 「每周一起读」是由 PaperWeekly 发起的协同阅读小组。我们每周精选一篇优质好文,利用在线协同工具进行精读并发起讨论,在碎片化时代坚持深度阅读。
「每周一起读」是由 PaperWeekly 发起的协同阅读小组。我们每周精选一篇优质好文,利用在线协同工具进行精读并发起讨论,在碎片化时代坚持深度阅读。
本期精读文章
An Empirical Study of Language CNN for Image Captioning
文章来源
https://arxiv.org/abs/1612.07086
推荐理由
本篇论文提出了用 CNN 模型来对单词序列进行表达,该 CNN 的输入为之前时刻的所有单词,进而可以抓住对生成描述很重要的历史信息。其中总体架构如下图所示:
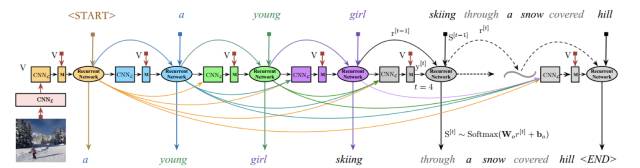
该模型主要由四部分组成,用于图像特征提取的 CNN_I,用于自然语言建模的 CNN_L,用于结合 CNN_I 和 CNN_L 信息的多模态层 M,和一个用于单词序列预测的递归神经网络。

总体过程如下:首先利用 CNN_I 提取图像特征,然后 CNN_L 利用之前时刻生成的单词对当前的单词信息进行表达,然后通过多模态层结合图像和单词信息,最后将融合的信息作为递归神经网络的输入来预测一下时刻的单词.该文与之前通过 one-hot 向量,然后经过词嵌入提取词向量的表达方法不同,利用了 CNN 网络来表达单词信息,进而能够很好的抓住过去的历史信息,用于指导当前时刻单词的生成。
>
>
>Gaolz<
<
<
个人认为这篇文章的总体思路沿用了目前的 encoder-decoder 的形式,decoder 仍然使用 LSTM、GRU,encoder 改为 CNN + language CNN 的 fusion layer。虽然没有提到目前比较火的 attention model,但我觉得和 attention model 的中一些形式有异曲同工之妙。
>
>
>XC3<
<
<
本文把 temporal cnn 用在 language 模型上很有创意,效果也很好,文章方法描述和训练过程写得也很详细,收获良多。
>
>
>ddguoll<
<
<
本文的创新点主要在于提出了 Language CNN,感知范围较 RNN 广一些,是一个很好的应用。但是,CNN 中的层次信息在哪里体现,在文中体现得不多。
>
>
>dengdan<
<
<
multimodal fusion layer 的 \sigma(gv(V, W_V, b_V)) 已经可以组成一个新的 layer 了。 如何确定 table1 中加入 CNN_L 后得到的提升不是由于加了这个一个 layer? 感觉应该修改或加一个对照组: 在原模型上也加一个 multimodal fusion layer, 但 fy() 的输出全为 0, 也就是说加入:m = \sigma(gv(V))。
rwang
:
language CNN 是这篇文章的核心。可是这一核心的 description 我很 confusing。(1)每一层的输出只有一个 feature map? (2) y_i^{l-1} and y_i^{l}是 row vector or column vector? (3) 'location i' 是 matrx 的哪一维?(4)w_L^{l}的 dimension size 是多少?与 y_i^{l-1}相乘时两者的维度是否 consistent?(5) w_L^{l}好像包含了所有的在 layer l 上的 kernal parameters。这里到底有多少个 kernal,每个 kernal size 是多大?(6)为什么每一层的输出的其中一个维度的大小都是 K?
xmyqsh
:
1)我也没找到关于输出的 feature map 的个数的描述,但是分析一下,feature map 的个数也就是 channel 数,这里的输入 channel 显然是 1,输入的 channel 数根据算法需要也应该是 1,至于 CNN_L 中间层的 channel 数就可以实验一下怎么设置合适了,我猜作者所有层的 channel 都设置成 1 了吧?(也就是每层都输出一个 feature map) 2)y^{l}是 M^{l} * K 维的,其中 K 是 word embedding 的维度,M^{l}的定义文章没有给出,应该就是第 l 层输出的一个 feature map 的维度,所以 y_i{l}是 row vector 3)location i 显然是 M^{l} 这一维的 4)w_L^{l} 的维度应该是 1 * kernelsize(不考虑 channel 数的话), 这里 eq。(7) 应该有问题,其中的 y_i{l-1} 应该改成 y{l-1}[i-kernelsize/2 : i+kernelsize/2] 5) 有多少个 feature map 就需要多少个 kernel, 文章没有讲需要多少个 feature map(或 kernel), kernel size 实验部分有讲,前两层 CNN kernel size 是 5, 后两层是 3 6)K 是 word embedding 的维度,这个必须保持不变才能不管怎么经过 CNN 的变换,元素都在 word embedding 的空间上。
XC3
:
我也尝试答一记, 如有问题请 @guijiuxiang 同学指正。@xmyqsh 同学答案很好了。 1. 本文中描述推断 feature map 是 1,但即便不是 1 也没关系,最后可以再 combine。2. \bold{y^(l-1)} 和 \bold{y^(l|) 都应该是 matrix,文中也提了属于 R^(M_l * K) , M_(l) 就是自定义的 neuron 数目。y_i^(l) 都是列向量,就是 i 个 neuron with dim size K。3. 就是 M_l * K 的第 i 行转置。 4. w_L^{l} 是一个 kernel, size 是 L,只要 L<16 应该就是可以的。 公式(7)里我觉得, 作者可能无意漏写了一个滑动卷积的过程,也就是说 M_l = M_(l-1) - sliding_window(L) + 1,当然如果是 valid padding 的话。5. w_L^{l}就是第 lth 层上的 kernel,下标 L,我猜可能是 size 吧。6. 这个 cnn 是 1D 的,他希望 model 字间上在 embedding 空间的关系, 所以他要保持 embedding 空间不能变。
pandabro
:
不知道作者有没有试过 end to end training?
gujiuxiang
:
没有试过,在训练时,首先利用 vgg-16 train language model,最后的结果是 fine-tune cnn (vgg-16) 的,可以看做 end-to-end。
xmyqsh
:
提到 transfer learning,要先明确三个定义,假设空间、样本空间、目标函数,目标函数由目标准则(比如交叉熵、KL 散度)和假设空间以及样本空间共同决定,这三者变一个,最优解都会变。我们把 vgg 从 imageNet transfer 到 image caption 的数据集,就是样本空间的改变导致了目标函数的变化,进而导致最优解的改变。 再说 VGG 和 ResNet,他们就是上面说的假设空间了,也可以叫模型(带参数)。不同假设空间可以不同程度的描述样本空间。 ResNet 实际是受到了 VGG 的启发,做更深的网络,并且解决了深层网络不好训练的问题。从结构上看,两者最终输出的 featuremap 大小一样,但是 ResNet 输出的 channel 数比 VGG 大了两倍(2048 vs 512),所以光从输出看,ResNet 的表达应该更丰富。 再看内部结构,ResNet 除了 shortcut,前两层 conv 的特殊处理,内部的 channel 数也比 VGG thin,导致 ResNet 需要拟合的参数量比 VGG 少(虽然 ResNet 网络结构复杂,更费显存),模型容量比 VGG 要小,并且比 VGG 容易训练,所以 ResNet 更不容易过拟合,另外 FLOPS 低,也更高效(不考虑网络结构对 GPU 加速影响的话)。 所以我觉得在假设空间的选择上,ResNet 应该全面压制 VGG,至于 GoogleNet,模型容量太小,表达能力不够丰富,更适合做分类,不好 finetune。 我觉得大家用 VGG 应该是因为在非分类任务上 VGG 比 GoogleNet 表现好,并且 VGG 简单,大家都用,好比较结果。而且这个任务的主要矛盾不是图片特征的提取,而是图片描述的生成。大家关注的重点在图片描述上。 总的来说,这个任务上 ResNet-50 或者 101 应该有更好的表现,大家可以试试。
yuliuhong
:
论文中作者提到 CNN_L 能够对句子的 hierarchical structure 建模,这个 hierarchical structure 表现的是句子的什么特征?句子语法结构特征?
xmyqsh
:









