2017 年 1 月 5 日,国家人口与健康科学数据共享平台对外公开发布。这次发布的数据量高达 49.1TB、2.8 亿条,包括生物医学、基础医学、临床、公共卫生、中医药学、药学、人口与生殖健康七大类。(数据库网址:http://www.ncmi.cn/1)
临床大数据是研究者及临床医生取之不尽用之不竭的宝藏。不仅能用于数据分析,发表 SCI 论文,更能指导临床实践。
而且此类基于现实世界的数据能够提供研究者无限的想象与假说,克服传统 RCT 的一些不足之处,为临床诊疗提供证据支持。
有鉴于此,西方国家很早以前就意识到了临床大数据的重要性,建立了许多成熟的数据库。比如危重症数据 MIMIC,目前已经更新到第三版,包含了 5 万多个 ICU 患者信息。
详细介绍见(http://www.nature.com/articles/sdata201635)
中国是人口大国,有着样本量的先天性优势。因此建立和共享我国的人口与健康大数据显得尤为重要。国家人口与健康科学数据共享平台的诞生,意味着大量的中国人口与健康数据将开放给研究者。
如果说爱因斯坦的相对论是物理学的一次革命,那此次国家人口与健康科学数据共享平台的对外开放,无异于中国临床研究的一次历史性革命。
这些数据信息可以为中国的广大临床医生提供大量的研究素材,避免了数据收集上的重复投入。只要进行注册,就能获得海量的数据信息,应用于相关的研究。
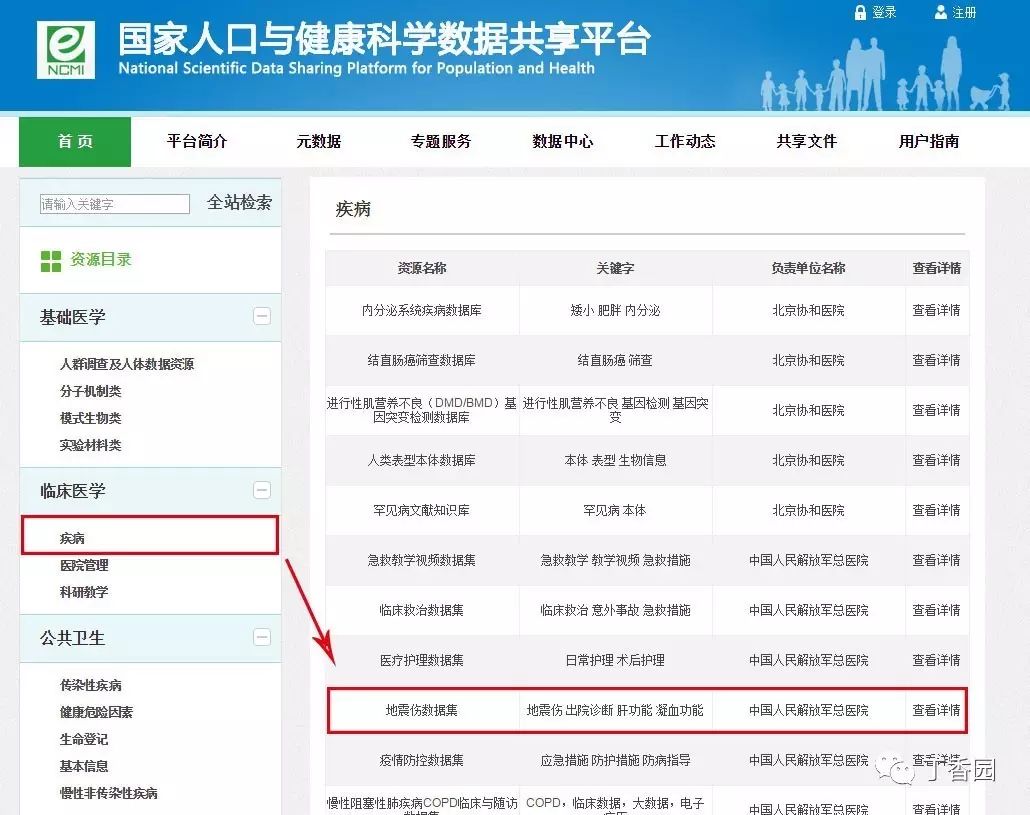
以「地震伤数据集」为例,点击进入后可以查看数据集详细描述,会显示该数据集的每一位患者收集了哪些变量。点击「在线申请」菜单,就可以在线提交数据申请表单了。

目前基于该数据库已经发表了很多 SCI 论文,比如研究青少年腰围与呼吸功能相关性(Respirology. 2012 Oct;17(7):1114-8),研究北方人群前期高血压和糖尿病的流行病学研究。这些研究都离不开大数据的支持,而只有政府层面上给予支持才能完成如此大规模的研究。
以前这些数据都是不公开的,独享的,因此这样的流行病学研究也就成了少数大型单位的「特权」。
但有了这个数据共享平台后,局面将会改变。任何单位或个人如果有好的研究切入点,都能利用这些数据进行疾病的探索和发现,更充分和有效地挖掘数据。
但目前该数据尚在起步阶段,存在诸多不足。
比如汶川地震的数据集,收集的变量十分有限,大约不足百来个。各种检查治疗,医嘱信息都是缺失的,这对开展危重症方面的研究是一个致命的缺陷。
从这点上看,该数据集和真正的大数据还是有一定差距的。
笔者推测,这些数据应该是手工采集而来,而非通过与医院电子病历整合自动采集而来,而后者应该是未来努力的一个方向。另外里面的一些临床数据集并不是多中心的,而仅仅局限于北京几个大医院,这并不能代表整个中国人口数据特征。
万事开头难,在数据共享方面,此次国家迈出了历史性的一步。对于广大民间屌丝而言,这无疑是一个利好消息。从此大样本的临床科研不再是北上广大医院的专属特权,数据的获取已不再是一个壁垒。
中国的临床研究将进入春秋战国时代,百家争鸣,百花齐放,群雄逐鹿,而竞争的核心就在于谁掌握了大数据分析能力。
不管怎么说,国家这次出了一个大招,中国的临床研究会不会进入一个井喷时代?该如何有效利用这个数据库?
笔者与丁香园开设《临床大数据的获取、分析与处理》实操课,教你如何获取和分析医疗大数据进行临床研究,发表 SCI 论文。

长按识别二维码直达课程页面
课程全部使用 R 语言进行讲解,每种数据处理方法均采用数据模拟创造临床研究情境,然后针对该问题进行数据挖掘实战演示。
本课程可以帮助你系统学习数据分析并加以实践。
作者:章仲恒,浙江大学医学院附属邵逸夫医院急诊科。加拿大呼吸杂志(CRJ)客座编辑,Lancet respiratory medicine (IF=15),Intensive care medicine(IF=10)等杂志审稿人,第一作者发表 SCI 论文 40 篇。
图片来源:国家人口与健康科学数据共享平台









