
作者 | 徐汉彬
指导 | 宋彦
01
前言
深度学习(深度神经网络)作为机器学习的一个重要分支,推动了很多领域的研究和应用,其中包括文本处理领域的情感分类问题。
由于可以对文本进行更有效地编码及表达,基于深度学习的情感分类对比传统的浅层机器学习和统计学方法,可以取得更高的分类准确率。
当前,情感分析在互联网业务中已经具有比较广泛的应用场景,成为了一个重要的业务支持能力。
02
文本情感分析的发展与挑战
1. 情感分析的发展
情感分析(Sentiment Analysis),也称为情感分类,属于自然语言处理(Natural Language Processing,NLP)领域的一个分支任务,分析一个文本所呈现的信息是正面、负面或者中性,也有一些研究会区分得更细,例如在正负极性中再进行分级,区分不同情感强度。
在 2000 年之前,互联网没有那么发达,积累的文本数据不多,因此,这个问题被研究得较少。2000 年以后,随着互联网大潮的推进,文本信息快速积累,文本情感分析的研究也开始快速增加。
早期主要是针对英文文本信息,比较有代表性的,是 Pang, Lee and Vaithyanathan (2002) 的研究,第一次采用了 Naive Bayes(朴素贝叶斯), Maximum Entropy(最大熵)和 SVM(Support Vector Machine, 支持向量机)等方法对电影评论数据进行了情感分类,将之分为正面或者负面。2000-2010 年期间,情感分析主要基于传统的统计和浅层机器学习,由于这些方法不是本文阐述的重点,因此,本文就不再展开介绍。
2010 年以后,随着深度学习的崛起和发展,情感分析开始采用基于深度学习的方法,并且相对于传统的机器学习方法取得了更好的识别准确率。
2. 中文文本情感分析的难点
由于汉语博大精深,从传统方法的角度来看,中文文本的情感分析有多个难点:
(1)分词不准确:中文句子由单个汉字组成,通常第一个要解决的问题,就是如何“分词”。但是,由于汉字组合的歧义性,分词的准确率一直难以达到完美的效果,而不准确的分词结果会直接影响最终分析的结果。
(2)缺乏标准完整的情感词库:与中文相比,英文目前有相对比较完整的情感词库,对每个词语标注了比较全面的情感类型、情感强度等。但是,中文目前比较缺乏这样的情感词库。同时考虑到语言的持续发展的特性,往往持续不断地产生新的词语和表达方式,例如,“陈独秀,坐下”,“666”,它们原本都不是情感词,在当今的互联网环境下被赋予了情感极性,需要被情感词库收录。
(3)否定词问题:例如,“我不是很喜欢这个商品”和“我很喜欢这个商品”,如果基于情感词的分析,它们的核心情感词都是“喜欢”,但是整个句子却表达了相反的情感。
这种否定词表达的组合非常丰富,即使我们将分词和情感词库的问题彻底解决好,针对否定词否定范围的分析也会是一个难点。
(4)不同场景和领域的难题:部分中性的非情感词在特定业务场景下可能具有情感倾向。
例如,如下图的一条评论“(手机)蓝屏,充不了电”,蓝屏是一个中性名词,但是,如果该词在手机或者电脑的购买评价中如果,它其实表达了“负面”的情感,而在某些其他场景下还有可能呈现出正面的情感。
因此,即使我们可以编撰一个完整的“中文情感词典”,也无法解决此类场景和领域带来的问题。

上述挑战广泛存在于传统的机器学习与深度学习方法中。但是,在深度学习中,有一些问题可以得到一定程度的改善。
03
中文分词概述
一般情况下,中文文本的情感分类通常依赖于分析句子中词语的表达和构成,因此需要先对句子进行分词处理。不同于英文句子中天然存在空格,单词之间存在明确的界限,中文词语之间的界限并不明晰,良好的分词结果往往是进行中文语言处理的先决条件。
中文分词一般有两个难点,其一是“歧义消解”,因为中文博大精深的表达方式,中文的语句在不同的分词方式下,可以表达截然不同的意思。
有趣地是,正因如此,相当一部分学者持有一种观点,认为中文并不能算作一种逻辑表达严谨的语言。
其二是“新词识别”,由于语言的持续发展,新的词汇被不断创造出来,从而极大影响分词结果,尤其是针对某个领域内的效果。下文从是否使用词典的角度简单介绍传统的两类中文分词方法。
1. 基于词典的分词方法
基于词典的分词方法,需要先构建和维护一套中文词典,然后通过词典匹配的方式,完成句子的分词,基于词典的分词方法有速度快、效率高、能更好地控制词典和切分规则等特性,因此被工业界广泛作为基线工具采用。
基于词典的分词方法包含多种算法。比较早被提出的有“正向最大匹配算法”(Forward Maximum Matching,MM),FMM 算法从句子的左边到右边依次匹配,从而完成分词任务。
但是,人们在应用中发现 FMM 算法会产生大量分词错误,后来又提出了“逆向最大匹配算法”(Reverse Maximum Matching,RMM),从句子右边往左边依次匹配词典完成分词任务。从应用的效果看,RMM 的匹配算法表现,要略为优于 MM 的匹配算法表现。
一个典型的分词案例“结婚的和尚未结婚的”:
FMM:结婚/的/和尚/未/结婚/的 (分词有误的)
RMM:结婚/的/和/尚未/结婚/的 (分词正确的)
为了进一步提升分词匹配的准确率,研究者后来又提出了出了同时兼顾 FMM 和 RMM 分词结果的“双向最大匹配算法” (Bi-directctional Matching,BM ),以及兼顾了词的出现频率的“最佳匹配法”(Optimum Matching,OM)。
2. 基于统计的分词方法
基于统计的分词方法,往往又被称作“无词典分词”法。因为中文文本由汉字组成,词一般是几个汉字的稳定组合,因此在一定的上下文环境下,相邻的几个字出现的次数越多,它就越有可能成为“词”。
基于这个规则可以通过算法构建出隐式的“词典”(模型),从而基于它完成分词操作。该类型的方法包括基于互信息或条件熵为基础的无监督学习方法,以及 N 元文法(N-gram)、隐马尔可夫模型(Hiden Markov Model,HMM)、最大熵模型(Maximum Entropy,ME)、条件随机场模型(Conditional Random Fields,CRF)等基于监督学习的模型。
这些模型往往作用于单个汉字,需要一定规模的语料支持模型的训练,其中监督学习的方法通过薛念文在 2003 年第一届 SIGHAN Bakeoff 上发表的论文所展现出的结果开始持续引起业内关注。
效果上,这些模型往往很善于发现未登录词,可以通过对大量汉字之间关系的建模有效“学习”到新的词语,是对基于词典方法的有益补充。然而它在实际的工业应用中也存在一定的问题,例如分词效率,切分结果一致性差等。
04
基于多层 LSTM 的中文情感分类模型原理
在前述分词过程完成后,就可以进行情感分类了。我们的情感分类模型是一个基于深度学习(多层 LSTM)的有监督学习分类任务,输入是一段已经分好词的中文文本,输出是这段文本正面和负面的概率分布。
整个项目的流程分为数据准备、模型搭建、模型训练和结果校验四个步骤,具体内容会在下文中详细展开。由于本文模型依赖于已切分的中文文本,对于想要动手实现代码的读者,如果没有分词工具,我们建议读者使用网上开源的工具。
1. 数据准备
我们基于 40 多万条真实的鹅漫用户评论数据建立了语料库,为了让正面和负面的学习样本尽可能均衡,我们实际抽样了其中的 7 万条评论数据作为学习样本。一般情况下,对于机器学习的分类任务,我们建议将学习样本比例按照分类规划为 1:1,以此更好地训练无偏差的模型。
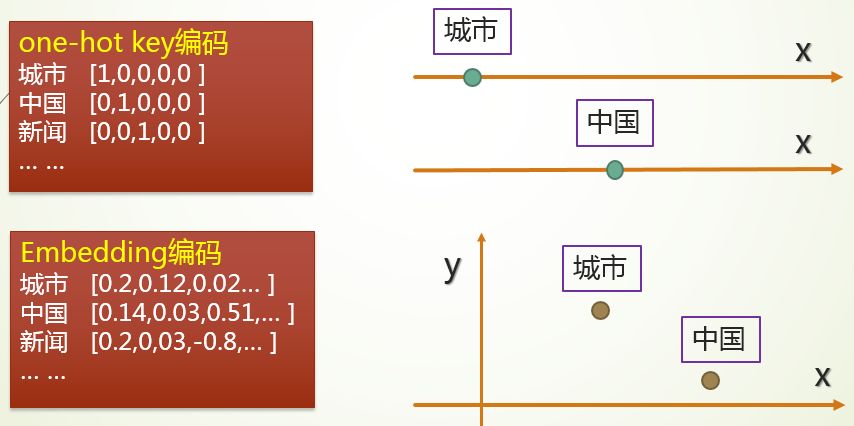
模型的输入是一段已经分词的中文文本,但它无法直接被模型识别,因此我们要将它转换成一种能被模型识别的数学表达。最直接的方式是将这些文本中的词语用“One-Hot Key”进行编码。One-Hot Key 是一种比较简单的编码方式,假设我们一共只有5个词,则可以简单地编码为如下图所示:

在一般的深度学习任务中,非连续数值型特征基本采用了上述编码方式。但是,One-Hot Key 的编码方式通常会造成内存占用过大的问题。我们基于 40 多万条用户评论分词后获得超过 38000 个不同的词,使用 One-Hot Key 方式会造成极大的内存开销。下图是对 40 多万条评论分词后的部分结果:

因此,我们的模型引入了词向量(Word Embeddings)来解决这个问题,每一个词以多维向量方式编码。我们在模型中将词向量编码维度配置为 128 维,对比 One-Hot Key 编码的 38000 多维,无论是在内存占用还是计算开销都更节省机器资源。
作为对比,One-Hot key 可以粗略地被理解为用一条线表示 1 个词,线上只有一个位置是 1,其它点都是 0,而词向量则是用多个维度表示 1 个词。
这里给大家安利一个很好的资源,由腾讯 AI Lab 去年10月发布的大规模中文词向量,可以对超过 800 万词进行高质量的词向量映射,从而有效提升后续任务的性能。
https://ai.tencent.com/ailab/nlp/embedding.html
假设我们将词向量设置为 2 维,它的表达则可以用二维平面图画出来,如下图所示:
2. 模型搭建
本项目的代码采用了 Keras 实现,底层框架是 Google 开源的 TensorFlow。整个模型包含 6 层,核心层包括 Embedding 输入层、中间层(LSTM)、输出层(Softmax)。








