(点击
上方公众号
,可快速关注)
作者:伯乐在线 - Rings
如有好文章投稿,请点击 → 这里了解详情
#0. 所需预备知识
诸位需要对于PostgreSQL中的存储方式有一个初步的了解。了解元组,页等术语所描述的含义。虽然这些术语不是必须知道,但是对于这些术语的了解有助于对应PostgreSQL存储方式的了解。
#1. PostgreSQL如何存储数据
PostgreSQL中数据是按照页的形式组织,一个页的大小通常为8K。在数据表创建的过程中创建相应的数据文件,而这些数据文件就是我们通常所说的表中数据所存放的位置。
正如数据库功能所描述的一样,通过以一种合理的方式将数据保存至非易失设备上,并提供某类方式来快速的查询出所保存的数据。这也是数据库原理的一种朴素的解释。当然,数据库在实现的过程中并非如上述我们所给出的一句话可以解释清楚。
一个可使用的数据库系统,工程上应该包括:服务器框架部分:该部分管理用户请求连接,为用户提供使用数据库服务提供接口;存储引擎:用来完成与文件系统的之间的操作,将用户所需要保存的数据按照一定的形式组织起来,并将其保存至非易失设备中;查询/执行引擎:负责将所保存的数据以一种快速且高效的方式获取并将其展现给用户。其它模块:例如:元数据管理等,在此就不在详细讨论了。
在上一段中,我们曾提及,PostgreSQL中数据文件是以Page的方式存储的。那么下面我们首先来给出一个Page的Layout。
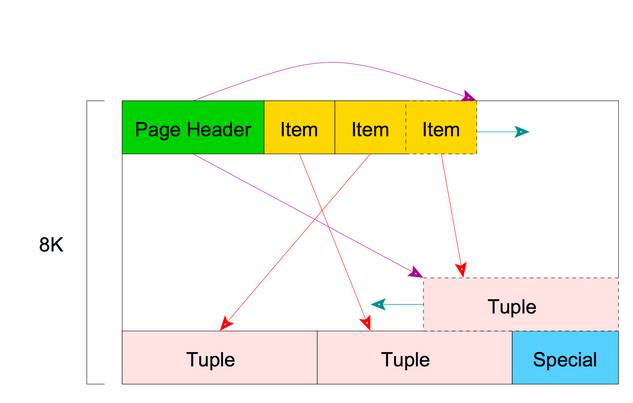
我们曾在另一篇文章中从整体架构上讨论了PostgreSQL的数据存储相关知识[…]该文章中我们讨论了Page构成的详细说明。并讨论了PageHeaderData,HeapTupleHeaderData,HeapTupleData等数据结构。在此文章中,我们从理解层面讨论了存储层的相关知识,而本文中我们从程序层面来讨论,如何将数据组装成特定Page形式并讨论如何在代码层实现存储。
在进行后续的介绍之前,我们首先来看看除了PostgreSQL外,SQL Server以及Oracle中的一行记录的相关格式。首先,我们来看看Sql server的Row Format:
其每个记录行由五部分构成:(1)用来描述该行记录的头部信息;(2)不变数据(固定长度的数据类型,例如:int, double等等);(3)NULL值的位图信息,由于NULL值在数据库中属于一个特别的数据类型,其与空有着区别,因此在保存该NULL值的时候,为了能够节省存储空间我们并不是保存一个特殊的值(因为无论我们使用何种方式,即使最小的使用1 bit来表示,当数据量巨大时,也会造成存储空间的增长),例如:INF或是其它值来标识,而是使用一个NULL位图信息来描述该行记录中NULL值所在的位置。同样,在PostgreSQL中,我们也使用相同的方式来描述NULL在一条记录中的相关信息,在HeaptTupleHeader中的t_bits就描述了该条记录(Tuple)中NULL值的分布情况;(4)可变数据,由于我们在支持类似于string, varchar, varchar2, text等可变长度的数据,正是由于这些数据长度的不确定性,使得我们将这些需要对此类的数据做特殊的处理(通常是记录该数据的真实长度)。读者可以思考一下,为什么SQL-Server会将可以长度的数据放在该记录的最后一部分,该种方式下,有何有点(提示:可以从存储引擎的特定出发,由于存储引擎的设计到数据的存储和读取,且由于数据库的特点,任何单条记录存取空间或者效率的改进都将会极大的影响整个数据库系统的性能)。(5)版本信息(可选)。


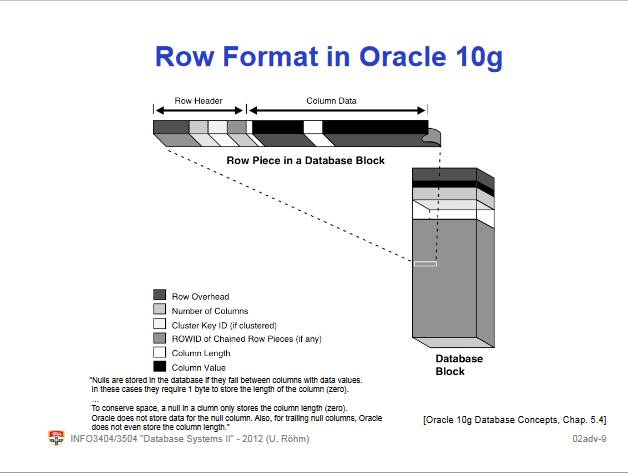

相关的上述关于sql-server以及oracle的row格式的相关资料均来自于Sydney University[…]
由上述PostgreSQL,SQL-Server以及Oracle的row的数据格式可以看出,无论哪种类型的数据库,都需要对于变长数据类型和NULL数据类型进行额外的处理,当然前提条件是数据库系统需要支持着两种类型的数据类型,当然我们无法想象一个不支持变长数据类型和NULL型数据类型的数据库是如何存在与市场中。PostgreSQL为了支持NULL类型,在HeapTupleHeaderData数据结构中使用t_bits来描述该tuple中的NULL属性的相关信息。
我们知道,heap_form_tuple函数为,PostgreSQL中构成一个Tuple组装函数。有该函数的如下原型:
HeapTuple heap_form_tuple(TupleDesc tupleDescriptor, Datum *values,bool *isnull)
我们可以知道,该函数以Datum*类型的数据values为基础并按isnull数组中所描述的一行数据中为NULL的属性数据。 从heap_form_tuple函数中,我们可以有一个问题:为什么会在 heap_form_tuple 函数中,首先技术heaptupleheaderdata时候,只是偏移到t_bits,而非是使用sizeof (heaptupleheaderdata)来计算呢?
len = offsetof(HeapTupleHeaderData, t_bits);
我们知道,对于t_bits来说其描述了NULL的bitmap关系,由于其是与列(属性)个数有关,因此其长度是一个可变的值,而这也是为什么t_bits在heaptupleheaderdata中的定义是一个uint8 t_bits[1]这样一个形式;
在计算完heaptupleheaderdata的长度时候,我们便根据是否存在着null列,来计算相应的数据。
if
(hasnull)
len
+=
BITMAPLEN(numberOfAttributes);
以及是否存在着tuple oid信息。
if
(tupleDescriptor-
>
tdhasoid)
len
+=
sizeof(Oid);
再加上padding大小 hoff = len = MAXALIGN(len); /* align user data safely */
最后加上数据的长度:
data_len
=
heap_compute_data_size(tupleDescriptor,
values
,
isnull










