说到数据分析,啤酒和尿布的例子大家应该都听腻了。再具体、深入一些的内容,往往因为数学就令很多人望而却步了。给大家分享9个不带数学推导的数据分析思路,希望大家能喜欢~
1. 分类
分类分析的目标是:给一批人(或者物)分成几个类别,或者预测他们属于每个类别的概率大小。
举个栗子:“京东的用户中,有哪些会在618中下单?”这就是个典型的二分类问题:买or不买。
分类分析(根据历史信息)会产出一个模型,来预测一个新的人(或物)会属于哪个类别,或者属于某个类别的概率。结果会有两种形式:
形式1:京东的所有用户中分为两类,要么会买,要么不会买。
形式2:每个用户有一个“会买”,或者“不会买”的概率(显然这两个是等效的)。“会买”的概率越大,我们认为这个用户越有可能下单。
如果为形式2画一道线, 比如0.5,大于0.5是买,小于0.5是不买,形式2就转变成形式1了。
2. 回归
回归任务的目标是:给每个人(或物)根据一些属性变量来产出一个数字(来衡量他的好坏)。
举个栗子:每个用户在618会为京东下单多少钱的?
注意回归和分类的区别在:分类产出的结果是固定的几个选项之一,而回归的结果是连续的数字,可能的取值是无限多的。
3. 聚类
聚类任务的目标是:给定一批人(或物),在不指定目标的前提下,看看哪些人(或物)之间更接近。
注意聚类和上面的分类和回归的本质区别:分类和回归都会有一个给定的目标(是否下单,贷款是否违约,房屋价格等等),聚类是没有给定目标的。
举个栗子:给定一批用户的购买记录,有没有可能分成几种类型?(零食狂魔,电子爱好者,美妆达人……)
4. 相似匹配
相似匹配任务的目标是:根据已知数据,判断哪些人(或物)跟特定的一个(一批)人(或物)更相似。
举个栗子:已知一批在去年双十一下单超过10000元的用户,哪些用户跟他们比较相似?
5. 频繁集发现
频繁集发现的目标是:找出经常共同出现的人(或物)。这就是大名鼎鼎的“啤酒和尿布”的例子了。 这个例子太容易扩展,就不再举栗子啦。
6. 统计(属性、行为、状态)描述
统计描述任务的目标是最好理解的:具有哪些属性的人(或物)在什么状态下做什么什么事情。
举个栗子:5月份一个月内每个用户在京东7天内无条件退货的次数
统计描述常常用户欺诈检测,试想一个用户一个月退货100+次,这会是一种什么情况?
7. 连接预测
连接预测的目标是:预测本应该有联系(暂时还没有)的人(或物)。
举个栗子:你可能认识xxx?你可能想看xxx?
8. 数据压缩
数据压缩的目的是:减少数据集规模,增加信息密度。
举个栗子:豆瓣想分析用户关于国外电影的喜好,讲国内电影的评分数据都排除掉
大数据,也不是数据越多越好,数据多带来的信息多,但是噪声也会变多。
9. 因果分析
顾名思义,因果分析的目标是:找出事物间相互影响的关系。
举个栗子:广告的效果提升的原因是广告内容好?还是投放到了更精准的用户?
这里最常见的手段就是A/B test啦
数据分析是非常强大的,不过当然还是要在具体的情景下,严格的选择假设,采用科学的分析方法才能产出有价值的结果。数据会说谎的经典案例就是“安慰剂效应”了。
数据分析对于运营来说是一个数据抽象的过程。
现实情况是连续的、复杂的、互相影响的,而数据抽象的过程,就是将这些复杂多变的现实情况简化为数字量,搭建数据模型,计算相关因子,推断事件归因,并推进自身改进优化。
由于现实的复杂性,我们作为产品、运营或者数据分析师,在实际问题处理时,就需要做归因分析,需要屏蔽其他因子的干扰,因此我们常常使用用户分群。
分群后,我们的用户群可能简化为:
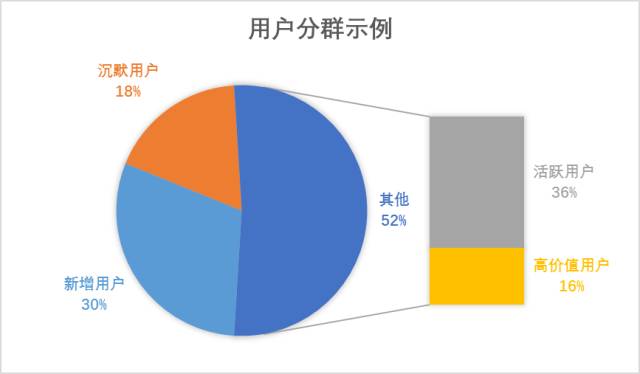
在每一个分群下,我们可以简化地对比某个因素对关键路径或者关键指标的影响因素。
分群是手段,是工具,简单来说,分群分析就是通过聚类的方式,把相似的人群合并,考察同一事件或同一指标在不同人群上的表现,以推断并定位对该事件/指标有明显影响的因子。
我们将用户精细分群与用户画像结合起来,助力精益化运营的深度与精度。
细分目标人群,结合用户画像的实践
那么,用户分群与用户画像如何结合使用?
接下来,我们举个App案例进行说明:
某电商App,现在面临的问题是用户成交量较低,与投放推广的成本相比,ROI较低。
这个问题,我们应该如何分析?
首先,我们想看看成交的这部分用户与大盘用户之间有什么区别。我们在用户中选出成交的用户,建立用户群对比大盘用户。
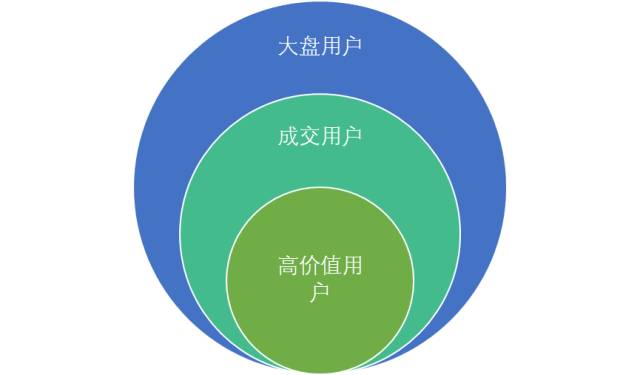
此处定义高价值用户为成交单价>100元的用户。
1. 用户分群分析
得到了三个用户群之后,我们使用数据分析工具,对比这三个用户群特点间的区别。
以下为三个用户群特征的对比:
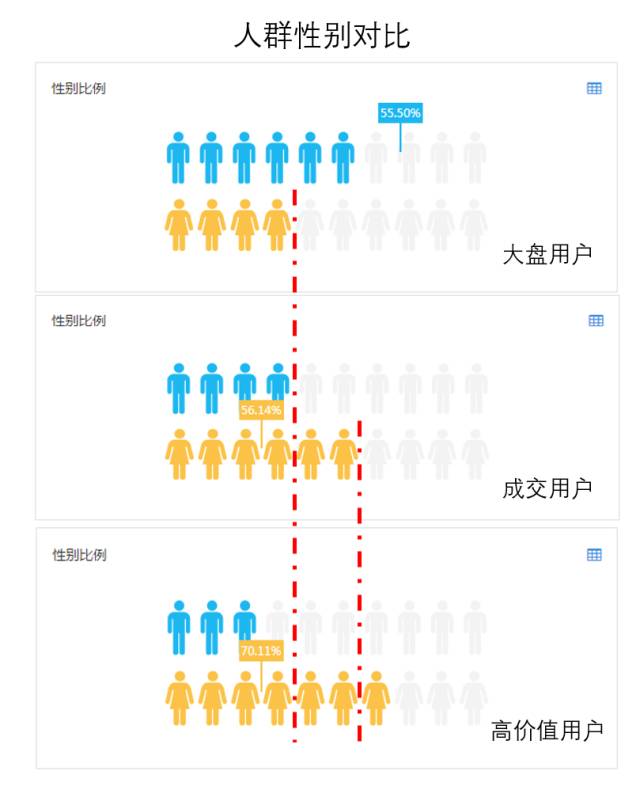
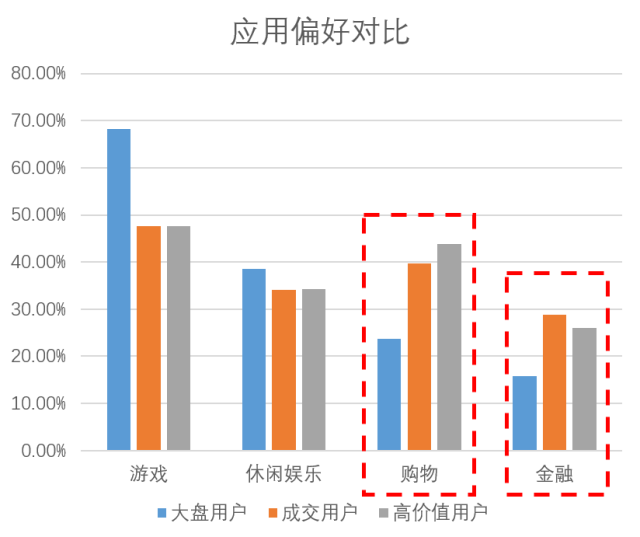
从图中我们可以发现,大盘用户中男性较多,但实际成单与高价值用户中,都是女性偏多,且此部分用户对购物类App、金融类App的兴趣要明显高于大盘用户,表现出了较强的消费能力。
现在我们的问题是投放回报率较低,ROI不符合预期。
那么,我们可以初步判断,可以优化的有以下两个方向:
-
用户引流渠道可能有问题,需要调整渠道引流策略,包括渠道选择、人群针对性优化等,引入与消费行为匹配的新用户群,提高销售量;
-
商品定位的调整:现有产品对男性的吸引力不足,导致大量大盘用户并没促成成单,这也是导致ROI较低的另一方面原因,可能需要调整的包括商品品类、商品推荐等;
其中,第一种优化方式的见效周期较短,而第二种调整方式相对影响层面较大、周期较长。我们优先实践第一种优化方式,以调整渠道引入流量为主,优化引入人群的匹配程度,实现提高ROI的目标。
后续还需要斟酌是否需要优化产品定位,比如打造针对男性的亮点频道,进行产品改善迭代。
2. 渠道优化策略
那么,渠道应该如何做改善?我们先对单周渠道引入量的数据,进行初步评估。
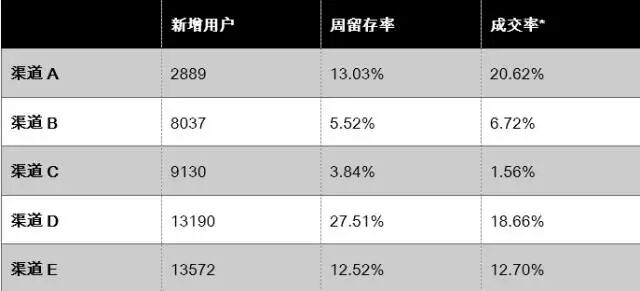
从图表上看,我们当前主要的流量渠道是渠道D与渠道E,而且渠道D的留存率很高,可以认为是我们的优质渠道。
但从成交上看,我们认为渠道A其实有很大的潜力,虽然现在的引入量较小,但与成交人群重合度较高,考虑到A渠道的获客成本低于渠道D,加大投放之后很可能会有一个不错的收益,能够实现我们提高ROI的目标。
3. 渠道人群画像验证
我们对渠道人群A进行画像分析,女性比例高达62.36%,其用户群对购物类App的兴趣也高于大盘用户,与我们高价值人群特征匹配度较高。
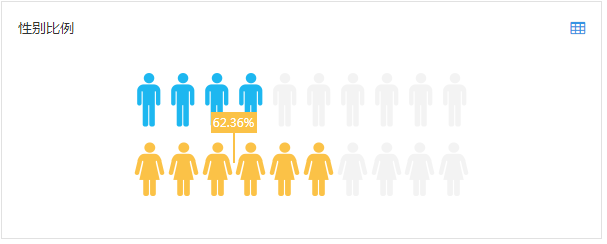
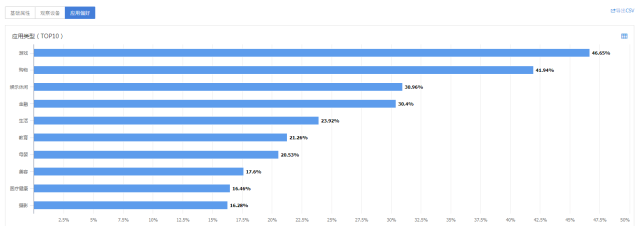
现在渠道A给我们带来的流量还比较小,但由于其渠道收益上ROI比例较高,且其群体画像与我们高价值用户的画像吻合度高,表现出了很高的投放潜力。
我们的改善方法是:调整渠道投放的比例,减少渠道B、渠道C的投放,增强渠道A的投放,以周为单位,迭代优化渠道投放效果,并监测ROI的变动。
4. 渠道投放优化效果
在投放一周后,对新增用户有了增长,我们临时决议再次加大渠道A的投放比例。
这里是一个月的时间周期内,我们的新增用户数在渠道上的分布有了显著变化。
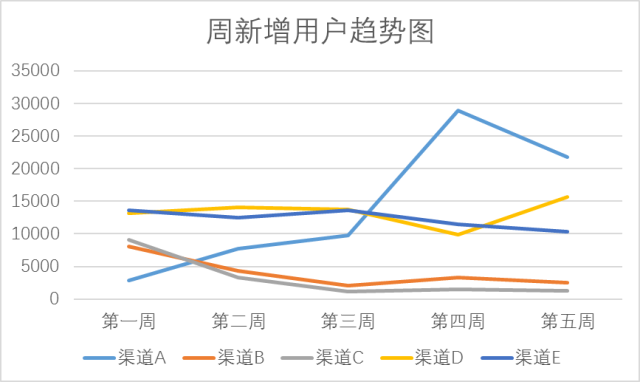
优化投放渠道前后,购买转化漏斗转化率的改变:
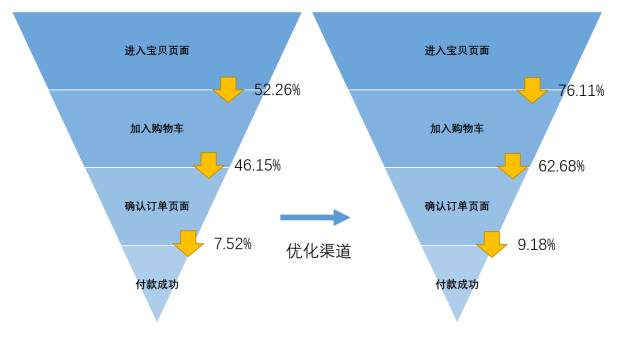
由于渠道A的平均客单价约是渠道D的1/2~1/3,我们的投入产出比例得到了优化。这主要依赖于通过数据分析找到了优质低价的渠道,降低了获客成本。
细分漏斗画像,改善关键节点
通过数据挖掘,我们发现了优质渠道A,其用户群与我们的高价值用户比较吻合,同时平均客单价约是原有主要渠道D的1/2~1/3,我们的投入产出比例得到了优化。
这主要依赖于通过数据分析找到了优质低价的渠道,降低了获客成本。
漏斗改进效果如下图:
那么,这个漏斗是否存在其他可以改进的地方呢?
当然有!我们的现实世界并非是简单的数据逻辑结构,很多结果都是多种原因综合导致的,我们可以用多种角度去分析同一个问题。
下面我们将结合漏斗分析与用户分群来做一个深度分析,通过漏斗的细致拆分和交叉对比,定位问题所在。
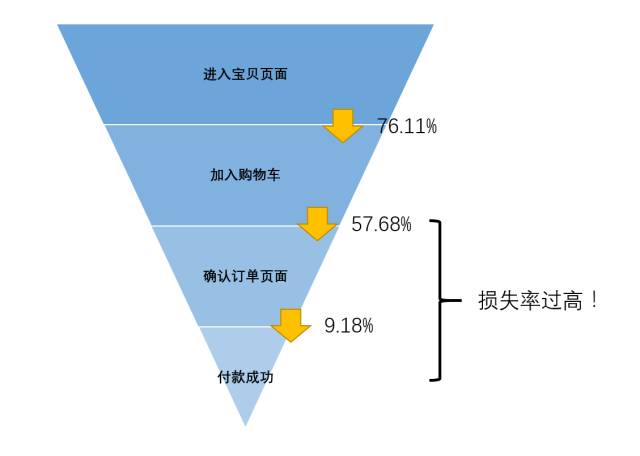
1. 漏斗分析
那我们就从这个漏斗开始分析:从上面都是漏斗中,我们可以看到,加入购物车之前的转化率都较高,但在购物付款的流程中,转化率急剧降低至14.65%,这里应该也有改进的空间。
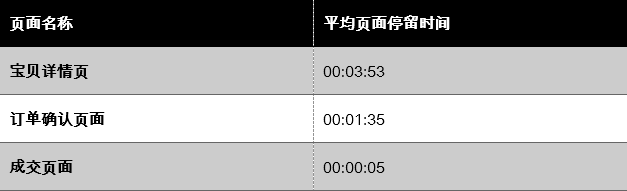
我们再看页面浏览数据,可以发现,用户在订单确认页面停留的时间长达95秒,这与我们平时的认知不相符。
2. 漏斗拆分
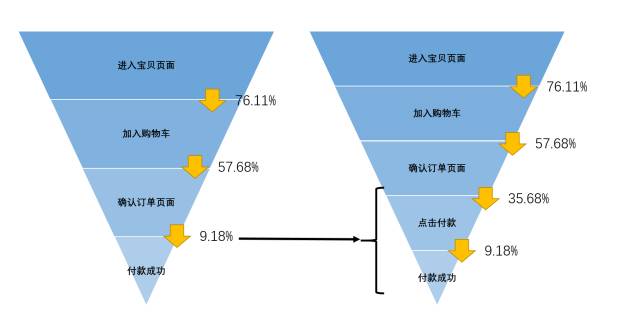
为了验证我们的假设,我们建立两个小用户群——“确认要付款的人群”&“成功付款的人群”,即把漏斗中“订单人群”到“付款人群”进行了拆分,把确认付款的动作独立出来。
我们能够发现,在“确认要付款”到“成功付款”确实是损失转化的主要环节。
3. 分群分析
我们看这群“确认付款”&“未成功付款”的人群:
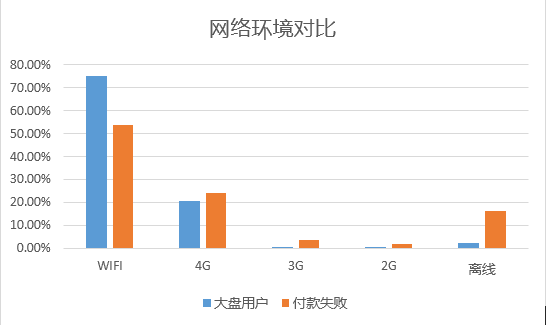
通过几个人群的对比,我们发现“付款失败”组的人群离线环境陡增约14%,另外,其3G、2G网络的比例要高于大盘人群(5.68% vs. 1.36%),且设备品牌中,相对机型较小众、低端。
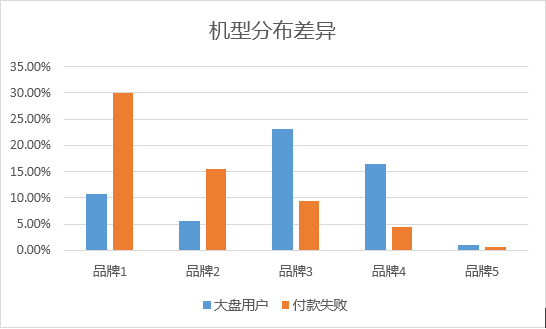
我们实际测试了品牌1和品牌2的实际几个机型,主要针对的就是付款页面的页面体验,存在以下问题:
于是我们做了以下改善:
-
紧急修复版本,在小众机型的主要推广渠道上升级了版本适配性的App;
-
页面加载量优化,包括切割、压缩、删减图片,框架优化,预加载等策略,恶劣网络下加载速度提升至约15秒;
-
加载等待页面设计,增加了动画的等待页面,给用户卖个萌,增加用户等待的耐心。
4. 效果验证
页面优化后,我们的漏斗转化流程有明显改善:
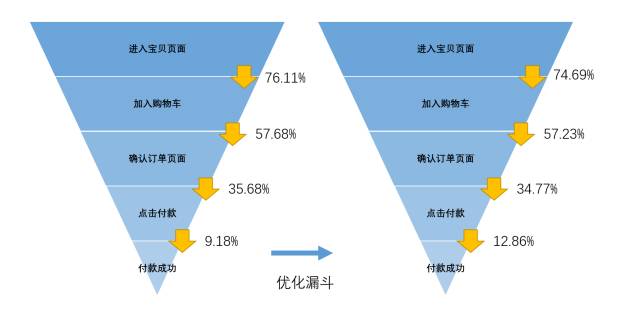
我们针对这群“付款失败”用户群所做的改善,为转化漏斗提高了3%的转化效率,这是非常大的一个收益。另外,我们在后续的漏斗改进中,还尝试结合了页面点击/页面流转的分析,删去了付款页面中不必要的信息、按钮,保证了付款流程的顺畅性,对于提升漏斗也有一定的作用。
5. 总结一下
数据运营的优化思路其实就是通过细致拆分,把复杂的、多因子的事件分析拆分为独立的、单因子的归因分析,以确定改进的思路。
via:荆花知了窝
在9月12日~22日购买小蚊子数据分析系列视频课程(Excel、SPSS、R、Python等),可享三重优惠:5-8折、用券、赠书

点击“
阅读原文
”进入活动页面





