
igel 是 GitHub 上的一个热门工具,基于 scikit-learn 构建,支持 sklearn 的所有机器学习功能,如回归、分类和聚类。用户无需编写一行代码即可使用机器学习模型,只要有 yaml 或 json 文件,来描述你想做什么即可。

一行代码不用写,就可以训练、测试和使用模型,还有这样的好事?
最近,软件工程师 Nidhal Baccouri 就在 GitHub 上开源了一个这样的机器学习
工具——igel,并登上了 GitHub 热榜。目前,该项目 star 量已有 1.5k。
项目地址:
https://github.com/nidhaloff/igel
该项目旨在为每一个人(包括技术和非技术人员)提供使用
机器学习
的便捷方式。
项目作者这样描述创建 igel 的动机:「有时候我需要一个用来快速创建
机器学习
原型的工具,不管是进行概念验证还是创建快速 draft 模型。我发现自己经常为写样板代码或思考如何开始而犯愁。于是我决定创建 igel。」
igel 基于 scikit-learn 构建,支持 sklearn 的所有
机器学习
功能,如回归、分类和聚类
。用户无需编写一行代码即可使用
机器学习
模型,只要有 yaml 或 json 文件,来描述你想做什么即可。
其基本思路是在人类可读的 yaml 或 json 文件中将所有配置进行分组,包括模型定义、数据预处理方法等,然后让 igel 自动化执行一切操作。用户在 yaml 或 json 文件中描述自己的需求,之后 igel 使用用户的配置构建模型,进行训练,并给出结果和元数据。
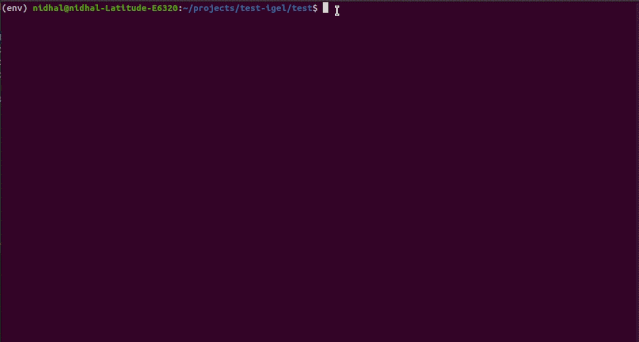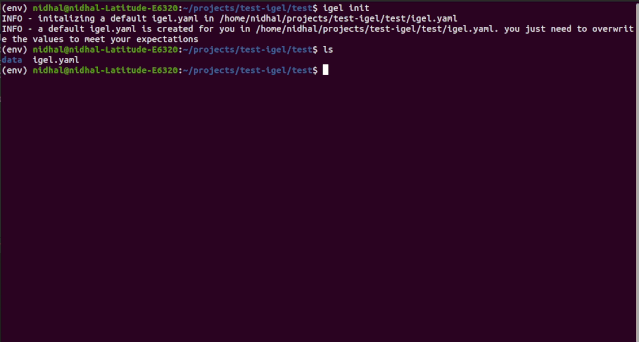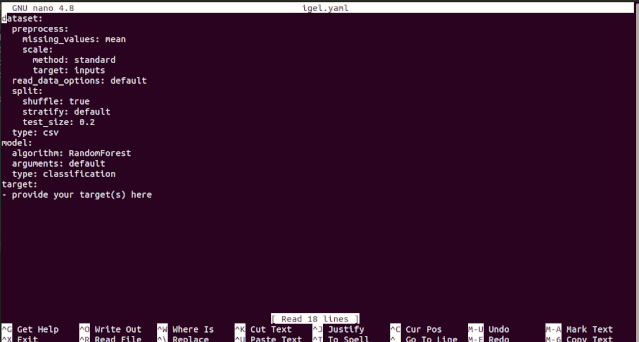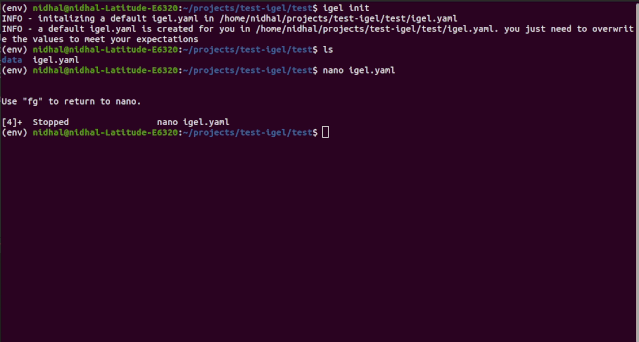
dataset: type: csv read_data_options: sep: delimiter: header: names: index_col: usecols: squeeze: prefix: mangle_dupe_cols: dtype: engine: converters: true_values: false_values: skipinitialspace: skiprows: skipfooter: nrows: na_values: keep_default_na: na_filter: verbose: skip_blank_lines: parse_dates: infer_datetime_format: keep_date_col: dayfirst: cache_dates: thousands: decimal: lineterminator: escapechar: comment: encoding: dialect: delim_whitespace: low_memory: memory_map:
split: test_size: 0.2 shuffle: true stratify: None
preprocess: missing_values: mean encoding: type: oneHotEncoding scale: method: standard target: inputs
model: type: classification algorithm: NeuralNetwork arguments: use_cv_estimator: false cross_validate: cv: n_jobs: verbose: hyperparameter_search: method: grid_search parameter_grid: param1: [val1, val2] param2: [val1, val2] arguments: cv: 5 refit: true return_train_score: false verbose: 0
target: - put the target you want to predict here - you can assign many target if you are making a multioutput prediction
如前所示,igel 支持回归、分类和聚类
模型,包括我们熟悉的线性回归
、贝叶斯回归、支持向量机
、Adaboost、梯度提升
等。

为了让大家快速上手 igel,项目作者在「README」文件中提供了详细的入门指南。
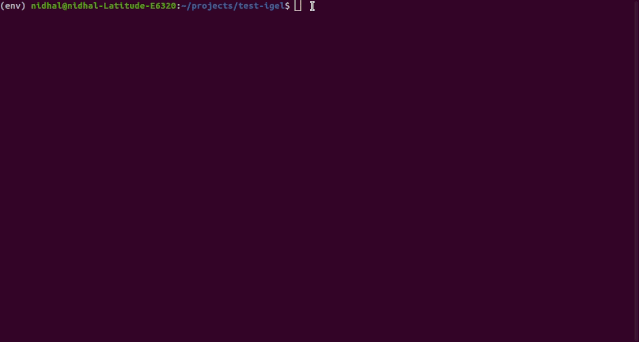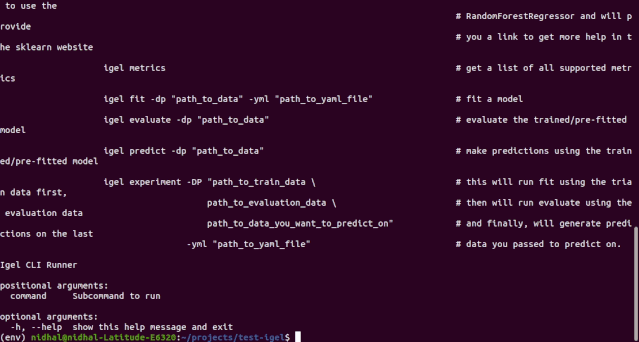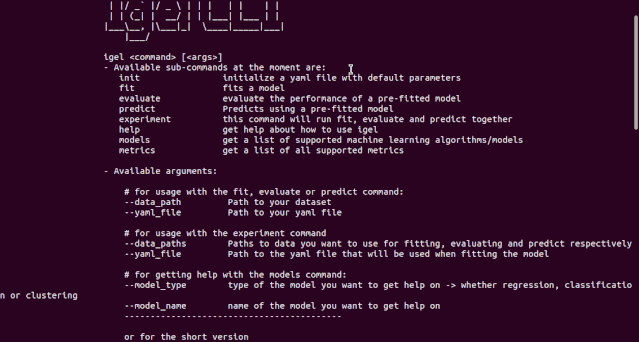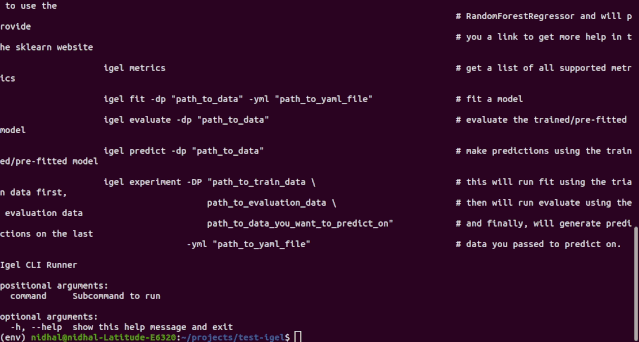
$ igel --help
$ igel -h"""Take some time and read the output of help command. You ll save time later if you understand how to use igel."""
第一步是提供一份 yaml 文件(你也可以使用 json)。你可以手动创建一个. yaml 文件并自行编辑。但如何你很懒,也可以选择使用 igel init 命令来快速启动:
"""igel init possible optional args are: (notice that these args are optional, so you can also just run igel init if you want)-type: regression, classification or clustering-model: model you want to use-target: target you want to predict
Example:If I want to use neural networks to classify whether someone is sick or not using the indian-diabetes dataset,then I would use this command to initialize a yaml file:$ igel init -type "classification" -model "NeuralNetwork" -target "sick""""$ igel init
运行该命令之后,当前的工作目录中就有了一个 igel.yaml 文档。你可以检查这个文件并进行修改,也可以一切从头开始。
在下面这个例子中,作者使用随机森林
来判断一个人是否患有糖尿病。他用到的数据集是著名的「Pima Indians Diabetes Database」。
model: type: classification algorithm: RandomForest arguments: n_estimators: 100 max_depth: 30
target: - sick
注意,作者将 n_estimators 和 max_depth 传递给了模型,用作模型的附加参数
。如果你不提供
参数
,模型就会使用默认
参数
。你不需要记住每个模型的
参数
。相反,你可以在终端运行 igel models 进入交互模式。在交互模式下,系统会提示你输入你想要使用的模型以及你想要解决的问题的类型。接下来,Igel 将展示出有关模型的信息和链接。通过该链接,你可以看到可用
参数
列表以及它们的使用方法。
igel 的使用方式应该是从终端(igel CLI):
在终端运行以下命令来拟合 / 训练模型,你需要提供数据集和 yaml 文件的路径。
$ igel fit --data_path 'path_to_your_csv_dataset.csv' --yaml_file 'path_to_your_yaml_file.yaml'
$ igel fit -dp 'path_to_your_csv_dataset.csv' -yml 'path_to_your_yaml_file.yaml'
"""That's it. Your "trained" model can be now found in the model_results folder(automatically created for you in your current working directory).Furthermore, a description can be found in the description.json file inside the model_results folder."""

$ igel evaluate -dp 'path_to_your_evaluation_dataset.csv'"""This will automatically generate an evaluation.json file in the current directory, where all evaluation results are stored"""
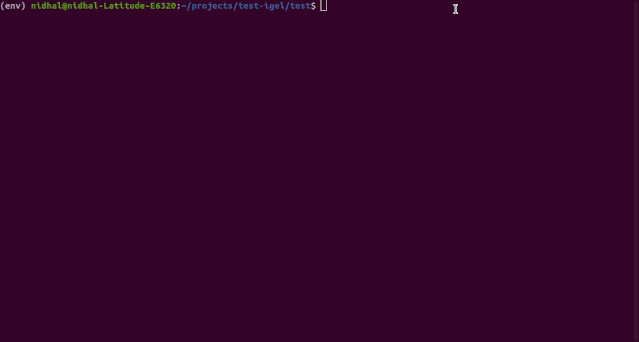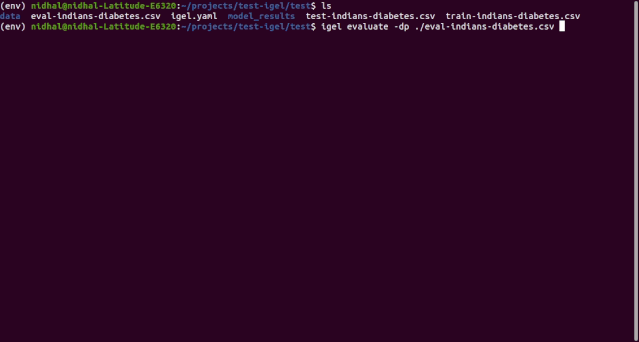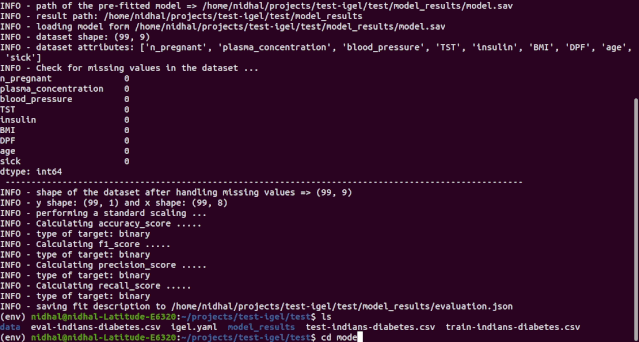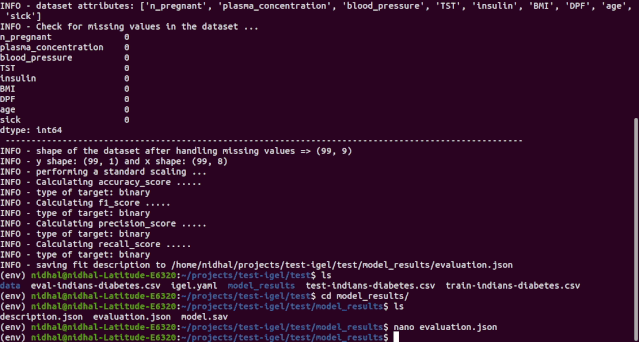
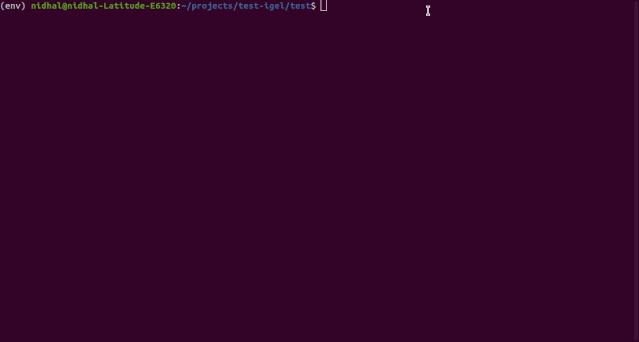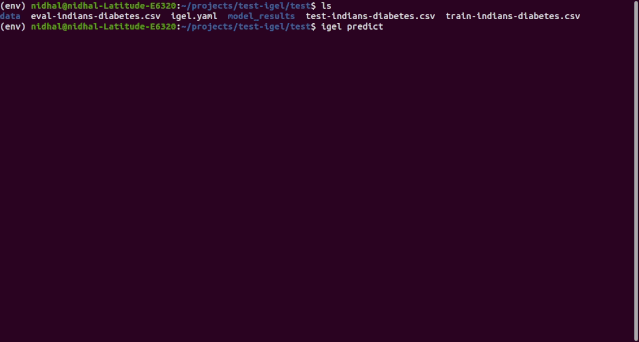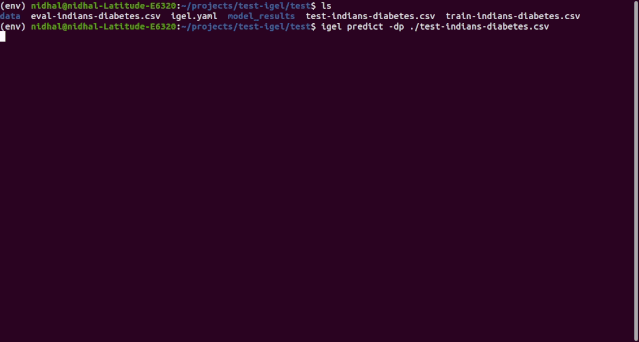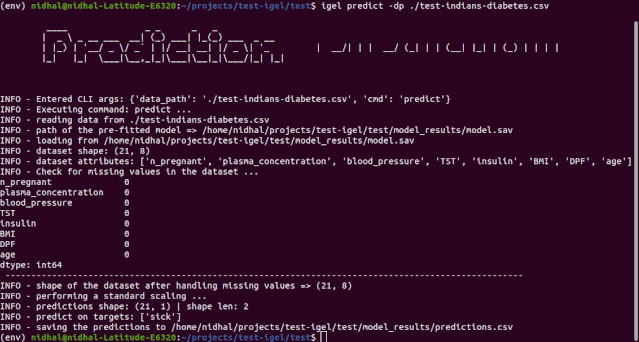
如果你对评估结果比较满意,就可以使用这个训练 / 预训练好的模型执行预测。
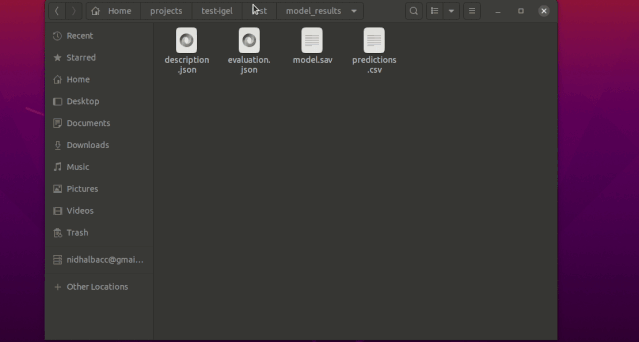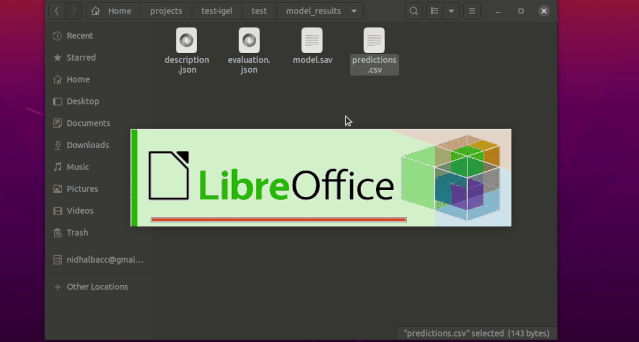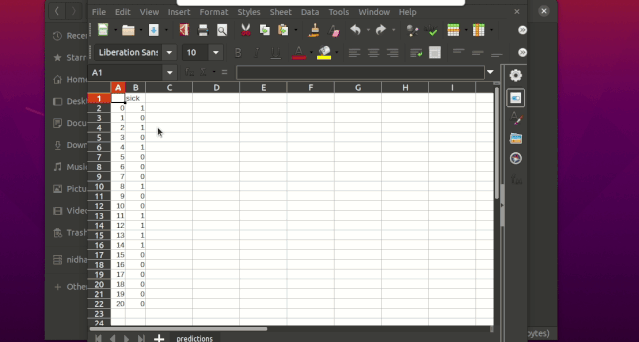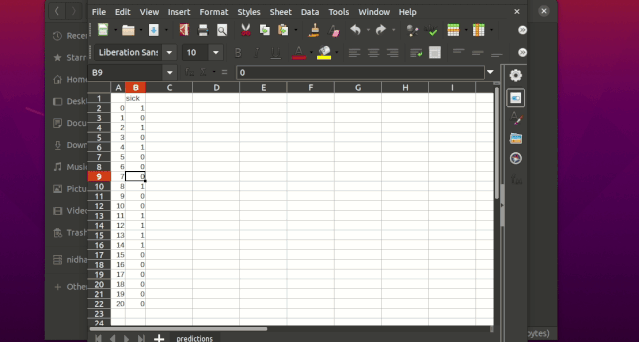
$ igel predict -dp 'path_to_your_test_dataset.csv'"""This will generate a predictions.csv file in your current directory, where all predictions are stored in a csv file"""
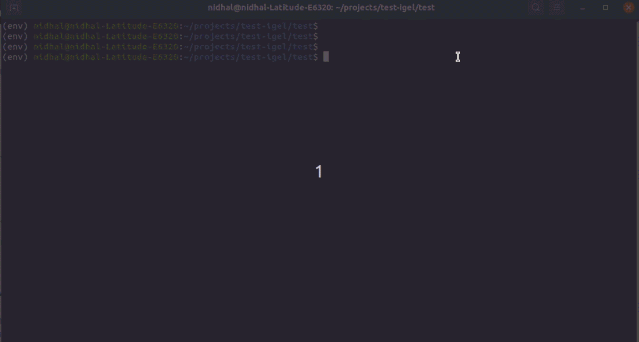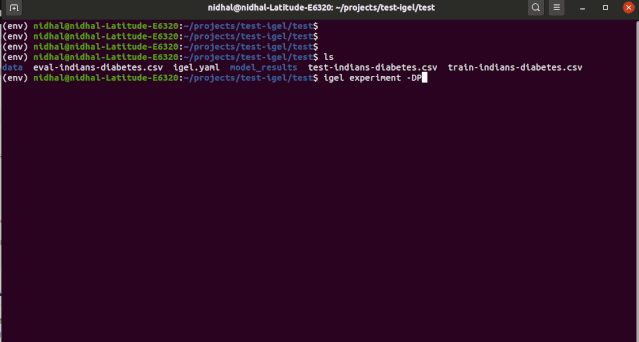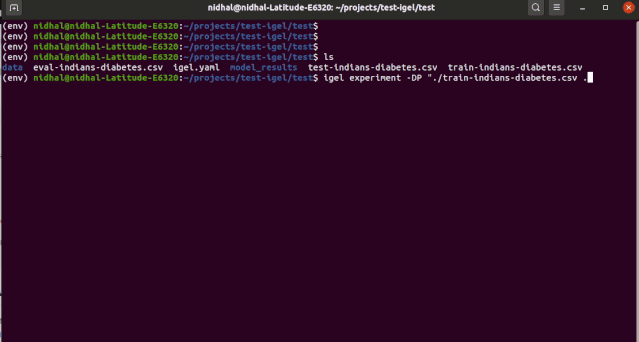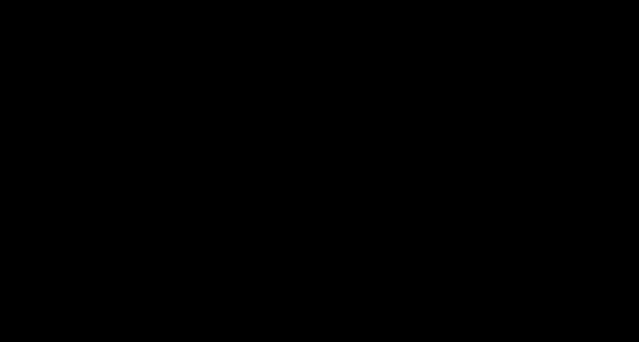
你可以使用一个「experiment」命令将训练、评估和预测结合到一起:
$ igel experiment -DP "path_to_train_data path_to_eval_data path_to_test_data" -yml "path_to_yaml_file"
"""This will run fit using train_data, evaluate using eval_data and further generate predictions using the test_data"""
交互模式是 v0.2.6 及以上版本中新添加的,该模式可以让你按照自己喜欢的方式写参数
。
也就是说,你可以使用 fit、evaluate、predict、experiment 等命令而无需指定任何额外的参数
,比如:
如果你只是编写这些内容并点击「enter」,系统将提示你提供额外的强制参数
。0.2.5 及以下版本会报错,所以你需要使用 0.2.6 及以上版本。
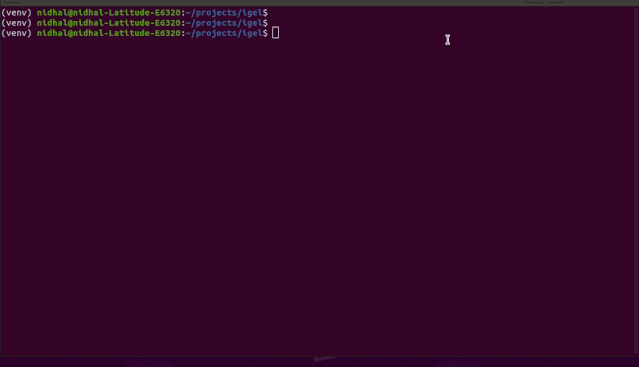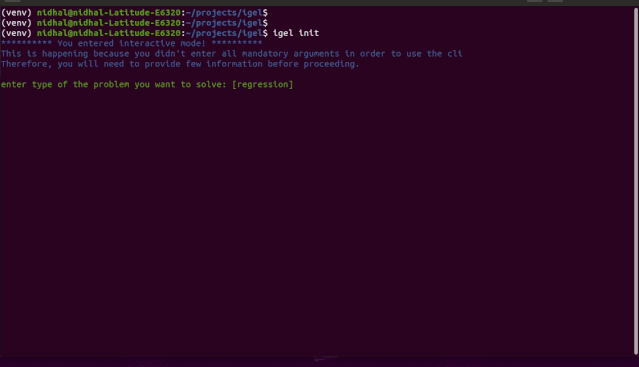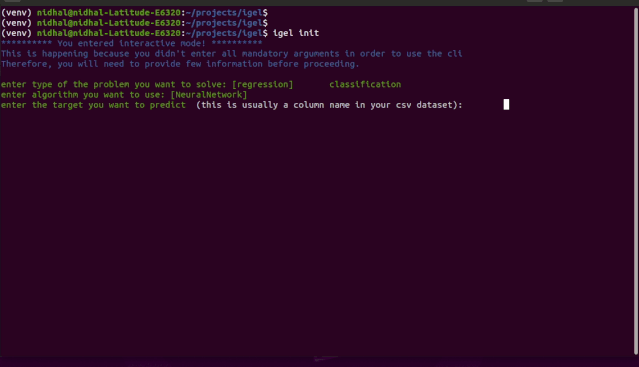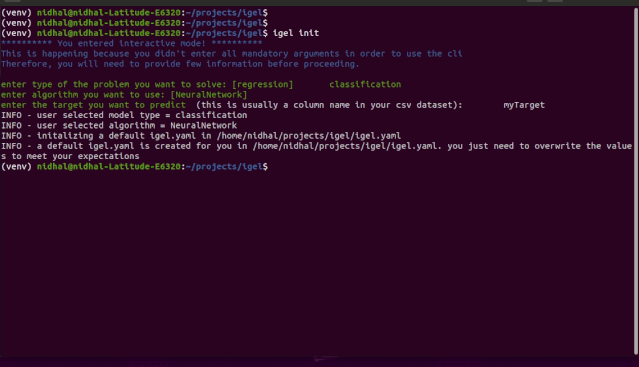
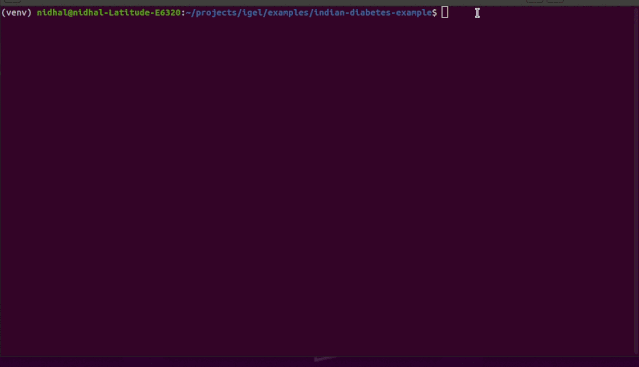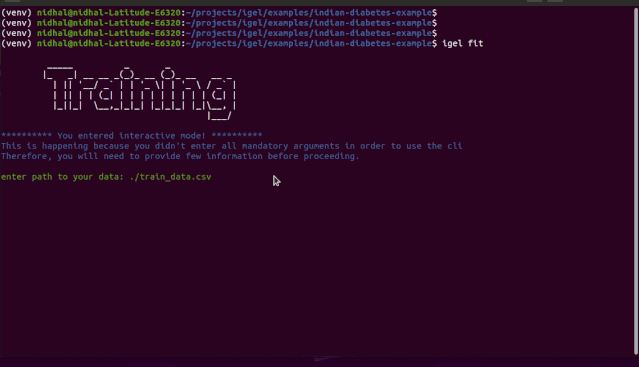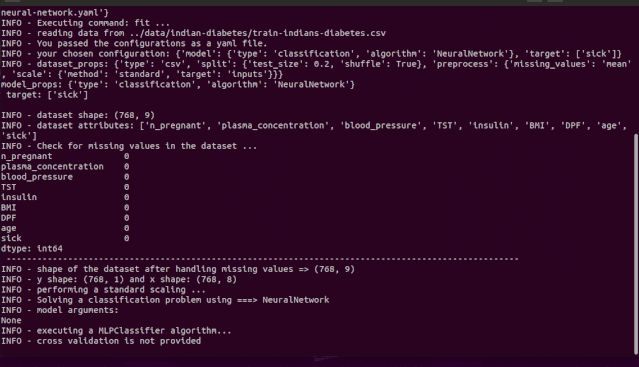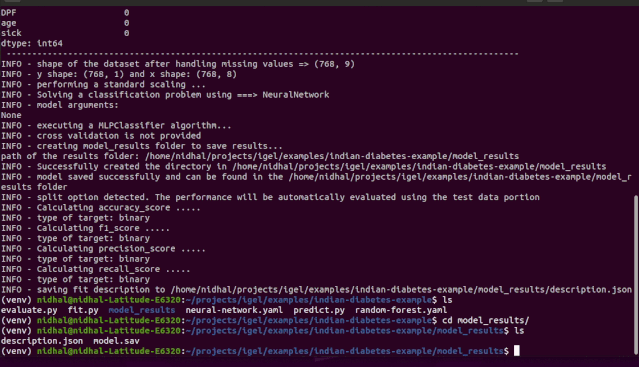
如 demo 所示,你不需要记住这些参数,igel 会提示你输入这些内容。具体而言,Igel 会提供一条信息,解释你需要输入哪个参数。
括号之间的值表示默认值。
项目作者给出了使用 igel 进行端到端训练的完整示例,即使用决策树算法预测某人是否患有糖尿病。你需要创建一个 yaml 配置文件,数据集可以在 examples 文件夹中找到。
model: type: classification algorithm: DecisionTree
target: - sick
$ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_file
现在,igel 将拟合你的模型,并将其保存在当前目录下的 model_results 文件夹中。










