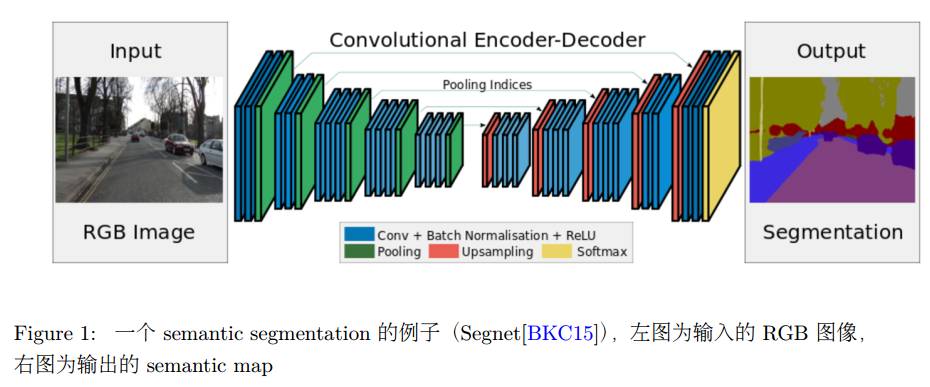
近些年来,随着 Deep Learning 技术的飞速发展, Deep Learning 技术在计算机视觉的各个领域都有着非常成功的应用。其中 semantic segmentation 是其中一个重要的方向。那么什么是 semantic segmentation 呢? semantic segmentic 的输入是一幅图像,输出是同样尺寸的图像,其中每个 pixel 代表的是该像素的类别(label),也就是输入图像的语义图(semantic map)。
当我们有了整幅图像的 semantic map 后,身为做 SLAM 的我们就会想到,能不能把semantic map 与 SLAM 相结合,生成漂亮的 3D 的语义模型呢?答案是 yes。过去,类似的工作是由随机森林和 3D Reconstruction 完成的,近些年(2016 年开始)涌现了一些将 Deep Learning 与 SLAM 相结合的工作,并且有逐渐增多的趋势。
进行语义建图的 pipline 很简单:
1. 为了获得一个好的 3D 模型,一般语义建图都是采用 RGBD 相机的稠密建图。
2. semantic segmentation 一般是直接作用于 2D 的 RGB 图像上,生成 2D 的 semantic
map
3. 将 2D semantic map 反向投影到 3D 的模型上,得到语义模型。
4. 因为图像分割的效果一般并不是很理想,所以我们会加一步后处理,在 3D 上做一下
Condition Random Field,来 refne 最后的结果
条件随机场可以简单的理解为相似相邻,以 2D 图像举例:距离近的,差异小的 pixel 我们认为他们应该拥有相同的 label,所以对于距离近的,差异小的 pixel,如果他们的 label 相同,我们给予它一个小的 loss,如果 label 不同,我们给予他们一个大的 loss,最后我们最小化整个模型的 loss function,得到所有 pixel 的 label。
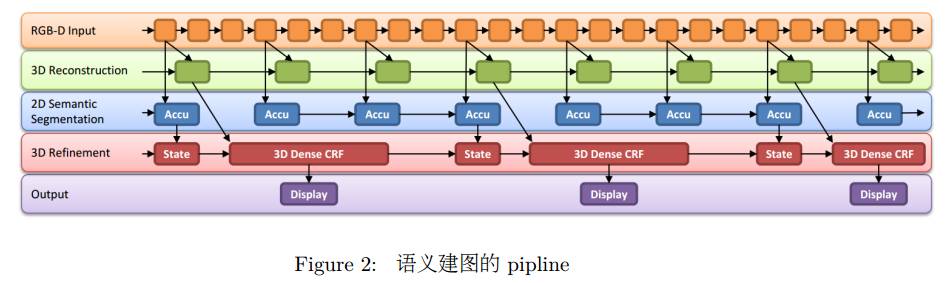
整个 pipline 流程见 Figure 2。
下面,我们先举一个过去采用随机森林进行语义建图的例子,之后再介绍几个最近的基于 Deep Learning 的语义建图的工作。
 1. Incremental Dense Semantic Stereo Fusion[
VML
+
15
]
1. Incremental Dense Semantic Stereo Fusion[
VML
+
15
]
在这个工作里面,我们会详细的介绍语义建图里面的一些基本知识。后续几个工作只是
简单的提及自身的创新点,对于之前描述过的内容不再赘述。
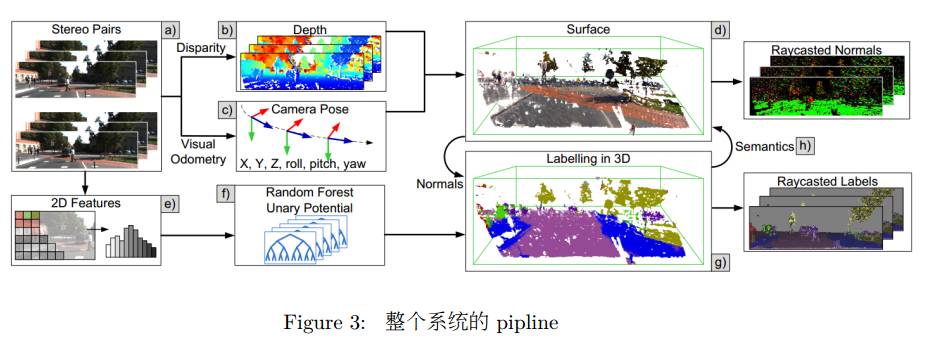
整个系统的 pipline 见 Figure 3,最终的效果图见 Figure 4。
1.1 Semantic Segmentation
Semantic Segmentation 采用的是 Random Forest 方法,具体我也没有细看,就不细表了。
1.2 Mapping
在 Mapping 这块,与传统的 3D Reconstruction 技术并没有什么不同,只是采用 Stereo 估计深度。该工作使用了 Voxel Hashing 实现的 KinectFusion 系统进行建图,以保证 Large-scale的重建。
1.3 Semantic Fusion
在这里我们点出了语义信息如何更好的帮助建图。此处利用语义信息来处理动态物体。
我们知道,动态物体对于 tracking 和 fusion 都会有很大的影响。对于不同类物体,它是否是运动的概率是不一样的。比如车辆很可能是运动的,但是路面就肯定不是运动的。所以与传统的 KinectFusion 的 Fusion 方法不同, Semantic Fusion 利用语义信息根据 voxel 的 label给予每个 voxel 不同的 weight 进行 fusion。
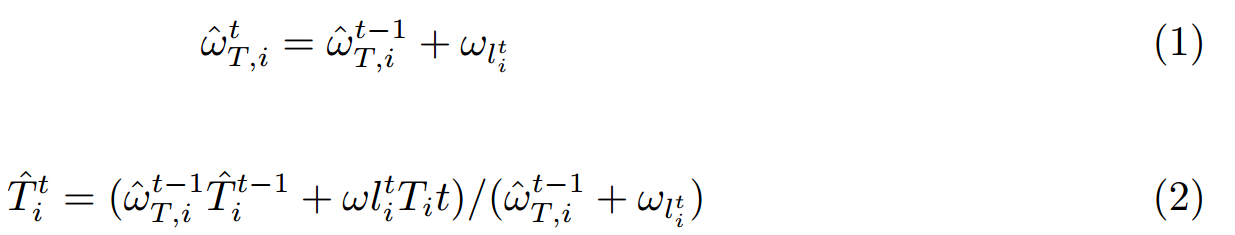
在上面的更新方程中
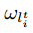 是每个类
是每个类
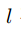 在
在
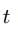 时间对于 voxel
时间对于 voxel
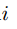 的固定的 weight。
的固定的 weight。
1.4 Label Fusion
我们在每一个 voxel 中存储对应 label 的概率,然后采用贝叶斯的方式用每次得到的 semantic map(在这里存储每个 pixel 对应 label 的概率)来更新每个 label 的概率。
1.5 3D Condition Random Field
在这一节简单的介绍一下 3D Condition Random Field
。





