人脸关键点包括眼睛的角、鼻尖、耳叶口角等。需要这些来进行表面对准,其对于人脸识别/验证非常重要。头部姿势另一个重要的利益信息。人脸关键点检测方法可分为两个类型:基于模型和基于回归。
基于模型的方法
在训练过程中创建形状的表达,在测试过程中使用该方法来配合人脸。基于模型的方法包括:PIFA和3DDFA。Jurabloo等人考虑人脸对齐作为密集3D模型拟合问题并使用用于估计相机的基于DCNN的正则表达式的级联投影矩阵和3D形状参数。Antonakos等人使用基于多个图形的成对法线建模的外观修补程序之间的分布。基于级联回归的方法将图像外观直接映射到目标输出。Zhang等人使用了级联,几个连续的堆叠自编码器网络。该方法细化从第一个堆叠中获得的粗略位置使用后续网络的自动编码器网络。Bulat等人。还首先对每个人脸关键点进行粗略定位,然后对其进行细化检测结果。同样,Sun公司提出的方法[
Y. Sun, X. Wang, and X. Tang, “Deep convolutional network cascade for facial point detection,” in IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 3476–3483
]每个级别的多个网络的融合输出级联。
另一种方法
基于回归
是级联组成学习(CCL)[
S. Zhu, C. Li, C.-C. Loy, and X. Tang, “Unconstrained face alignment via cascaded compositional learning,” in IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 3409–3417
]。库马尔提出了一种用于关键点估计的迭代方法和姿势预测。Georgis等人提出的方法联合训练一个卷积递归神经网络。在另一项工作中,Kumar等人[
A. Kumar, R. Ranjan, V. Patel, and R. Chellappa, “Face alignment by local deep descriptor regression,” arXiv preprint arXiv:1601.07950, 2016
]开发了一种用于关键点定位的CNN。
300 Faces In-the-Wild database(300W)[
C. Sagonas, E. Antonakos, G. Tzimiropoulos, S. Zafeiriou, and M. Pantic, “300 faces in-the-wild challenge: Database and results,” Image and Vision Computing, vol. 47, pp. 3–18, 2016
]是对不同面部检测方法进行公平比较的基准。它组合并扩展了几个以前可用的数据集,LFPW、Helen、AFW、iBug和600个测试图像。

人脸识别/ 验证系统有两个主要部分:1) 鲁棒人脸表示;2) 分类器(在识别的情况下) 或相似性度量(用于验证)。
当使用大型数据集进行训练时,深度网络能够学习判别特征。[
G. B. Huang, H. Lee, and E. Learned-Miller, “Learning hierarchical representations for face verification with convolutional deep belief networks,” in IEEE International Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2012, pp. 2518–2525
]使用基于局部受限Boltzmann的卷积深信念网络学习人脸表示。它们的模型在LFW数据集上获得了良好的性能,而不需要大量标注的人脸数据集。另一方面,塔格曼等人使用一个由4000多个身份的400万张脸组成的专用脸数据集来训练一个九层深网络(DeepFace)[
Y. Taigman, M. Yang, M. A. Ranzato, and L. Wolf, “Deepface: Closing the gap to human-level performance in face verification,” in IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 1701–1708
]。他们没有使用标准的卷积层,而是使用了几个局部连接的层而没有权重共享。同样,FaceNet[
F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” arXiv preprint arXiv:1503.03832, 2015
]也接受了关于大约800万张身份的2亿张图像的数据集的培训。它直接优化了嵌入本身,使用了大致对齐匹配/非匹配的三重人脸贴片。DeepID框架[
Y. Sun, X. Wang, and X. Tang, “Deep learning face representation from predicting 10000 classes,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 1891–1898
]、[
Y. Sun, Y. Chen, X. Wang, and X. Tang, “Deep learning face representation by joint identification-verification,” in Advances in Neural Information Processing Systems, 2014, pp. 1988–1996
]、[
Y. Sun, X. Wang, and X. Tang, “Deeply learned face representations are sparse, selective, and robust,” arXiv preprint arXiv:1412.1265, 2014
]使用了比DeepFace或FaceNet更小的深卷积网络集合。每个DCNN由四个卷积层组成,并接受了大约20万张大约10000个身份的图像的训练。使用一组模型和大量不同的身份有助于DeepID学习鉴别人脸表示,从而使其能够在LFW数据集上实现超人人脸验证性能。
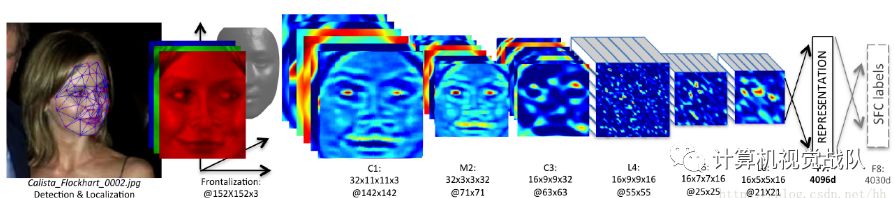
学习分类器或相似性度量是获取鲁棒人脸特征的下一步。对于人脸验证,属于同一个人的两张人脸的特征应该是相似的,而属于不同人的人脸的特征应该是不同的。
最近的一些工作提出了在训练损失函数或网络设计中编码这一要求的方法。第一种方法使用图像对来训练一个特征嵌入,其中正对更近,负对更远。Hu等人[
J. Hu, J. Lu, and Y.-P. Tan, “Discriminative deep metric learning for face verification in the wild,” in IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 1875–1882
]使用深层神经网络学习一种判别尺度。[
S. Sankaranarayanan, A. Alavi, C. Castillo, and R. Chellappa, “Triplet probabilistic embedding for face verification and clustering,” arXiv preprint arXiv:1604.05417, 2016
]使用三重子损失将DCNN特征嵌入到区分子空间中。这导致了人脸验证方面的性能改进。
另一种方法是修改常用的交叉熵损失,以纳入判别约束。温等人[
Y. Wen, K. Zhang, Z. Li, and Y. Qiao, “A discriminative feature learning approach for deep face recognition,” in European Conference on Computer Vision (ECCV), 2016, pp. 499–51
]介绍了学习判别人脸嵌入的中心损失。Ranjan等人介绍了crystal loss[
R. Ranjan, A. Bansal, H. Xu, S. Sankaranarayanan, J.-C. Chen, C. D. Castillo, and R. Chellappa, “Crystal loss and quality pooling for unconstrained face verification and recognition,” arXiv preprint arXiv:1804.01159, 2018
],它在Softmax损失之前使用了特征归一化和缩放。类似地,DeepVisage[
M. A. Hasnat, J. Bohne, J. Milgram, S. Gentric, and L. Chen, “Deepvis- ´ age: Making face recognition simple yet with powerful generalization skills.” in ICCV Workshops, 2017, pp. 1682–1691
]使用批处理规范化的特例来规范这些特性。SphereFace[
W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song, “Sphereface: Deep hypersphere embedding for face recognition,” IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2017
]提出的angular softmax,它产生角分辨特征。CosFace[
H. Wang, Y. Wang, Z. Zhou, X. Ji, Z. Li, D. Gong, J. Zhou, and W. Liu, “Cosface: Large margin cosine loss for deep face recognition,” arXiv preprint arXiv:1801.09414, 2018
]L2对特征和权重进行归一化以消除径向变化,并引入余弦裕度项来最大化角空间中的决策裕度。










