陈桦 编译自 Google Research Blog
量子位 报道 | 公众号 QbitAI
Google Brain团队昨天发布的“一个模型学会一切”论文背后,有一个用来训练MultiModel模型的模块化多任务训练库:Tensor2Tensor。
今天,Google Brain高级研究员Łukasz Kaiser就在官方博客上发文,详细介绍了新开源的T2T库。
以下内容编译自Google Research的官方博客:
深度学习推动了许多技术的快速发展,例如机器翻译、语音识别和对象检测。在科研领域,人们可以查找作者开源的代码,从而复现他们的研究成果,推动深度学习技术的进一步发展。
然而,这些深度学习系统大部分都采用了独特配置,需要大量的工程开发,并且可能只适用于特定的问题或架构,导致很难尝试新的实验并比较结果。
今天,我们很高兴发布Tensor2Tensor (T2T),一个用于在TensorFlow中训练深度学习模型的开源系统。
T2T有助于开发顶尖水平的模型,并适用各类机器学习应用,例如翻译、分析和图像标注等。这意味着,对各种不同想法的探索要比以往快得多。
此次发布的这个版本还提供了由数据集和模型构成的库文件,包括近期几篇论文中最优秀的模型
(文末列举了这几篇论文)
,从而推动你自己的深度学习研究。
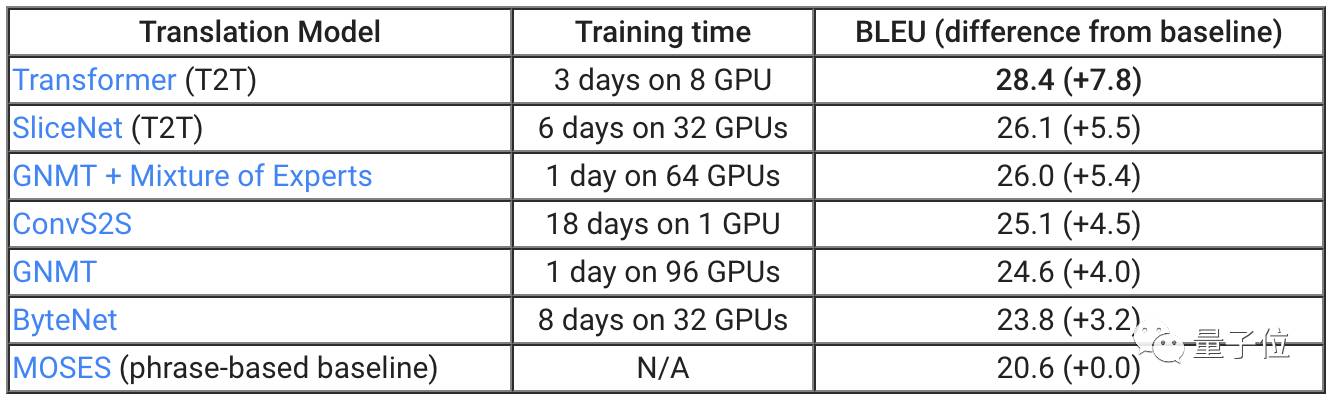
为了证明T2T可以带来的改进,我们将库文件应用于机器翻译。正如上表所显示的,两个不同的T2T模型,SliceNet和Transformer,超过了此前表现最好的系统GNMT+MoE。
我们最优秀的T2T模型Transformer,比标准GNMT模型高出3.8分,而GNMT自身要比作为基准的翻译系统MOSES高出4分。
值得注意的是,通过T2T,你可以使用单个GPU,在一天时间里获得此前最漂亮的结果:小规模Transformer模型基于单个GPU在一天的训练后获得了24.9 BLEU。
目前,所有拥有GPU的研究者都可以自行探索最强大的翻译模型。我们在Github上介绍了如何去做。
模块化的多任务训练
T2T库利用TensorFlow工具来开发,定义了一个深度学习系统中需要的多个部分:数据集、模型架构、优化工具、学习速率衰减计划,以及超参数等等。
最重要的是,T2T在所有这些部分之间实现了标准接口,并配置了当前机器学习的最佳行为方式。
因此,你可以选择任意数据集、模型、优化工具,以及一套超参数,随后运行训练,看看效果如何。
我们实现了架构的模块化,因此输入数据和预期输出结果之间所有部分都是张量到张量的函数。
如果你对模型的架构有新想法,那么不需要替换所有设置。你可以保留嵌入的部分,用自己的函数来替换模型体。这样的函数以张量为输入,并返回张量。
这意味着T2T很灵活,训练不再局限于特定模型或数据集。
这也非常简单,例如知名的LSTM序列到序列模型可以用几十行代码来定义。你也可以用不同类型的多任务来训练单个模型。在一定的限制下,单个模型甚至可以使用所有数据集来训练。








