眼看 DeepSeek 风头尽显,被逼急的 OpenAI 果然紧急发布了 o3-mni。不光免费用户都能用,每百万输入和输出 token 价格更是疯狂跳水打骨折价!
本文转载自微信公众号新智元。
o3-mini,真的来了。
刚刚,OpenAI 官宣 o3-mini 和 o3-mini-high 两大版本正式在 ChatGPT 上线。
诚如奥特曼所言,免费用户直接打开「Reason」即可体验,Plus 用户每天会有更多用量,具体来说:
- ChatGPT 免费版:首次体验推理模型
- ChatGPT Plus 和团队版:每天 150 次对话限制
- ChatGPT Pro:无限制访问
- ChatGPT Enterprise 和 ChatGPT Edu:将在一周内可用
- API:向 3-5 级开发者开放(初期暂不支持图像分析功能)
- 输入 1.10 美元/百万 token、输出 4.40 美元/百万 token
感谢 DeepSeek,o3-mini 的价格这次算是彻底给打下来了——比 OpenAI o1-mini 便宜 63%,比满血版 o1 便宜 93%。(但仍是 GPT-4o mini 的 7 倍左右)
OpenAI 表示,o3-mini 的发布是在追求高效能智能技术道路上的又一重要里程碑。
通过优化科学(Science)、技术(Technology)、工程(Engineering)和数学(Mathematics)领域的推理能力,同时保持较低的成本,让高质量 AI 技术变得更加平易近人。
值得一提的是,在 ChatGPT 中,o3-mini 采用的是「中等推理强度」,在速度和准确性之间取得平衡。所有付费用户还可以在模型选择器中选择 o3-mini-high——响应时间略长但智能水平更高的版本。
目前,由于太过火爆,ChatGPT 的项目和自定义 GPTs 功能都已经被挤崩了。
去年 12 月,十二天直播最后一弹,o3 系列首次亮相便惊艳了所有人。相较于上一代 o1 模型,o3 在 ARC-AGI 等多项基准测试中刷新 SOTA。
与 o1-mini 一样,o3-mini 是最具性价比的推理模型,可谓是突破性能边界的「小巨人」。
在 STEM 领域,尤其是科学、数学和编程等方面,o3-mini 性能表现卓越超越 o1,并继承了上一代低成本和低延迟的优点。
对于开发者来说,o3-mini 简直就是一份「大礼包」,它首次在小型推理模型中支持:包括函数调用、结构化输出和开发者消息、流式传输功能。
开发者可以根据需求选择低、中、高三种推理强度,让 o3-mini 在处理复杂问题时进行「深度思考」,灵活平衡速度和准确性。
遗憾地是,o3-mini 暂不支持视觉功能。
如前所述,从今天起,o3-mini 将通过 Chat Completions API,Assistants API 和 Batch API 向 3-5 级指定开发者开放。
同时,o3-mini 还整合了搜索功能,能够提供带有相关网络来源链接最新响应。
一起来看看这款「小而美」的 o3-mini 有什么过人之处。
与其前身 OpenAI o1 类似,OpenAI o3-mini 专门针对 STEM 推理进行了优化。
采用了中等推理强度的 o3-mini,在数学、编程和科学领域的表现与 o1 不相上下,且响应速度更快。
报告地址:https://cdn.openai.com/o3-mini-system-card.pdf
专家测试评估显示,o3-mini 相比 o1-mini 能够生成更准确、更清晰的答案,推理能力更强。
在测试中,o3-mini 的响应结果获得了 56% 的偏好度,在处理复杂现实问题时的重大错误率更是降低了 39%。
在中等推理强度设置下,o3-mini 在最具挑战性的推理和智能评估项目(包括 AIME 和 GPQA)中,均达到了与 o1 相当的水平。
数学竞赛(AIME 2024)
在低推理强度下,o3-mini 达到了与 o1-mini 相当的水平;在中等推理强度下,其表现可与 o1 媲美;而在高推理强度下,o3-mini 的表现更是超越了 o1-mini 和 o1。
博士级科学问题(GPQA Diamond)
研究级数学(FrontierMath)
在高推理强度模式下,o3-mini 在 FrontierMath 中的表现优于前代产品。当配合 Python 工具使用时,高推理强度的 o3-mini 能够一次性解决超过 32% 的测试题目,其中包括 28% 以上的 T3 级问题。
编程竞赛(Codeforces)
随着推理强度的提升,OpenAI o3-mini 的 Elo 得分不断提高,各层级表现均优于 o1-mini。在中等推理强度下,其表现已能与 o1 相媲美。
软件工程(SWE-bench Verified)
o3-mini 在高推理强度模式下,使用开源 Agentless 框架能达到 39% 的成功率,使用内部工具框架则可达到 61% 的成功率。
LiveBench 编码
人类偏好评估
外部专家评测结果显示,o3-mini 较 o1-mini 表现出更强的推理能力,能够生成更准确、更清晰的答案,尤其是在 STEM 领域中。在对比测试中,o3-mini 获得了 56% 的用户偏好度,且在处理复杂现实问题时的重大错误率降低了 39%。
在技术报告中,o3-mini 编程性能超越了 GPT-4o 和 o1-preview,与 o1 不相上下。

o3-mini 在保持与 o1 相当智能水平的同时,实现了更快的运行速度和更高的计算效率。
除前文提到的 STEM 评估外,在中等推理强度下,o3-mini 在其他数学能力和事实准确性测试中均取得了显著优势。
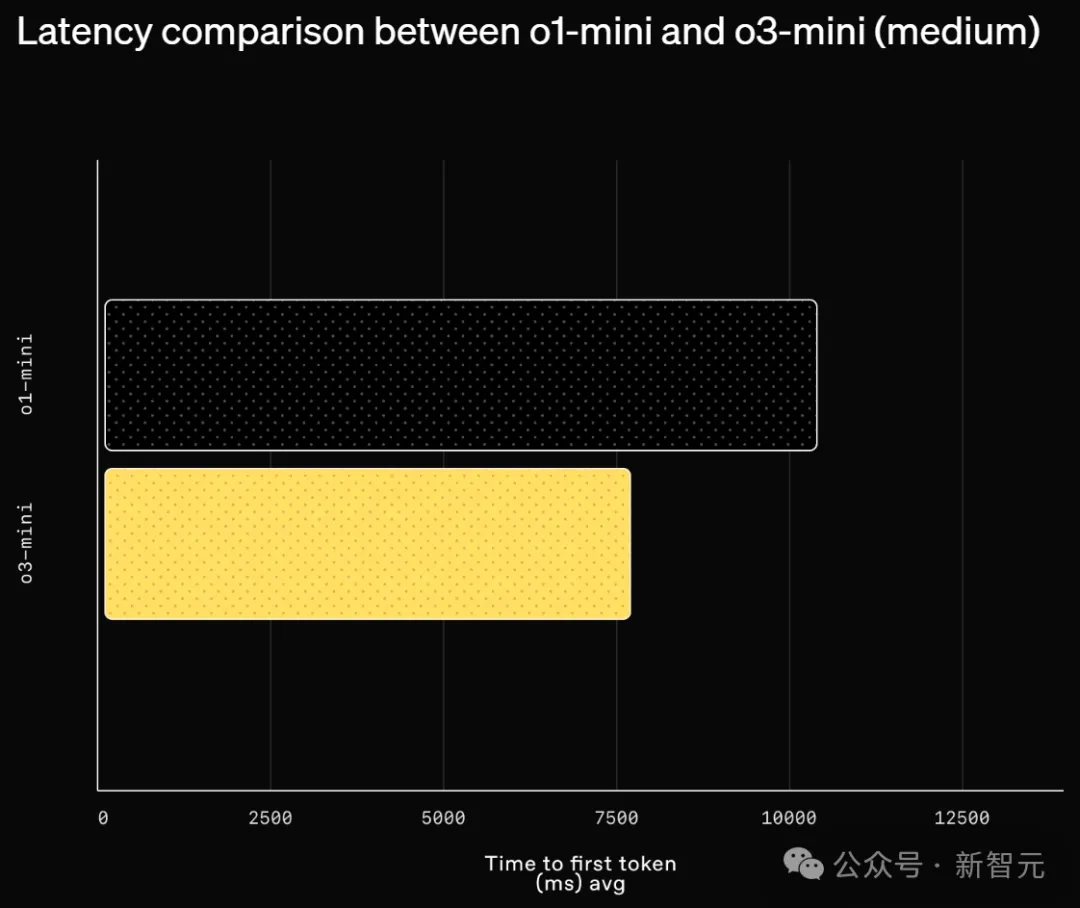
对比测试(A/B Testing)结果显示,o3-mini 的平均响应时间为 7.7 秒,较 o1-mini 的 10.16 秒提升了 24%。
o1-mini 和
o3-mini(medium)的延迟对比
OpenAI 在训练 o3-mini 确保其安全响应,采用的关键技术之一是审慎对齐(deliberative alignment)。
这项技术使模型能够在响应用户提示词前,对人工制定的安全规范进行全面推理。
与 o1 相似,o3-mini 在高难度安全性测试和越狱评估中,明显优于 GPT-4o。
在正式部署前,研究人员采用与 o1 相同的准备方法,结合外部红队测试和安全性评估,对 o3-mini 的安全风险进行了全面评估。
禁止内容评估
越狱评估
去年年底放出 o3 和 o3-mini 的预览时,CEO 奥特曼就曾表示,o3-mini 将会在 1 月份发布。
随后,奥特曼又在 1 月 17 日预告称,o3-mini 会在几周内发布。
现在,o3-mini 果然如约而至(卡在 ddl 最后一天),但外面的世界已经是天差地别。
面对正在快速崛起的 DeepSeek-R1,o3-mini 存在着一个关键问题——「不开源」。
这也就意味着,它无法离线使用、无法下载代码,也无法以相同的程度进行自定义。对于很多应用过来说,它的吸引力相对于 R1 明显大打折扣。
在上下文窗口方面,DeepSeek-R1 约为 128K/130K token,而 o3-mini 略胜一筹达到了 200K token。其中,每个输出最多 100K token,跟满血版 o1 相同。
在价格方面,相比于输入/输出 token 分别为 0.14/0.55 美元的 DeepSeek-R1,o3-mini 依然贵出了天际。
但作为一款美国模型,o3-mini 在身份上无疑占尽了好处:应该会是欧美很多企业的首选。
这一次,最强最新的 o3-mini 模型训练,奥特曼本尊下场亲自率队。研究项目主管分别是 Carpus Chang 和 Kristen Ying。
接下来,如果说 OpenAI 还藏在什么杀手锏,那就是满血版的 o3 了。根据 12 月时的说法,它将在「此后不久」发布。
参考资料:
https://openai.com/index/openai-o3-mini/
https://openai.com/index/o3-mini-system-card/


商务合作
Cassie | 微信:18506490569
Ares | 微信:18606066421
Lina | 微信:13381020131
David | 微信:13809501924
Ania | 微信:13720814733
Echo | 微信:13003974360
Shadow | 微信:18650708568
Demerly | 微信:18150844790
Lia | 微信:baijing018
白鲸出海魏方丹 | 微信:bjbandari02
(添加请备注姓名、公司及职位)
长按识别二维码,备注“白鲸”申请加入白鲸社群,获取更多资讯、活动、资源










