问题导读
1.如何从所有数据中,抽取样本查看?
2.如何保存结果到hdfs?
3.saveAsTextFile的作用是什么?
上一篇
日志分析实战之清洗日志小实例6:获取uri点击量排序并得到最高的url
http://www.aboutyun.com/forum.php?mod=viewthread&tid=22928
查看示例数据
[Scala]
纯文本查看
复制代码
?
|
1
|
uriCounts.takeSample(
false
,
5
,
10
).foreach(println)
|

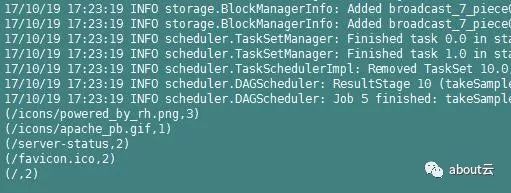
说明
上面三个参数,
表示采样是否放回,true表示有放回的采样,false表示无放回采样;第二个参数num,表示返回的采样数据的个数,第三个参数是种子,这里只有10条数据,所以使用10.
保存数据
我们统计网站信息,那么该如何保存我们的数据。保存如下代码,spark默认保存到hdfs。对于路径写了两种方式,但是他们保存的路径则完全的不同。
[Scala]
纯文本查看
复制代码
?
|
1
|
uriCounts.saveAsTextFile(
"/UriHitCount"
)
|
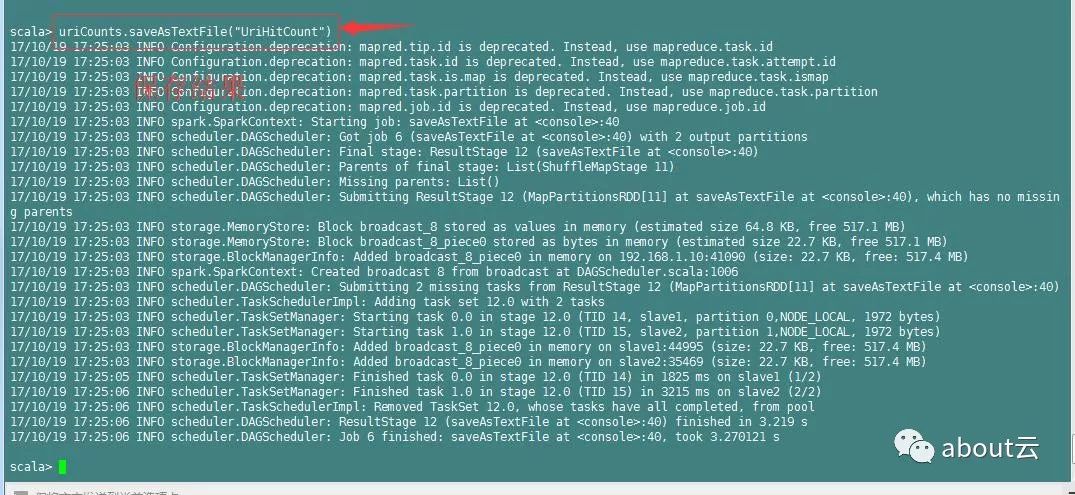
上面是保存在了根路径,在hdfs上面查看
[Scala]
纯文本查看
复制代码
?
|
1
|
hdfs dfs -cat /UriHitCount/part-
00000
|




