【授权转载于小S的公众号 程序媛的日常】
GAN 提出两年多来,很多想法都被研究者们提出、探索并实践。直到最近近乎同一时期发布的三篇论文,CycleGAN、DiscoGAN 和 DualGAN,已经展现了集百家之长的特点。同时,这三篇论文的想法十分相似,几乎可以说是孪生三兄弟,并都取得了不错的结果。不过,这三兄弟的诞生原因也有迹可循。今天就想稍微整理一下这三篇相似论文的发展脉络:它们彼此之间的异同,以及它们与前人工作的相似之处——从而找出它们散落天涯的“远亲们”。
今天会涉及到的论文有:
1. 《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》 by BAIR
2. 《Learning to Discover Cross-Domain Relations with Generative Adversarial Networks》 by SK T-Brain
3. 《DualGAN: Unsupervised Dual Learning for Image-to-Image Translation》 by Memorial University of Newfoundland & Simon Fraser University
4. 《Unsupervised Cross-Domain Image Generation》 by FAIR
5. 《Coupled Generative Adversarial Networks》 by MEIR
6. 《Adversarially Learned Inference》 by MILA
7. 《Adversarial Feature Learning》by UC Berkeley
8. 《Mode Regularized Generative Adversarial Networks》 by MILA & PolyU
9. 《Energy-Based Generative Adversarial Networks》 by NYU

CycleGAN 的开头非常优美和引人入胜,先是放出了这些 impressive 的 result;同时用一种带逛博物馆的语气写了 Introduction:“
当梵高在一个和煦的春天的早上,站在河畔画下这幅画时,他眼前究竟是怎样的景象呢?如果梵高站在一个清爽的夏天的早上,又会看到怎样的景象,画出怎样的作品呢?
”作者的写作功底可见一斑。
作者用这样的开头,引出了一个 motivation:我们虽然没有办法真的穿越时空,站在梵高身边看到他当时看到的景象,但是我们却可以通过他的画作,想象当时的场景;同时也可以根据他的作品(和他的画风),想象他画出的其他场景会是怎样的。也就是说,我们没有 paired data 却可以实现这种“翻译”或者说映射。那么我们是否也可以让机器做到这件事呢?这是 CycleGAN,也是 DualGAN 的 motivation(虽然 DiscoGAN 也有这个 motivation,但侧重点不在这里,后面详述)。
我们人类之所以可以做到这件事,作者假设,在两个领域(X,Y)之间,是存在一种底层的关系的,或者说隐含的关联——这种隐含的关联可能是,对于同一个事物,有两种不同的映射后的表达,那么这两种表达之间就是针对这同一个事物的一种关联。如果我们仅用一个映射把 G: X->Y 进行单向映射,那么我们无法保证这个 G 是单一的。或者说,我们无法保证 X 中的所有样本 x 和 Y 领域中的所有样本 y 是合理对应的。这也就(可能)导致 mode collpase 的问题。
对于这个问题的描述,在 CycleGAN 中,作者用了 meaningful 这个词;而在 DiscoGAN 中,作者强调了我们希望的是 one-to-one mapping, rather than many-to-one mapping
。
通过这样的分析,很容易看出,一种自然的解决方案就是,我们不仅要求一个单向映射,而更要求一种双向映射。
在 CycleGAN 中,这个问题被形式化为:我们有 G: X->Y, F: Y->X 两个映射或者说翻译器,我们希望 F(G(x)) ≈ x, G(F(y)) ≈ y. 在 DiscoGAN 中,作者直接把这个映射用 GAN 中的 generator 代表,所以为了实现这样的双向映射,DiscoGAN 中指出我们需要两个 G,并且让尽量 G1(G2(x)) = x,反之同理。DualGAN 的形式化与 DiscoGAN 相似。
不过,三篇论文分别用了三种不同的术语来实现这样的约束或者说目标。CycleGAN 中,作者用了 vision 中被应用多次的
cycle consistency loss
,CycleGAN 也因此得名;DiscoGAN 则是因为直接强调了一一映射,所以用了
bijective map
来阐述;DualGAN 因为是从去年 NIPS 2016 Dual Learning for MT 的 paper 受到启发的,所以是从
closed loop
角度来写的。不过个人认为从 Dual Learning 那篇得到启发做这件事,写得不是很好,其实也不是那样相似。从出发点上就比另外两篇 paper 弱了一些。
下面来看看三篇工作的模型示意图:
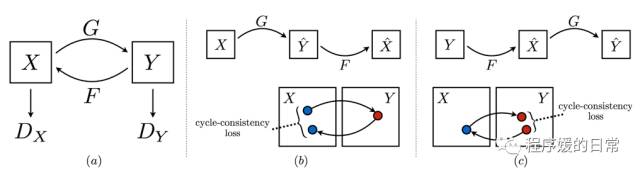
上图:CycleGAN
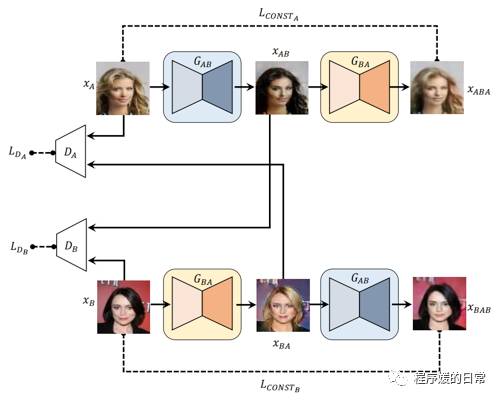
上图:DiscoGAN
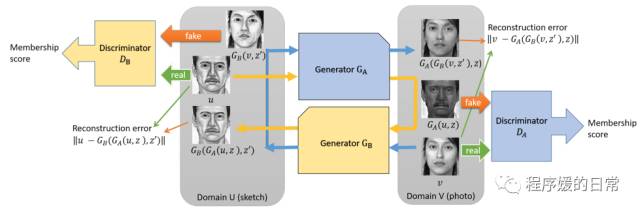
上图:DualGAN
上面三个示意图虽然风格迥异,但是如果把 CycleGAN 中的 G 和 F 的映射用最后实现中的生成器 G1 G2 来理解,那么三个模型真可谓亲如手足。
其实三者的公式也非常相似,在这里就不截图贴出了。只不过实现细节上,还是有相当大的差别。既然都是 GAN,
我们先从三者的生成器来比较
。三者的生成器都用了不同架构,其中 CycleGAN 对于不同的任务基本都用了同样的架构,但是 DualGAN 的架构似乎变化比较多(任务差别比较大)。CycleGAN 主要采用了 Fei-Fei Li 组做提出 perceptual loss 的 style transfer 的架构,有 residual block,并且也用了 instance normalization。DiscoGAN 的结构则和 DCGAN 比较相似,是和简单的 conv-deconv 结构,这可能是因为他们主要目的是做横向对比。DualGAN 的结构则采用了 pix2pix 工作中也用到的 U-Net 对称结构,同时也包含了 residual block,并且他们给出了比较多的 intuition 为什么这样的结构比较合理——但个人认为这样也会同时有些将自己的工作局限在某些特定 task 上,从卖点上会和 CycleGAN 更不同一些。
说完了生成器再说判别器
。CycleGAN 和 DualGAN 的判别器比较相似,都采用了 PatchGAN 来实现局部判别(而非完整图片的判别);DiscoGAN 则继续简单粗暴,用和生成器相似的也就是和 DCGAN 相似的简单结构就完成了。
最后进入重中之重,他们分别做了哪些实验。从实验上其实可以看到更大的差异,或者说文章的立意与侧重点的不同。
CycleGAN 因为强调的是 unpaired translation,所以做了各种两个领域之间的图像“翻译”任务,可谓数据集之大观
:

而
D
iscoGAN 则侧重分析这样的双向映射,或者说 bijective mapping 的约束,是如何避免 mode collapse 进而提升生成样本质量的:
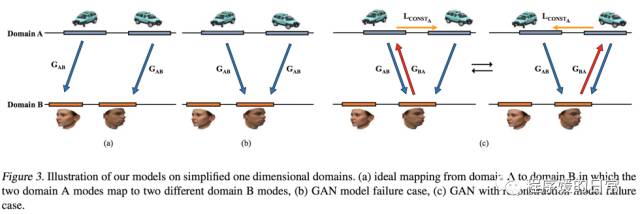

DiscoGAN 用上面的 Figure 3 来解释为什么简单单向加 reconstruction loss(Figure 3(c) )不能完全解决 mode collapse 的问题。可以看出,这会导致不同的样本在同样的对应的 mode 之间震荡(ocsillate)。而下面的图,是 DiscoGAN 制造的一个 toy experiment,将可视化技术用到了极致。在图中,他们不仅利用了点线面的可视化方法,还利用了背景色的方法(背景色代表判别器的输出值)。
可以看到,只有图(d) 对应的 DiscoGAN 这种双向映射的方法完美地区分了10个 mode(从背景色可以看出判别器训练得很好);
而图(c) 的单向 reconstruction loss 虽然也可以区分一部分 mode,但对于有一些 mode 还是无能为力(依然 collapse 掉了)。图(b) 则是普通 GAN 基本完全 miss 掉各种 mode 的结果(所以背景色单一,且被分出的区域很少)。
而 DualGAN 在实验任务上和 CycleGAN 比较相似,基本都是各种图像“翻译”,不过图像的种类比较多:
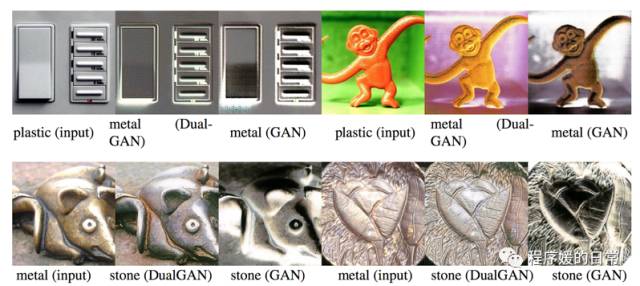
其实就如开篇说的,这仨孪生兄弟有很多散落天涯的“远方亲戚”,不如一起来看一下。
先来看一下前几天在 ICLR Highlight 2(点击阅读)里介绍过的 Domain Transfer Network(DTN):
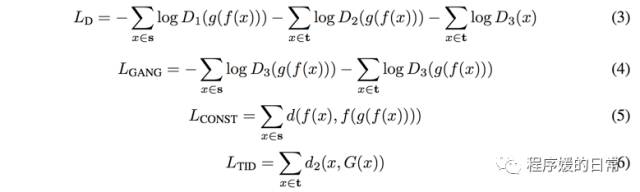
从公式来看,和孪生三兄弟并不十分相似。这是因为,这篇工作是非常强调找到底层的 invariant representation。
DTN 的作者认为,
当 GAN 达到平衡时,其中学到的 G 的表达可以认为是对于任何一个 D 都不可区分的——也就是得到了一种 invariant representaion
。分析
上面的四个式子可以看出,公式(3)(4) 是 GAN 的 loss,(5) 是针对原始领域 S 的,(6) 是针对目标领域 T 的。如果我们令
G = g·f,就可以将上面的公式(3)(4) 看做,DTN 实际上希望 G 可以学到某些和重建相关的方面的 representation(f 在 G 下不变)。再进一步观察公式(3) 可以看到,DTN 中的判别器的损失函数,L_GAN 中的判断变得更加细致了,它被拆分成了——针对 T->T,S->T 两种,也就是说,对于从目标领域生成目标领域的图片时->,应该保持 identity mapping(这点是在上面孪生三兄弟的设定里没有的)。也正是基于此,我们可以看到,
如果我们把 D1 和 D2 合并(不考虑这个设定),那么其实在 DTN 中也是有两个 D,和两个 G(普通的 G 和 g·f)——这应该是 DTN 和孪生三兄弟最大的区别与相似之处
。最后它们还加入了一个 smoothing function TID,也就是公式(6) 使得生成的图片质量更好:

说到 invariant representation 和两个 GAN,就不得不提更早以前的一些工作。首当其中的可能是 Coupled GAN(CoGAN):
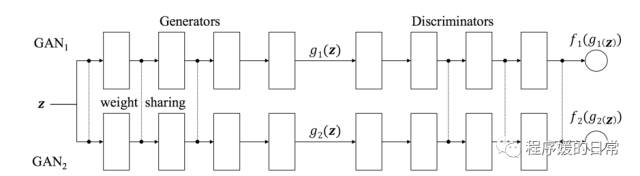
从 CoGAN 的示意图可以看到,这个“远方亲戚”它最大的相似之处也是在于它有两个(两组) GAN。
不同之处在于它们用于学到两个领域之间的关系或者说联合概率(joint distribution)的方法是共享生成器和判别器的部分层的参数。
从下面这个公式可以看出,它和 DTN 的目标是非常相似的(因为出发点都是学习 invariant representation,这也是只共享某些层的参数的原因):
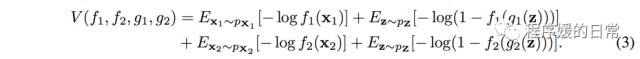
下面我们继续“扩散”,找更远方的“亲戚”。上面介绍的都是两个 G,两个D,两组 GAN 的工作。其实更早以前的工作,有一些是用两个 G,但只有一个 D;或者反之。比如在 DCGAN 之后紧随的一篇工作,ALI:








