允中 编译自 blog.openai.com
量子位 出品 | 公众号 QbitAI
OpenAI今天发布一类新的强化学习算法:近端策略优化(Proximal Policy Optimization,PPO)。因为易于使用和表现良好,PPO已经成为OpenAI默认的强化学习算法。
PPO让我们在根据挑战性的环境中训练AI策略,例如上面所示的Roboschool训练场中,智能体(agent)的任务是追逐粉红色的球体,并在期间学习走路、跑步、转向以及被击倒时如何站起来。
代码在此:
https://github.com/openai/baselines
Paper在此:
https://openai-public.s3-us-west-2.amazonaws.com/blog/2017-07/ppo/ppo-arxiv.pdf
最近在使用深度神经网络控制视频游戏等领域取得的突破中,策略梯度方法扮演了基础的角色。但策略梯度方法想要获得良好的结果非常困难,因为它对步长的选择比较敏感——太小。而且过程慢得让人绝望。样本效率通常也不好。
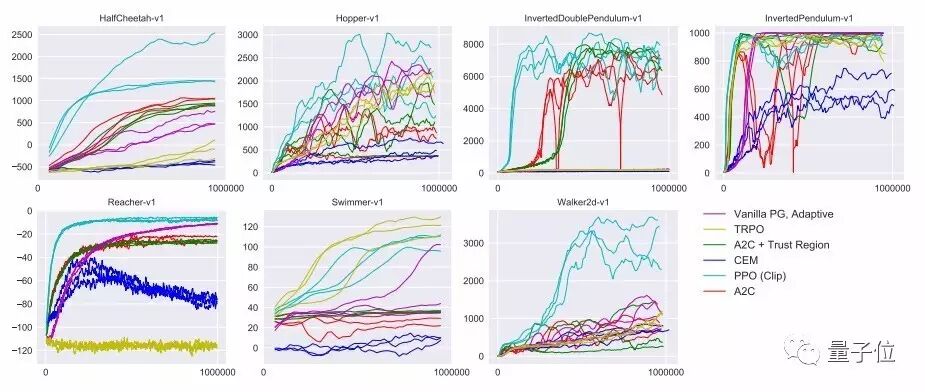
通过监督学习,我们可以轻松实现成本函数,运行梯度下降,而且很有信心能通过相对较小的超参数调优获得出色的结果。强化算法的成功路径并不明显,算法里有很多难以调试的部分。PPO则在样本复杂性和易于调优之间取得平衡,试图在每一步最小化成本函数计算更新时,确保与先前策略的偏差相对较小。
我们详细说明了使用自适应KL惩罚来控制每次迭代策略变化的PPO变体。新的变体使用其他算法中通常没有的新目标函数:

该目标实现了一种与随机梯度下降兼容的信赖域修正方法,并通过消除KL损失来简化算法,以及减小适应性修正的需求。在测试中,这一算法在连续控制任务上显示出最佳性能,几乎与ACER在Atari上的性能相匹配,而且实现起来更为简单。
OpenAI还使用PPO来教导复杂的模拟机器人。
例如波士顿动力的Atlas。这个模型具有30个不同的关节,普通的双足机器人只有17个左右。研究人员利用PPO训练模拟机器人,在越过障碍物时表现出跑酷的感觉。(不过在这个演示视频中,没有感觉出来……)
基线:PPO和TRPO
这一次放出的基线版本包括PPO和TRPO的可扩展并行实现,它们都是用MPI进行数据传递。两者都是用Python3和TensorFlow。
OpenAI基线是一套强化学习算法的高质量实现。地址在:https://github.com/openai/baselines
可以直接输入下面这个命令安装:
pip install baselines
【完】
交流沟通
量子位读者6群开启,对人工智能感兴趣的朋友,欢迎加量子位小助手的微信qbitbot2,申请入群,一起探讨AI。
想要更深一步的交流?
量子位还有
自动驾驶
、
NLP
、
CV
、
机器学习
等专业讨论群,
仅接纳相应领域的
一线工程师、研究人员等
。
同样需要添加qbitbot2为微信好友,提交相应说明,符合条件后将被邀请入群。
(审核较严,敬请谅解)
诚挚招聘
量子位正在招募
编辑/记者
等岗位,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。
△
扫码强行关注『量子位』
追踪人工智能领域最劲内容





