面是训练朴素贝叶斯模型、预测数字类别,并使用分类指标进行评估。以下代码是基本步骤。
-
加载Digits数据集:Digits数据集包含8x8像素的手写数字图像(从0到9)。每个图像表示为一个64个值的特征向量(8x8像素),每个值代表像素的灰度强度。
-
拆分数据集:与之前的例子类似,将数据集分为训练集和测试集。使用80%的数据进行训练,20%的数据进行测试。这有助于在大部分数据上训练模型,然后在未见过的单独数据集上评估其性能。
-
创建并训练朴素贝叶斯模型:创建一个高斯朴素贝叶斯分类器。这种朴素贝叶斯的变体假设与每个特征相关的连续值是根据高斯(正态)分布分布的。然后在训练数据上训练(拟合)模型。它学习将输入特征(像素值)与目标值(数字类别)关联起来。
-
预测和评估:训练后,使用模型预测测试数据的类别标签。
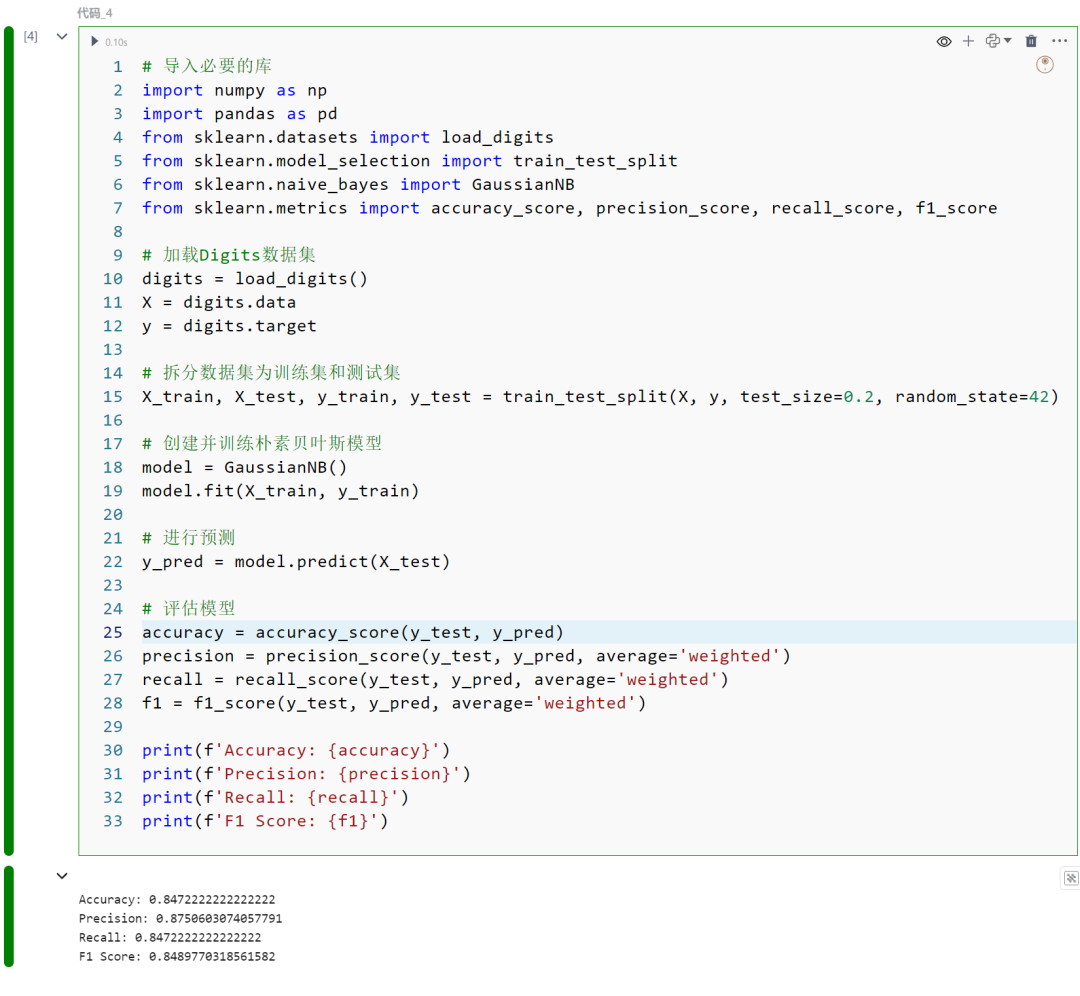
import numpy as npimport pandas as pdfrom sklearn.datasets import load_digitsfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
digits = load_digits()X = digits.datay = digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = GaussianNB()model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)precision = precision_score(y_test, y_pred, average='weighted')recall = recall_score(y_test, y_pred, average='weighted')f1 = f1_score(y_test, y_pred, average='weighted')
print(f'Accuracy: {accuracy}')print(f'Precision: {precision}')print(f'Recall: {recall}')print(f'F1 Score: {f1}')
5.K近邻(K-Nearest Neighbors,KNN)
机器学习算法里面,最易于理解的回归和分类方法是K-近邻(K-Nearest Neighbors,KNN)。一个数据点根据其邻居的分类进行分类。
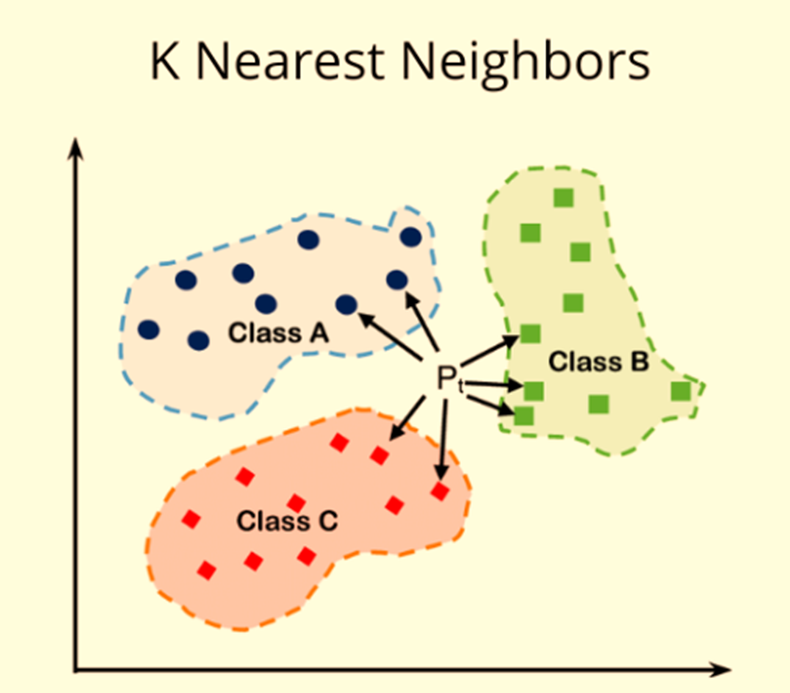
KNN查看数据点的“K”个最近点(邻居),并根据这些邻居的多数类进行分类。对于回归,它取“K”个最近点的平均值。
评估指标
-
分类:准确率、精确率、召回率、F1分数。
-
回归:均方误差(MSE)、R-squared。
使用Sci-kit Learn和Wine数据集,使用KNN模型来分类葡萄酒类型,并使用分类指标评估其性能。以下是基本步骤和代码。
-
创建并训练KNN模型:创建一个K-近邻(KNN)模型,设定n_neighbors=3。这意味着模型查看数据点的三个最近邻居以做出预测。使用训练数据训练(拟合)模型。在训练过程中,它不会构建传统模型,而是记住数据集。
-
进行预测:然后使用训练好的KNN模型预测测试数据的类别标签(葡萄酒类型)。模型通过查看训练集中三个最近的点来确定测试集中每个点最常见的类别。
-
评估:将模型的预测结果与测试集的实际标签进行比较评估。
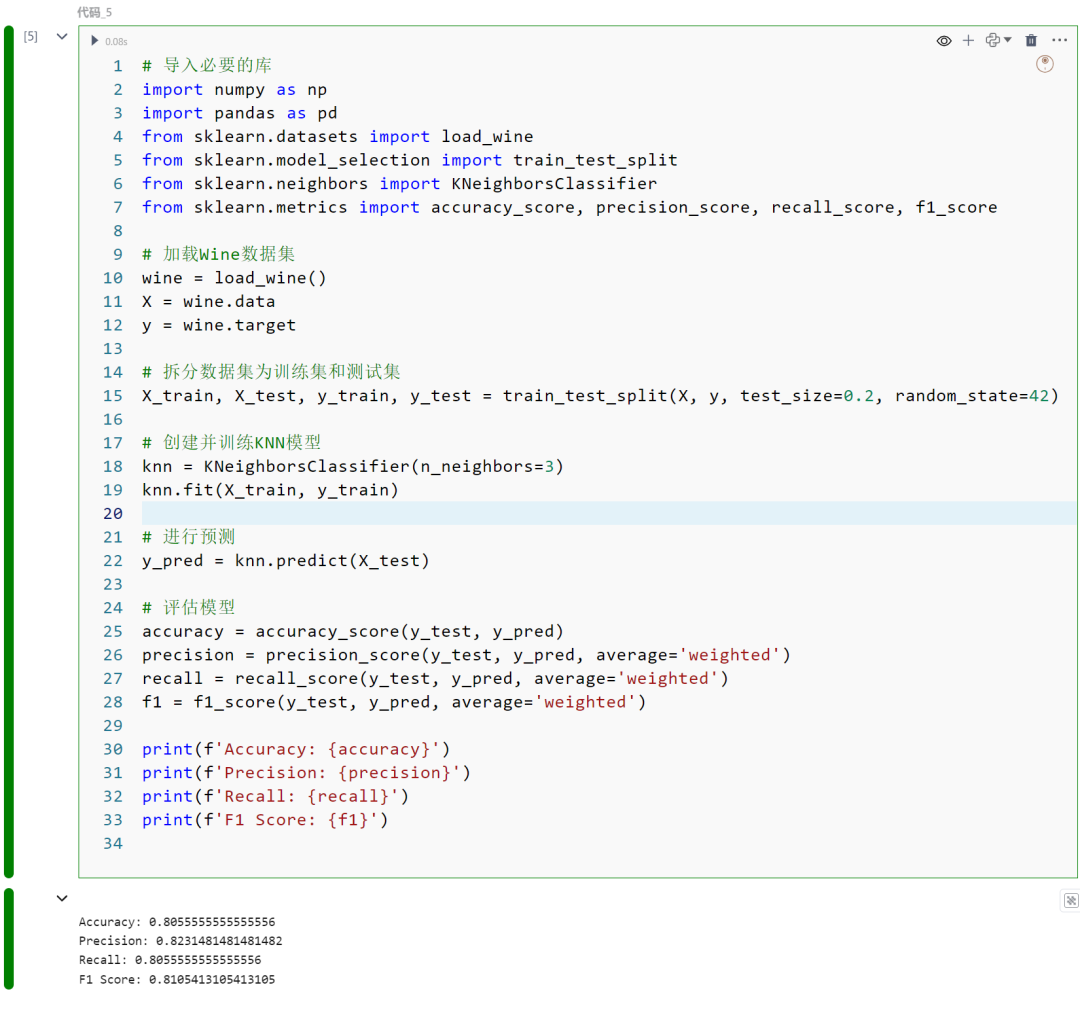
import numpy as npimport pandas as pdfrom sklearn.datasets import load_winefrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
wine = load_wine()X = wine.datay = wine.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
knn = KNeighborsClassifier(n_neighbors=3)knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)precision = precision_score(y_test, y_pred, average='weighted')recall = recall_score(y_test, y_pred, average='weighted')f1 = f1_score(y_test, y_pred, average='weighted')
print(f'Accuracy: {accuracy}')print(f'Precision: {precision}')print(f'Recall: {recall}')print(f'F1 Score: {f1}
')
6.支持向量机(Support Vector Machines,SVM)
支持向量机(Support Vector Machines,SVM)是一种强大且多功能的监督学习模型,用于分类和回归任务。它们在处理复杂数据集时表现良好。
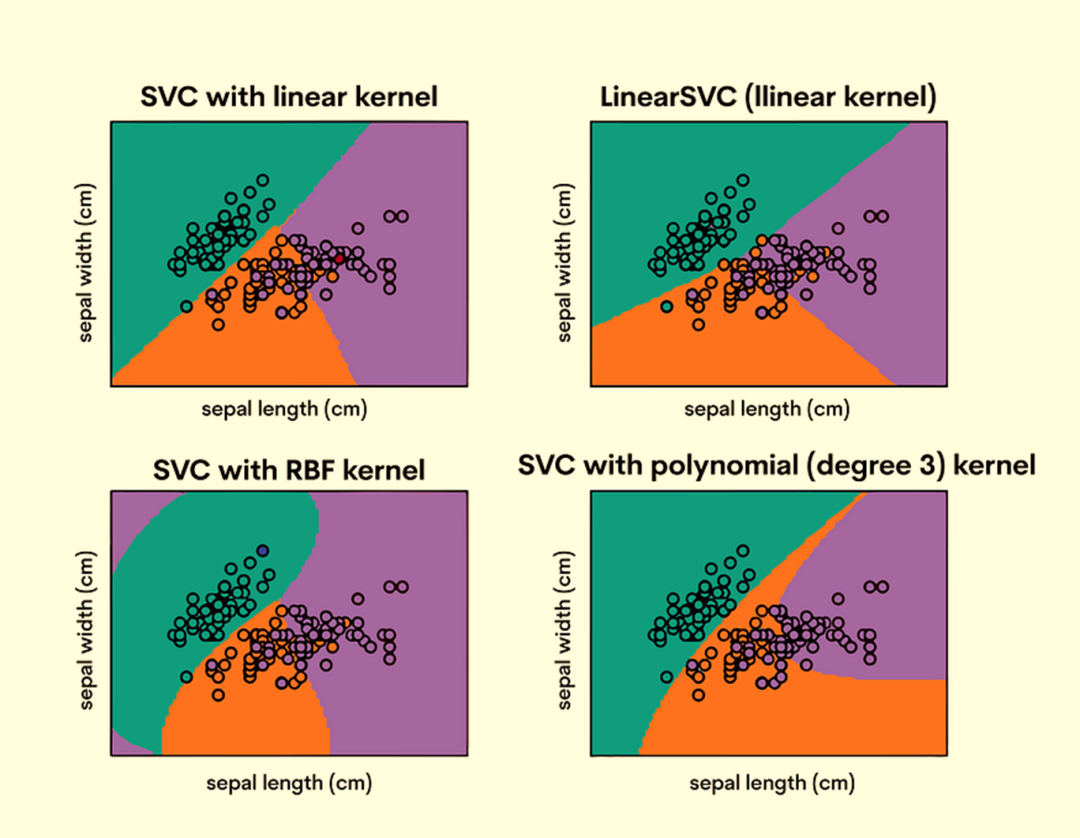
SVM在高维空间中构造一个超平面(或一组超平面)来分隔不同的类别。它旨在找到最好的边界(即线和每个类别最近点之间的距离,称为支持向量),以分隔各个类别。
评估指标:
-
分类:准确率、精确率、召回率、F1分数。
-
回归:均方误差(MSE)、R-squared。
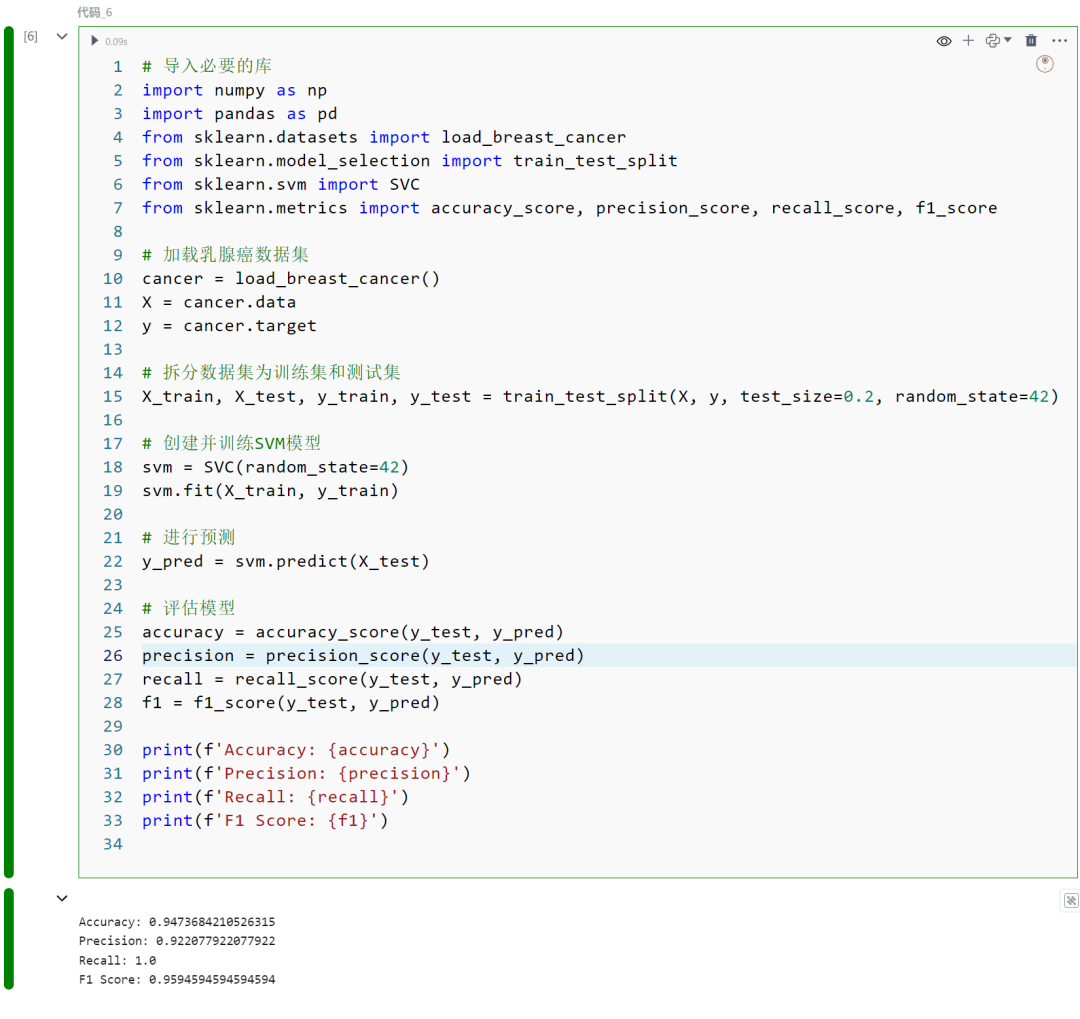
使用Sci-kit Learn及breast_cancer(乳腺癌数据集)进行SVM分类,重点是将肿瘤分类为良性或恶性。下面是基本步骤:
-
创建并训练SVM模型:使用默认设置创建一个支持向量机(SVM)模型。SVM以其能够在高维空间中创建分隔类别的超平面(或多个超平面)而闻名,并尽可能扩大边界。
-
进行预测:然后使用训练好的SVM模型预测测试数据的类别标签。通过确定每个数据点落在超平面的哪一侧来进行预测。
-
评估:将模型的预测结果与测试集的实际标签进行比较,以评估其性能。
import numpy as npimport pandas as pdfrom sklearn.datasets import load_breast_cancerfrom sklearn.model_selection import train_test_splitfrom sklearn.svm import SVCfrom sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
cancer = load_breast_cancer()X = cancer.datay = cancer.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
svm = SVC(random_state=42)svm.fit(X_train, y_train)
y_pred = svm.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)precision = precision_score(y_test, y_pred)recall = recall_score(y_test, y_pred)f1 = f1_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')print(f'Precision: {precision}')print(f'Recall: {recall}')print(f'F1 Score: {f1}')
7.随机森林(Random Forest)
最为常用的回归和分类的集成学习技术是随机森林(Random Forest)。它通过构建多个决策树并将它们组合来提供更可靠和准确的预测。
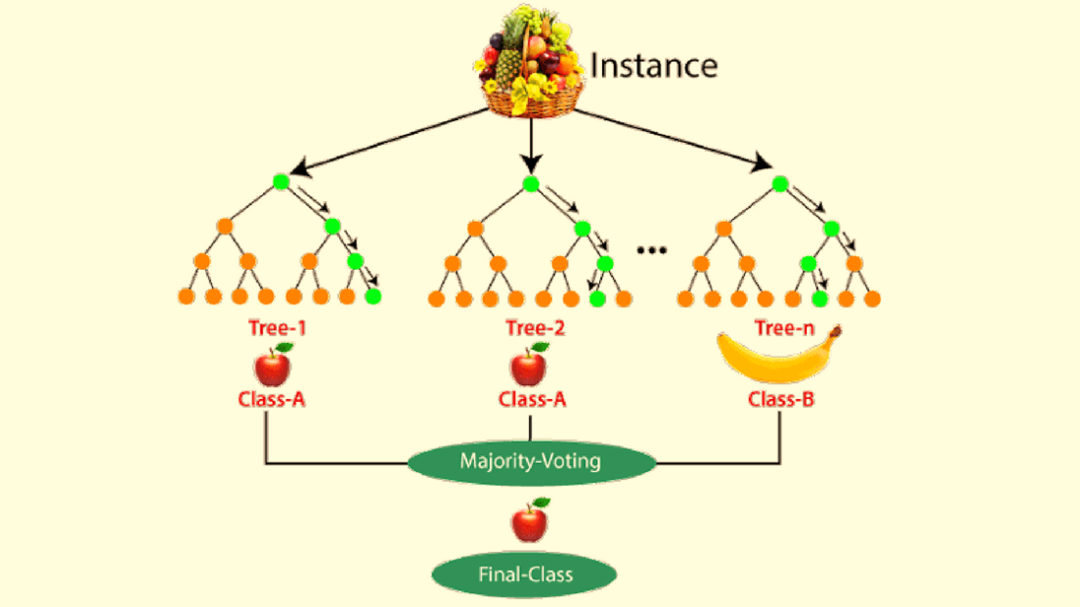
在随机森林中,每棵树都会做出预测,而模型的预测(对于分类)则属于获得最多投票的类别。对于回归,它取不同树输出的平均值。
评估指标:
-
分类:准确率、精确率、召回率、F1分数。
-
回归:均方误差(MSE)、R-squared。
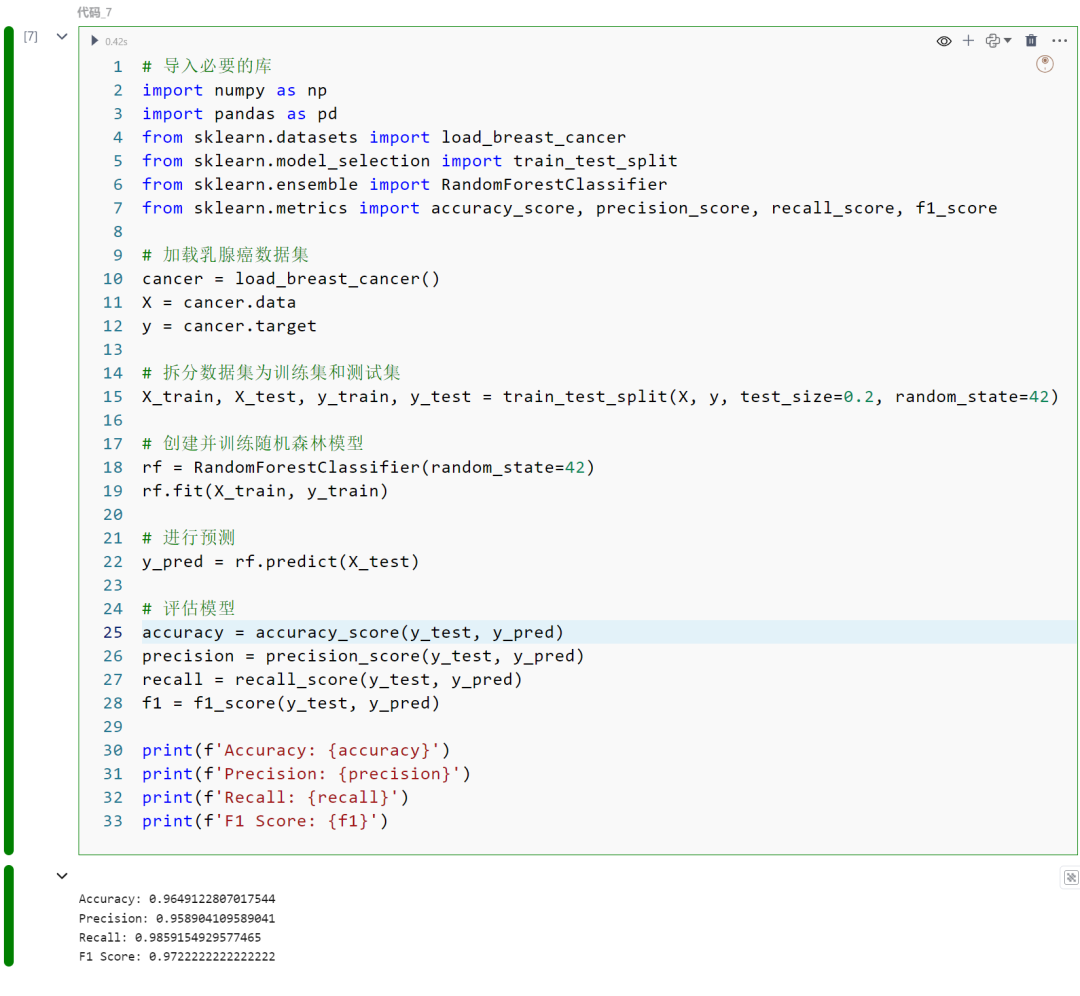
使用Sci-kit Learn及breast_cancer(乳腺癌数据集)进行随机森林(Random Forest)分类,重点是将肿瘤分类为良性或恶性。下面是训练随机森林模型、并使用分类指标评估其性能的流程和代码。
-
创建并训练随机森林模型:初始化一个随机森林分类器。使用训练数据拟合(训练)模型。
-
进行预测:使用训练好的模型预测测试数据的标签。
-
评估:使用准确率、精确率、召回率和F1分数评估模型在测试数据上的性能。
import numpy as npimport pandas as pdfrom sklearn.datasets import load_breast_cancerfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
cancer = load_breast_cancer()X = cancer.datay = cancer.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
rf = RandomForestClassifier(random_state=42)rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)precision = precision_score(y_test, y_pred)recall = recall_score(y_test, y_pred)f1 = f1_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')print(f'Precision: {precision}')print(f'Recall: {recall}')print(f'F1 Score: {f1}')
8.K均值聚类(K-Means Clustering)
K-Means聚类(K-Means Clustering)是一种无监督学习算法,用于将数据分组为“K”个簇。通过确定k个质心,每个数据点被分配到最接近的簇,目标是最小化质心的距离。
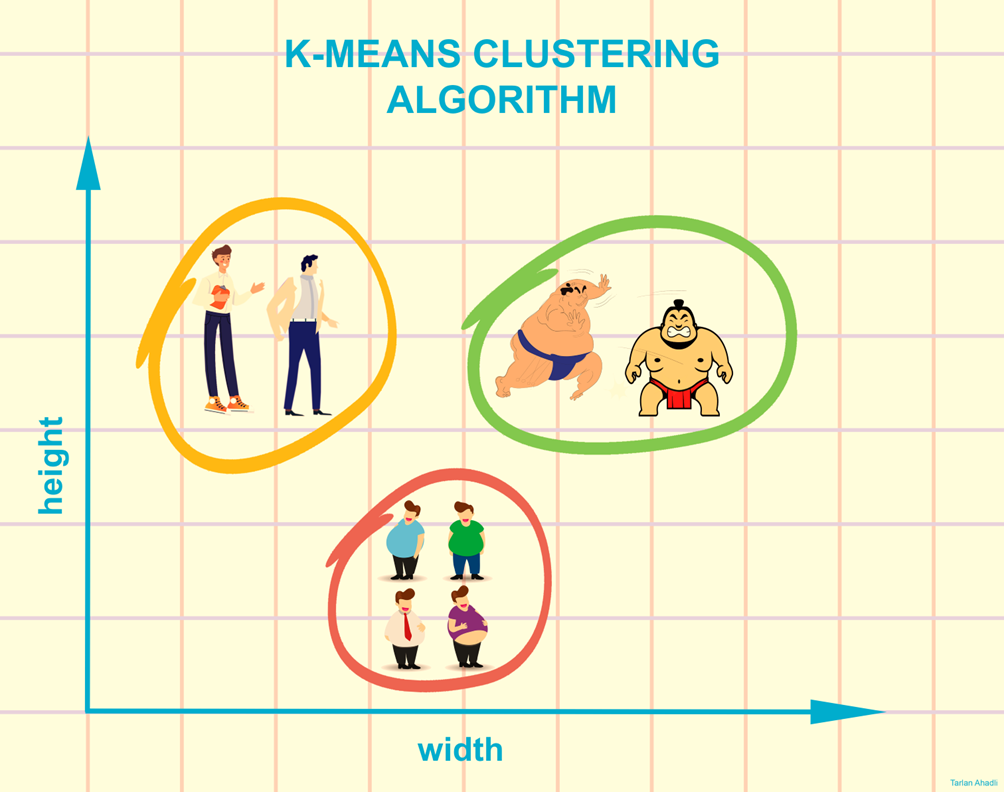
该算法将数据点分配到一个簇中,使得数据点和簇的质心之间的平方距离之和最小。簇内数据点的同质性随着簇内方差的减少而增加。
评估指标
使用Sci-kit Learn及Iris数据集进行K-Means聚类。任务是根据花的测量值将鸢尾花分组为不同的簇。下面是训练模型、分配簇,并评估聚类效果的流程和代码。
-
加载Iris数据集:Iris数据集包含鸢尾花的测量值,包括萼片长度、萼片宽度、花瓣长度和花瓣宽度。该数据集通常用于分类任务,但在这里将用于聚类。
-
应用K-Means聚类:初始化一个K-Means聚类算法,n_clusters=3,因为数据集中有三种鸢尾花物种。然而,算法并不知道这些物种;它只会尝试找到将数据分组为三簇的最佳方法。将模型拟合到包含四个特征的数据X上。K-Means算法通过质心到数据点的距离迭代地将每个数据点分配到三个簇中的一个。
-
预测簇:使用predict方法将X中的每个数据点分配到三个簇中的一个。这个步骤在K-Means中有些概念化,因为拟合和预测是一起发生的,但本质上每个数据点现在都被标记为一个簇号。
-
评估聚类:使用两个指标评估聚类:
• 惯性:这是样本到其最近簇中心的平方距离之和。它是衡量簇内部一致性的指标。目标是惯性越小越好。
• 轮廓系数:这衡量一个对象与其自身簇的相似度(内聚力)与其他簇的相似度(分离度)。轮廓系数范围为-1到1,值越高表示对象与自身簇匹配良好且与邻近簇匹配差。
import numpy as npimport pandas as pdfrom sklearn.datasets import load_irisfrom sklearn.cluster import KMeansfrom sklearn.metrics import silhouette_score
iris = load_iris()X = iris.data
kmeans = KMeans(n_clusters=3, random_state=42)kmeans.fit(X)
clusters = kmeans.predict(X)
inertia = kmeans.inertia_silhouette_avg = silhouette_score(X, clusters)
print(f'Inertia: {inertia}')print(f'Silhouette Score: {silhouette_avg}')

9.主成分分析(Principal Component Analysis,PCA)
主成分分析(Principal Component Analysis,PCA)是比较经典的降维算法,是将数据转换为一个新的坐标系统,减少变量的数量同时尽可能保留原始数据的变化。
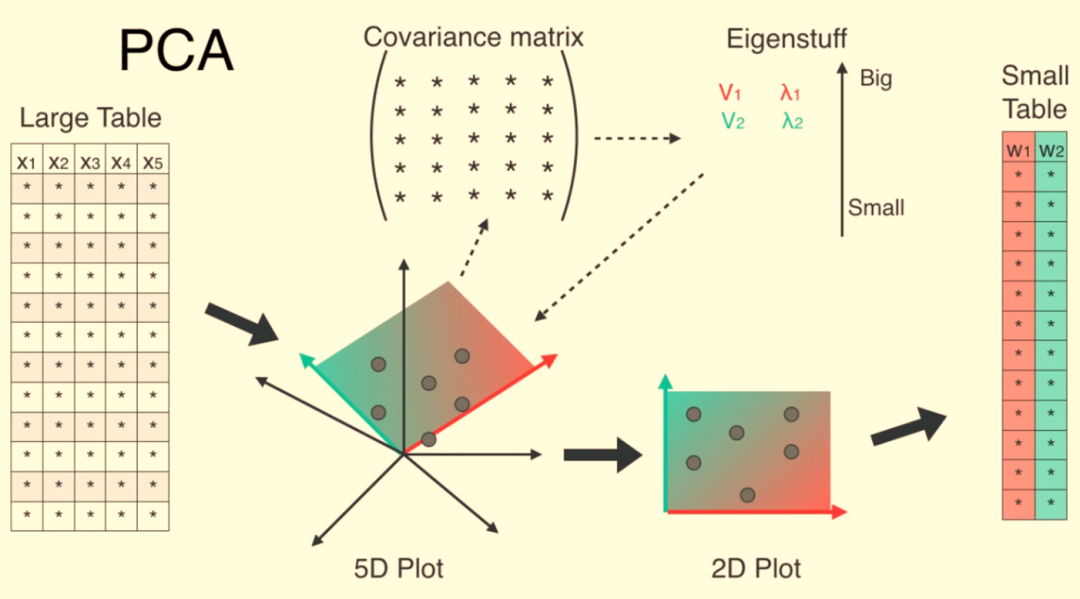
PCA识别出在数据中最大化方差的主成分或轴。第一个主成分捕捉最大的方差,第二个主成分(与第一个正交)捕捉次大的方差,依此类推。
评估指标:
-
解释方差:表示每个主成分捕捉的数据方差。
-
总解释方差:所选主成分累积解释的方差。
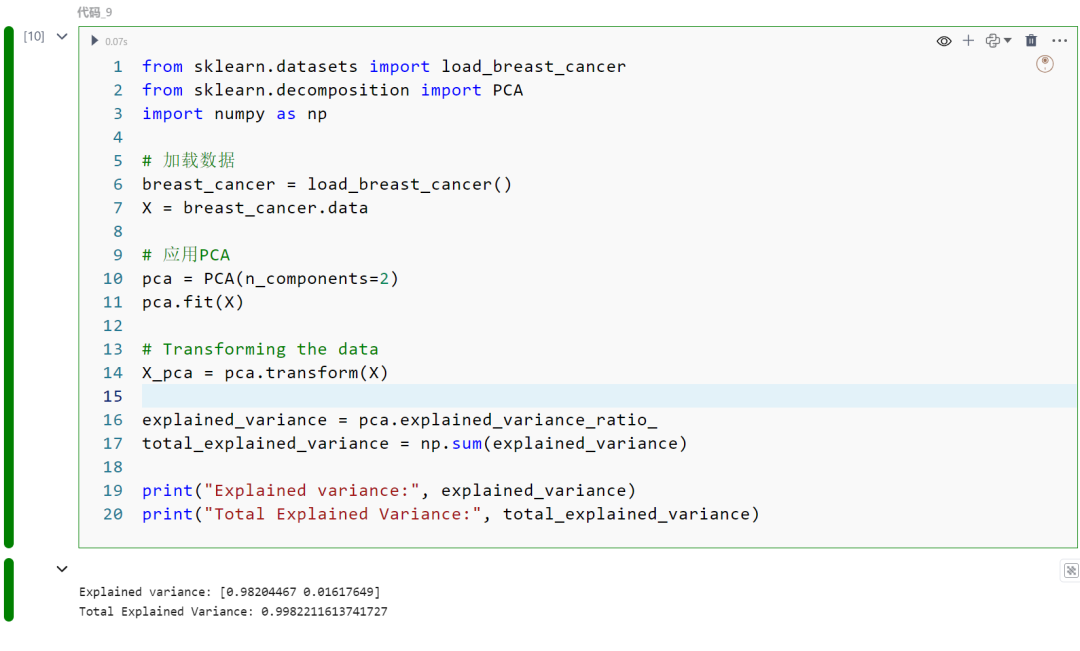
使用Sci-kit Learn及breast_cancer(乳腺癌数据集)进行PCA。该数据集包括从乳腺肿块的细针穿刺(FNA)数字图像中获取的特征,目标是在保留尽可能多的信息的同时,降低数据集的维度。以下是主要的流程和步骤:
-
加载乳腺癌数据集:乳腺癌数据集包括从乳腺肿块的细针穿刺图像中计算得出的特征。这些特征代表了可见图像中细胞核的属性。
-
应用PCA:使用n_components=2初始化PCA,将数据集降低到两个维度。这通常用于可视化或作为其他算法的预处理步骤。将PCA拟合到数据X,识别捕获最大方差的主成分。
-
转换数据:使用PCA的transform方法将数据X进行降维,得到一个新的数据集X_pca,其中每个数据点都用两个主成分表示。
-
评估PCA转换:通过检查每个主成分的解释方差来评估PCA转换,这指示每个成分捕获的数据方差量。计算总解释方差,通过对两个主成分的解释方差求和,提供降维过程中保留信息的整体度量。
from sklearn.datasets import load_breast_cancerfrom sklearn.decomposition import PCAimport numpy as np
breast_cancer = load_breast_cancer()X = breast_cancer.data
pca = PCA(n_components=2) pca.fit(X)
X_pca = pca.transform(X)
explained_variance = pca.explained_variance_ratio_total_explained_variance = np.sum(explained_variance)
print("Explained variance:", explained_variance)print("Total Explained Variance:", total_explained_variance)
10.梯度提升算法(Gradient Boosting Algorithms)
梯度提升(Gradient Boosting Algorithms)是一种先进的机器学习技术。它逐步构建多个弱预测模型(通常是决策树)。每个新模型逐渐减少整个系统的损失函数(误差)。
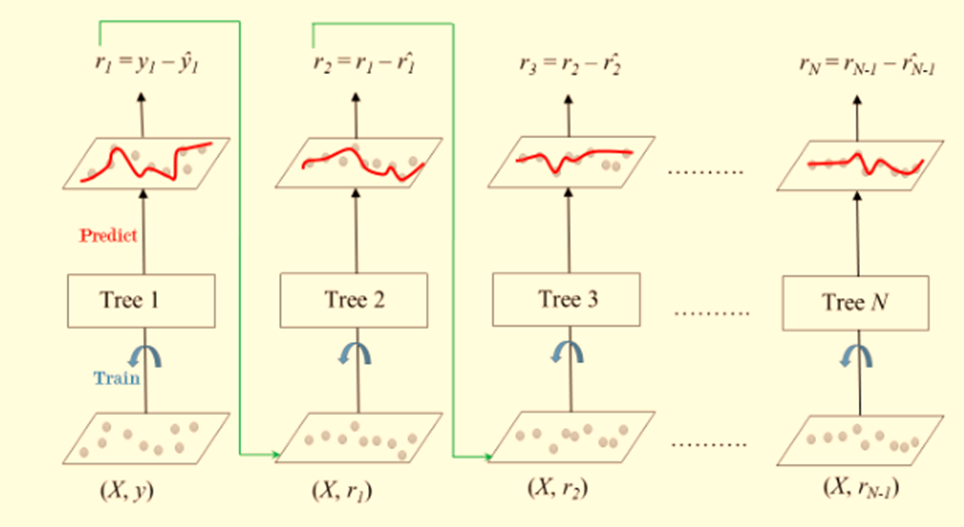
这种技术涉及三个主要组成部分:一个添加模型,用于逐步添加弱学习器以最小化损失函数;一个需要优化的损失函数;以及一个需要生成预测的弱学习器。每棵新树修正前面树所做的错误。
评估指标:
-
对于分类:准确率、精确率、召回率、F1分数。
-
对于回归:均方误差(MSE)、R平方。
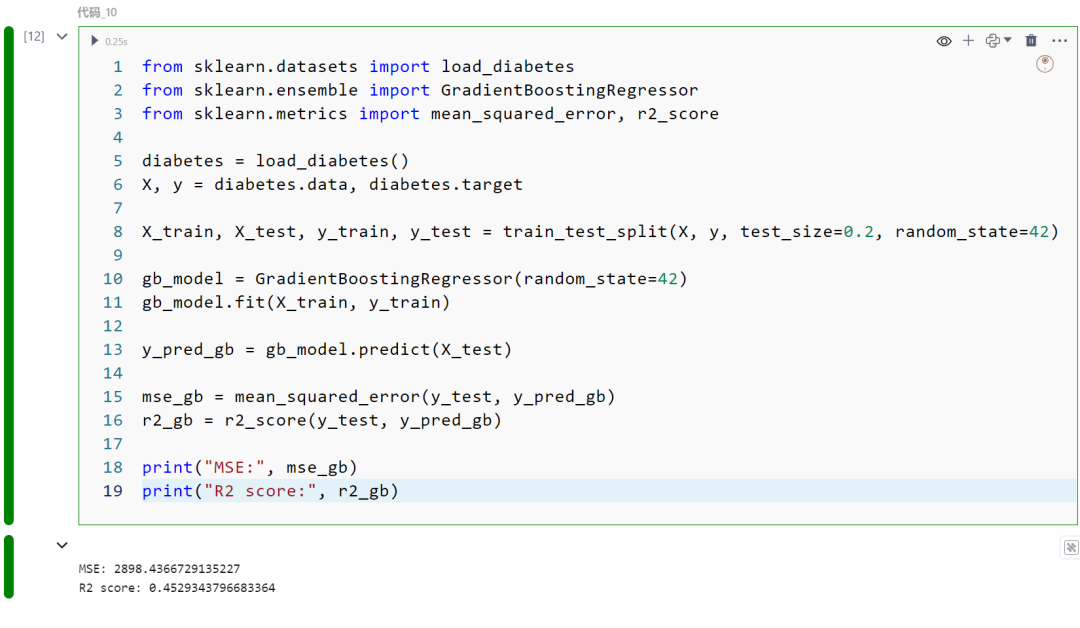
使用Sci-kit Learn及breast_cancer(乳腺癌数据集)进行梯度提升。目标是基于多种特征预测糖尿病的进展。将训练一个梯度提升模型并评估其性能。以下是将要执行的步骤:
-
加载糖尿病数据集:糖尿病数据集包括年龄、性别、体质指数、平均血压和六种血清测量等特征。目标变量是基线后一年疾病进展的量化评估。
-
创建和训练梯度提升模型:初始化一个梯度提升回归器。梯度提升允许优化任何可微分的损失函数,并以逐步前向方式构建一个添加模型。在训练数据上训练(拟合)这个模型。在这一步中,模型学习根据特征预测糖尿病的进展。
-
预测:使用训练好的梯度提升模型在测试数据上预测疾病进展。这一步涉及将模型应用于未见过的数据,以评估其预测能力。
-
评估:使用两个关键指标评估模型的性能:
• 均方误差(MSE):这个指标计算了误差的平方的平均值。它是评估估计器质量的指标;值越接近零表示质量越高。
• R平方:根据模型解释的总结果方差的百分比,此统计量指示观察到的结果如何被模型复制。
from sklearn.datasets import load_diabetesfrom sklearn.ensemble import GradientBoostingRegressorfrom sklearn.metrics import mean_squared_error, r2_score
diabetes = load_diabetes()X, y = diabetes.data, diabetes.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
gb_model = GradientBoostingRegressor(random_state=42)gb_model.fit(X_train, y_train)
y_pred_gb = gb_model.predict(X_test)
mse_gb = mean_squared_error(y_test, y_pred_gb)r2_gb = r2_score(y_test, y_pred_gb)
print("MSE:", mse_gb)print("R2 score:", r2_gb)
简单介绍了数据科学中十种常用的机器学习算法及它们的应用场景。涵盖了从线性回归、逻辑回归到决策树、朴素贝叶斯、K近邻、支持向量机、随机森林和K均值聚类等多个算法的使用方法及评估指标。每种算法都通过具体的示例展示了如何在实际项目中应用,从而帮助读者理解和选择适合的算法解决数据科学问题。





